

はじめに
こんにちは、アナリティクスサービス部の加茂です。
2023年1月末まで開催されていたKaggleのOTTOコンペに社内の5名(加茂、藤本、天利、皆本、尾村)でチームを組み参加しました。最終的に2,587チーム中38位で銀メダルの成績でした。
今回はこのコンぺを題材に、レコメンドタスクの一般的なアプローチについてご紹介しようと思います。
コンペの内容
概要
ドイツのECサイトを運営する会社OTTOが主催したレコメンドタスクのコンペであり、2022/11/1 ~ 2023/1/31にかけて開催されていました。
ECサイトのアクセスログから、ユーザが将来クリック、カート投入、注文しそうな商品を予測・レコメンドし、その精度を競うという内容でした。
データ
与えられたデータはカラムが4列のみの極めてシンプルなテーブルデータでした。

各カラムの意味合いは次の通りです。
- session:セッション≒ユーザー
- aid:商品ID
- ts:時刻
- type:行動の種類(アクション)をしたかを表すデータです。裏を返せばそれ以外の周辺情報は分からず、レコメンドのコンペではありがちなユーザの属性情報(年齢・性別など)や、商品の情報(カテゴリや価格など)は利用できませんでした。
また、商品の種類が180万近くあり、かなり多いというのも特徴の1つだったと思います。
評価指標
本コンペの評価指標 (OTTO – Multi-Objective Recommender System より)
基本的にはrecall@20という指標です。つまり、20商品を予測として出し、正解のうちいくつ当てることができたかを表します。
今回はクリックする・カート投入・注文をするの各アクションに対して商品を予測し、それぞれに対してrecall@20を計算し重み付き平均で最終的なスコアが算出されます。
特にカート投入・注文するの2つで0.3+0.6=0.9の重みとなっており、まずはこの2つの精度を上げることが重要でした。
アプローチの全体感
ここから商品を予測する方法をご説明していきます。
推薦タスクのアプローチでは、候補作成パート(Recall partなどとも呼ばれる) とリランキングパートの大きく2段階を経て商品を絞り込むことが一般的です。今回のデータの場合、あるユーザにレコメンドする20商品をいきなり絞り込むのではなく、最初に候補作成パートで多めの商品数(例えば100商品)を確保し、次にリランキングパートでその100商品を順位づけし上位20商品を得る、という流れをとります。

このような手順を踏む理由の1つは、1ユーザに対するリランキングパートでの商品数が膨大になってしまうためです。愚直に200万人のユーザに対しそれぞれ180万の商品すべてを候補として考えると、その段階で200万×180万=3兆6000億レコードとなり、取り回しが非常に難しい規模感になってしまいます。この問題を避けるため、ルールベースなどの手法を用いてまず各ユーザに対して候補を絞り込むという候補作成の段階を踏んでいます。
候補作成パート
候補作成の方法はさまざまですが、基本となる考え方はユーザが既にアクションを起こしている商品と関連の深い商品を取得する方法です。
ユーザが既にアクションを起こしている商品は再度アクション(過去にクリックした商品を再度確認しやすいなど)をしやすいため、まずは候補に含めます。
しかしユーザによってはログが数件しかなく、その場合は候補数が不十分となるため、ログ外からも商品を候補として取得していきます。そのために、商品と商品の関連度合を表す行列を利用します。この関連度合いを表す行列は一般的には共起行列(co-occurrence matrix)として知られており、こちらもレコメンドタスクではよく使われる手法です。本コンペではco-visitation matrixなどと呼ばれており、同一session内に現れる商品ペアの出現回数カウントして、商品の関連度とするという計算方法が多かった印象です。すなわち、ある2商品がどれほど同一sessionに登場するかを表す行列と解釈できます。

そして、この行列をsession内に出現している商品と紐づけることで新たな商品を候補として取得できます。最後に、行列の重みが大きい順に商品を取得することで、候補を得ることができます。

最終的にこのパートではsession×aidの粒度、つまりユーザとその人へのレコメンド候補商品の粒度となっているテーブルが得られます。
リランキングパート
候補作成パートで得られた商品に順位をつける段階がリランキングパートです。
ここでは機械学習モデルを利用したスコアリング方法について触れていきます。もちろんモデルにもさまざまなものが考えられますが、本コンペでは特にGBDTのランキングモデルがよく使われていたため、ランキングモデルの特徴量作成と学習についてご紹介します。
ランキングモデルはあるリスト(今回は商品リスト)に対して文字通りランク付けをするためのモデルです。今回のような商品レコメンデーションだけでなく、文書検索、ターゲット広告などさまざまな応用先があります。回帰や分類のモデルに対して、サンプル同士の順序関係も考慮して学習してくれる点が一つのメリットとなります。主要なGBDTモデルにはランキング学習の実装があり、例えば、LightGBMの場合こちらのページで説明されています。
また、今回は3種類のアクション対して商品を予測をする必要があり、それぞれ用のモデルを作成している方が多かったためその前提で話を進めます。モデルを分けていた主な理由はデータサイズが大きかったためだと考えられますが、6位の解法のように1つのモデルにまとめている方もおり、精度の観点からするとあまり本質的ではなかったようです。一方で実験のサイクルを回しやすい点では分割していた方が楽だったようにも思います。
まず学習データのラベルを作成します。学習データとしては上述のとおりログデータだけが与えられており、ラベルは各々で作成する必要がありました。とはいいつつ、コンペ主催の方がtestの正解データを作成している方法とそのスクリプトを公表してくださっており、基本的には皆さんこの方法を踏襲していました。簡単に説明すると、4週間分の学習データの場合、最後の1週間をランダムに二分割し後半側をラベルにするという作成方法でした。

このtargetを利用し、sessionとaidの粒度に対して実際にアクションが起こった商品は1、それ以外は0となる二値ラベルを付与するという方法をとっている方が多かったです。このようにラベルを付与することで、ランキングモデルがsession×aidの粒度ごとに0~1付近の値を出力として返してくれます。これをsessionごとに降順に並び替え、上位のaidを出力として得ることで予測結果とします。
次に、session×aidの粒度になっている入力テーブルに対して特徴量を作成していきます。
特徴量は大きく次の3種類が考えられます。
- aid(商品)に関する特徴量
- session (ユーザ)に関する特徴量
- session × aid(ユーザー×候補)に関する特徴量
aid(商品)に関する特徴量は、例えば「全商品の中でその商品がどれくらい注文されているかの割合」や、「クリック数と注文数の比率(≒クリックから注文に繋がりやすいか)」などの商品の人気度合いのようなものや、word2vecなどを利用した商品の特徴ベクトルなどが考えられます。session(ユーザ)に関する特徴量は「そのsession内でアクションがそれぞれ何回発生したか」、「商品の特徴ベクトルを集約したsessionの特徴ベクトル」などが考えられます。session × aid(ユーザー×候補)に関する特徴量はさらに複雑なものを構成でき、精度向上のためにはここがポイントになってきます。例えば、「sessionの最後に現れた商品と候補商品との類似度」をとることで、現在の状態から次にどの商品に行きやすいかという特徴量になります。他にも「候補の商品が既にカート投入されているか」は、入っている場合そのまま注文される確率は高いため、特徴量として重要です。以上のようにして、特徴量作成とラベルの付与を行うと学習用のテーブルが得られます。

最後にモデルを学習していきます。少し細かい話になりますが、GBDTのランキング学習で特徴的な点はgroupパラメータを設定する必要があることだと思います。groupは損失関数を計算する際にサンプル同士の順序関係を考慮するため、どのグループ内でランキングを計算しなければならないのかを明示するためのパラメータです。例えばLightGBMを利用して下の図のような入力テーブルの場合は、 groupのパラメータに [3,2,...] というlist形式でテーブルの上から順にいくつずつが同一ユーザのレコードなのかを指定します。また、このような指定方法をとっているため、同一のユーザは連続したレコードの並びになっていなければいけません。
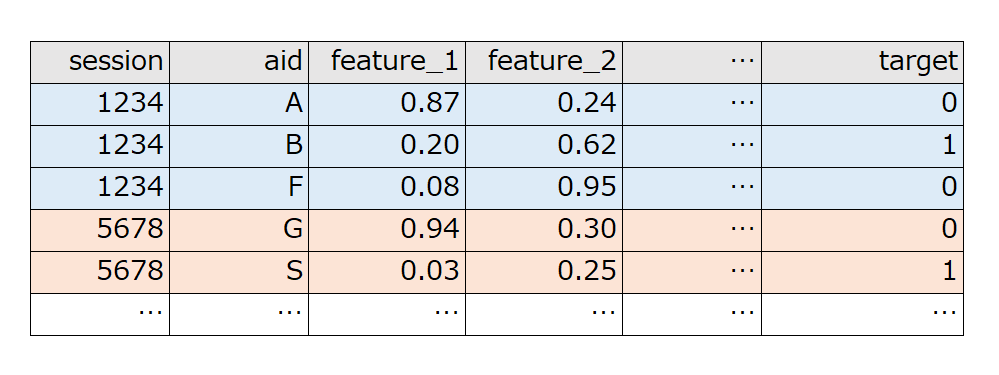
学習時の工夫点として、負例のみのsessionは学習に寄与しないため全て除外しました。これにより余分なデータが削除でき、学習時間、メモリの削減に大きく貢献しました。
また、ランキングモデルのほかにも分類モデルもよく使われていた印象です。しかし、上位の方々の解法を読んだり手元で確認したりする範囲では、今回はランキングモデルの方が精度が良かったようです。
推論
推論は学習までの流れと基本的に同じです。testのユーザに対して候補を生成し、リランクして最終的にレコメンドする商品を決定します。注意点として、trainとtestの期間が異なる場合、特徴量作成に工夫が必要になるということが挙げられます。例えばある商品のクリック数が特徴量になっているとします。学習データの期間は3.5週間程度あるのに対して、推論用のデータの期間は1週間であり、明らかに学習データ側の特徴量の方が大きな値になってしまいます。この場合期間の長さを考慮して数値を調整するか、特徴量算出するための期間の長さを揃える等の工夫が必要になります。
このようにして得られたsessionごとのaidのモデルの出力値でソートし、上位20商品を最終的なレコメンド対象として得られます。
おわりに
最後まで読んでいただきありがとうございました。
本コンペには、ブレインパッドの他の社員も複数名参加しており、コンペ終了後にはどのようなアプローチをしていたかを共有し合い、社内で盛り上がりました。データ量が大きくメモリエラーを回避するための試行錯誤で苦労したコンペでしたが、非常に学びの多いコンペになりました。 与えられたデータが非常にシンプルであるため、本コンペでの知見は汎用性の高いものだったのではないかと思います。
コンペの主催の方々、codeやdiscussionに投稿してくださっていた参加者の方々、そしてチームメイトの皆様、本当にありがとうございました。
最後に、当社では積極的に採用活動を行っています。
ご興味をお持ちいただきましたら、ぜひ採用サイトからエントリ―をお願いいたします!
新卒採用
www.brainpad.co.jp
中途採用
www.brainpad.co.jp