
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
今回は、ツール拡張をテーマに、4つの論文をご紹介します。

目次
- 今回のテーマ
- Lost in the Middle: How Language Models Use Long Contexts
- FacTool: Factuality Detection in Generative AI A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios
- MetaGPT: Meta Programming for Multi-Agent Collaborative Framework
- ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
- まとめ
こんにちは。データエンジニアリングユニット所属の濵田です。
前回の記事にもあるように、現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
第3回となる今回は、その中でも、ツール拡張のトピックで取り上げた4つの論文についてご紹介します。
今回のテーマ
LLMにツールを使用する能力を獲得させることで、単純な自然言語の応答だけでは実現できない、様々なタスクをLLMに実行させることができるようになることが期待されています。現在最も利用されている応用先の一つとして、Retrieval-Augmented Generation(RAG)などの検索した外部情報を利用した回答の生成が挙げられます。また検索のような単純なツールの利用だけにとどまらず、コードの実行能力やAPIの使用能力などより実用性の高い能力を備えたアプリなどが開発されています。一方で、ツールを使用するかどうかの判断や他のエージェントとのコラボレーションなど、自律して動作するLLMの研究も盛んに行われています。今回のテーマでは、RAGなどのツール拡張やエージェントへの応用などを取り扱った最新の技術論文を4本ほど紹介します。
Lost in the Middle: How Language Models Use Long Contexts
選定理由
Retrieval-Augmented Generation (RAG)など外部情報をコンテキストに入力する手法は、最もよく利用されるLLMアプリケーションの一つになっています。
1つ目は、コンテキストへの外部情報の入力方法やモデルのコンテキスト長がQAタスクの回答精度にどのように影響するかを調査した論文を紹介します。
論文概要
- 最近の大規模言語モデルが長いコンテキストを入力として受け取る能力はあるが、その長いコンテキストをどの程度効果的に利用できているかについて調査した論文。
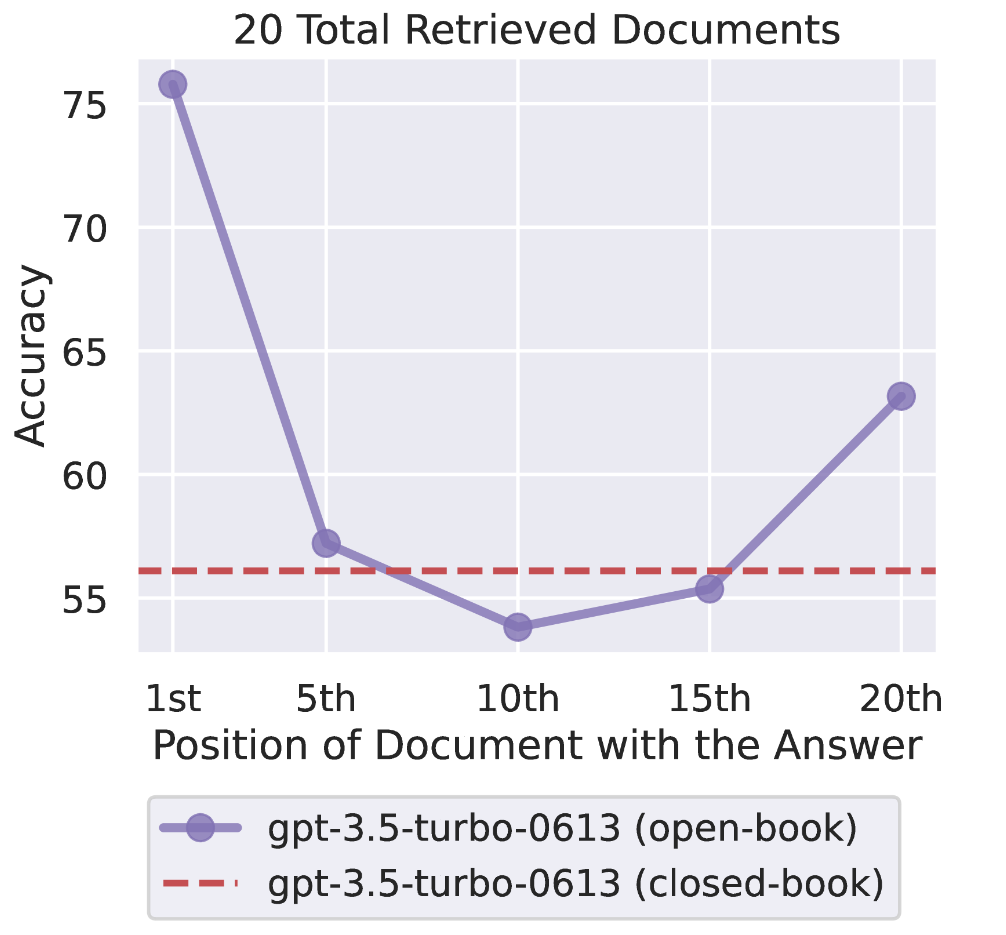
- モデルのパフォーマンスは、関連情報が入力コンテキストの始めや終わりにあるときが最も高く、中ほどにあるときは著しく低下する。
- 入力コンテキストが長くなるにつれて、モデルのパフォーマンスは着実に低下し、コンテキスト長の長いモデルが、必ずしもその長いコンテキストをより効果的に利用できているわけではない。
論文では言語モデルが入力コンテキストをどのように使用するかをより深く理解するため、複数ドキュメントの質問応答に関するモデルのパフォーマンスを分析を行っています。
どうやって入力コンテキストをどのように使用するか調べたの?
実験では、モデルは入力コンテキスト内に回答を含むドキュメントにアクセスして、それを使用して質問に正しく回答できるかどうかが正解率として評価しています。モデルには答える質問と 個のドキュメントが入力され、ドキュメントの1つは質問に対する回答が含まれており、残りの
個のドキュメントは回答の含まれないものになります。本論文では、入力する関連ドキュメントの数
と質問に対する回答を含むドキュメントの入力位置がどのようにパフォーマンスに影響するかを調べるため、条件を変更しながらモデルのパフォーマンスの分析を行っています。
① 入力する関連ドキュメントの数 :
ドキュメントの数が増えてコンテキストが長くなると、モデルのパフォーマンスが低下する。
② 質問に対する回答を含むドキュメントの入力位置 :
関連情報が入力コンテキストの始めや終わりにあるときが正答率が最も高く、中程にあるとき著しく低下する。
つまり言語モデルは入力コンテキスト全体を使用するのは苦労しており、特に長いコンテキストの途中で出現する関連情報へアクセスする能力が低いことを示しています。またモデルに含まれるバイアスの影響を示唆する結果も得られています。
③ Instruction Tuningの効果
Instruction Tuningされたモデルを使用することで、関連する情報が中程に現れる場合でもパフォーマンスの劣化が抑えられ、ロバストとなる傾向が見られた。これは元の言語モデルは直近のトークンに参照する recency bias が強く働いているが、Instruction Tuningすることでより長い範囲の情報を使用できるようになったと考察されている。
結局コンテキストが長いほどいいのか?
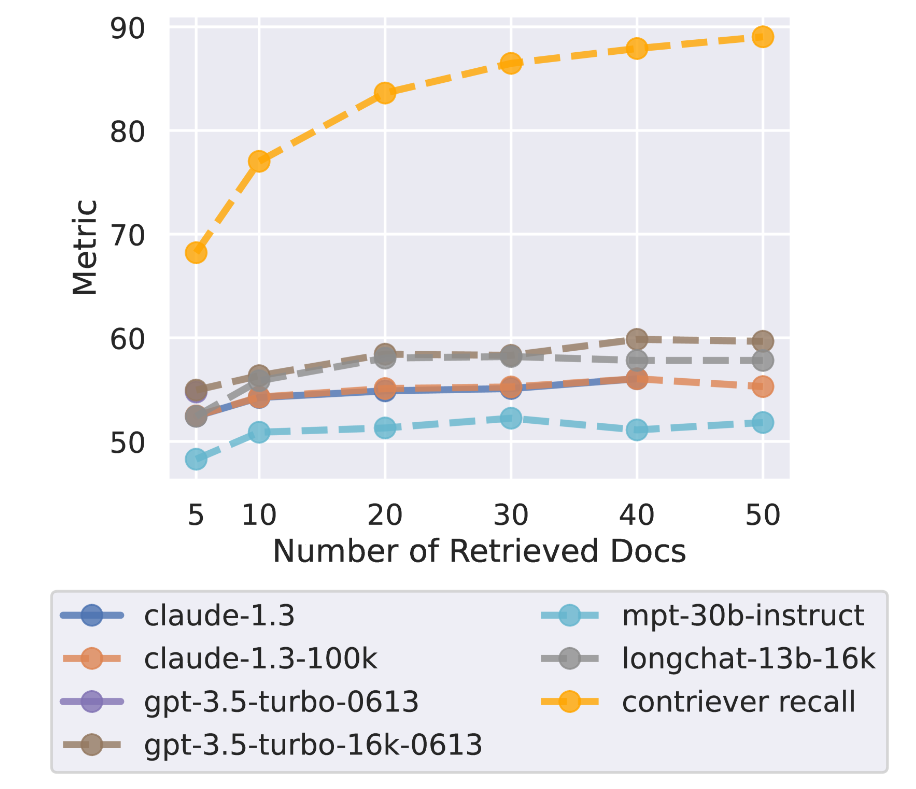
レトリーバーが正しい情報を持ってくる精度が低いなら、正しい回答を出力するためには多くのコンテキストを入れる必要があります。しかしレトリーバーの精度が頭打ちにならない20個程度のドキュメント入力において、どのモデルでもQAタスクの正答率が頭打ちになってしまう結果が得られています。そのため、長いコンテキスト長のモデルを使用すればQAタスクの正答率が上がるわけではないと考えられます。論文では関連の低いドキュメントの切り捨てや関連度に応じた並び替えが有効であるとしています。
レビュー会FB
Q: Attentionを考えると位置情報を見て推論してなさそうなのに原因は何か?
- モデルアーキテクチャは位置情報に対してのバイアスは含まれていないので、学習データ自体に依存している可能性が高い。
- 実際にInstruction Tuningすると中程の情報へのアクセス性能が上がることからも上記の推定は正しいと思われる。
- そのため中程に関連情報が現れる場合でも同程度のパフォーマンスを得たければ、ファインチューニングを行うのは有効だと考えられる。
Q: どれくらいのトークンの長さからだと劣化が顕著に現れるのか?
- トークンの長さというよりも、入力するドキュメントの数は少ないほどパフォーマンスは高くなる。言い換えれば、回答を含まない「気を散らす」ドキュメントが少ないほうがパフォーマンスを上げやすい。
- 一方で正解を含むドキュメントがコンテキストに含まれていれば、モデルのコンテキスト長が変わってもパフォーマンスは殆ど変わらないようです。
関連論文
| タイトル | 概要 |
|---|---|
| Long-range Language Modeling with Self-retrieval | 検索拡張用に長いコンテキスト長を獲得できるようにアルゴリズムを改良したモデル |
FacTool: Factuality Detection in Generative AI A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios
選定理由
RAGなど外部情報を使用する手法やドメインのデータセットで事前学習したモデルにより高品質のテキスト合成が可能になったが、アプリケーションとして展開するにはハルシネーションなど事実と異なる回答を生成するケースへの対応が必須になります。2つ目の論文では、事実誤認を検知する最新のフレームワークについて紹介します。
論文概要
- 大規模言語モデル(LLM)によって生成されたテキストの事実誤認を検知のための汎用的フレームワーク「FacTool」を提案
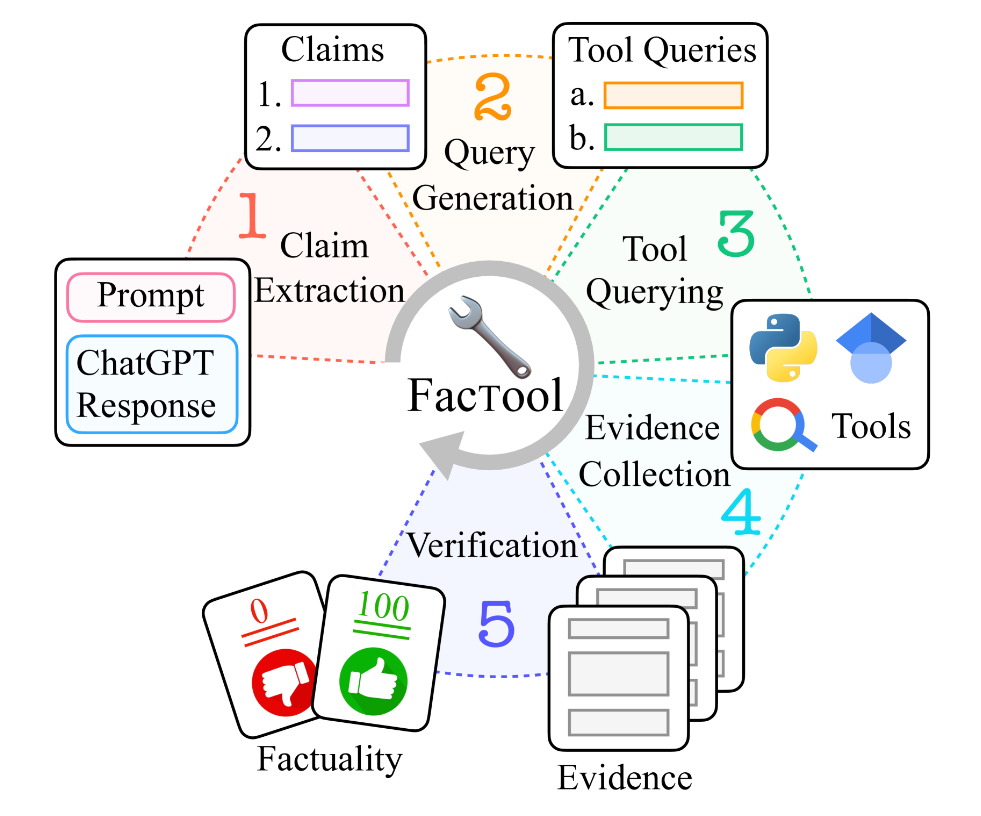
- 「クレーム抽出」、「クエリ生成」、「ツール検索」、「証拠収集」、「一致確認」の5つのステップで事実誤認を検知する
- 質問応答・コード生成・数学問題解決・論文レビュー生成の4つのタスクで、高い精度で事実誤認を検知可能であると実験的に示した
課題背景
LLMは高品質なテキスト合成を行うことができるが、事実誤認を含むという課題を抱えています。生成されたテキストは長くなる傾向があり、個々の事実について明確に定義された細かい粒度での事実確認が必要になります。これまでの研究では、以下のような課題がありました。
① 様々なタスク・ドメインに対応できるフレームワークがない
RAGやテキスト要約など単一のタスクやドメインに焦点を当てた検証しか行われていない。
② 単純な事実誤認検出方法
これまでの研究では、(1)クレームが与えられ、それが事実として正しいかどうか判断するか、(2)証拠が与えられ、生成されたクレームが指示されるかどうか判断するかのいずれかで実装されている。しかしこれらの方法では、長い合成テキストの事実誤認の検証には適していない。
提案手法
この論文ではLLMで生成されたテキストの事実誤認を検出することを目的として、タスクとドメインに依存しないフレームワーク「FacTool」を提案しています。以下の5つのステップで構成されます。
① クレーム抽出
LLM生成テキストから、タスクごとに設定された事実検証に必要なきめ細かい粒度でクレームを抽出する
② クエリ生成
抽出されたクレームからキーワードや事実関係を利用して適切な検索クエリを自動生成
③ ツール使用
生成されたクエリを用いて、Google検索やGoogle Scholar、Python Interpreterなどのツールを使用
④ 証拠収集
検索・実行結果からクレームを支持もしくは反証する証拠を収集し、証拠となる文章やデータを抽出する
⑤ 一致確認
収集した証拠に基づきクレームの事実性を確認し、外部知識源と照合することでLLM生成テキストの事実性を評価する
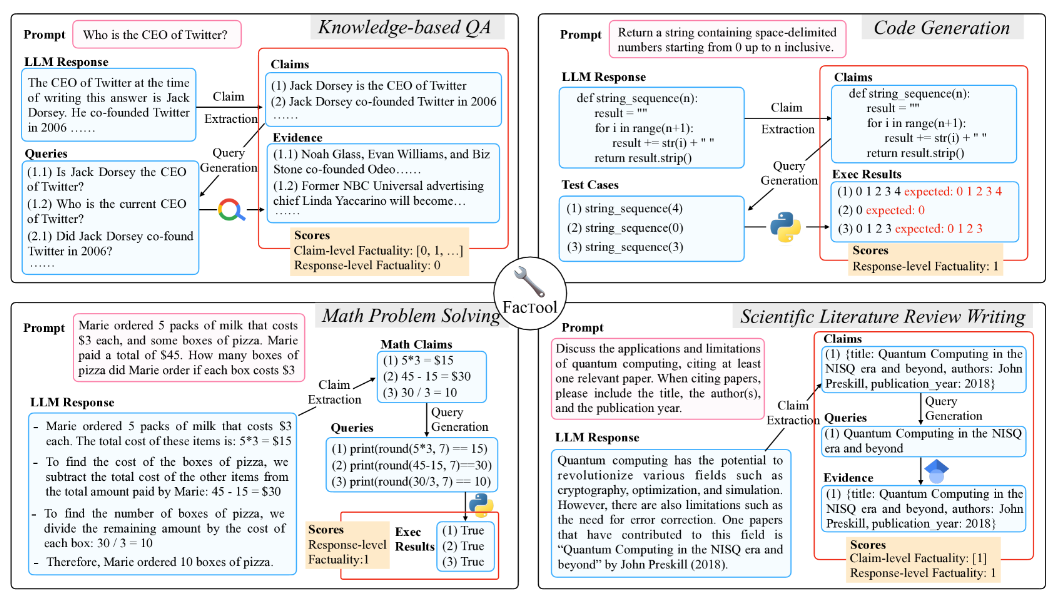
「KBベースのQA」・「コード生成」・「数学問題」・「科学論文レビュー」の4つのタスクで検証を行っており、どのタスクにおいても「GPT-4」を用いたFacToolによる評価が高いパフォーマンスを発揮することが示されています。
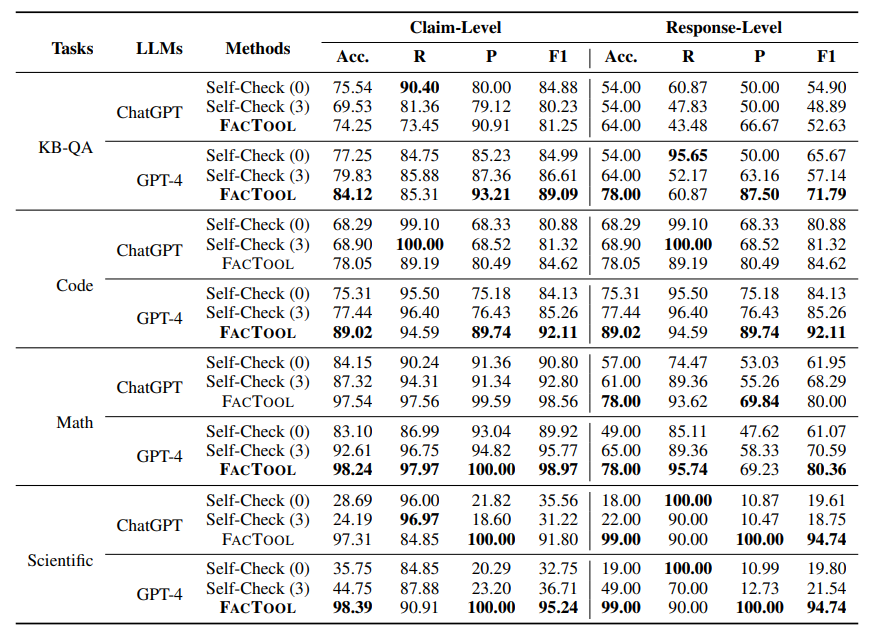
レビュー会FB
Q: FacTool の裏側でどんなLLMを使用しているのか?
- 評価用のモデルとしては、「GPT-4」、「ChatGPT」、「FLAN-T5-XXL」が検証されていたが、「GPT-4」を用いた「FacTool」が最も高い評価パフォーマンスを発揮していた。
- タスク実行モデルとしては、「GPT-4」、「ChatGPT」、「Bard」、「Claude-v1」、「Vicuna-13B」が検証されているが、GPT-4がほぼすべてのシナリオで高い事実性を備えていることが確認されていました。
Q: タスクに応じて検証方法は変えているのか?
- あくまで統一的に扱えるフレームワークというだけで、クレームの抽出やツール使用などの設定はタスクにより変えているようです。
関連論文
| タイトル | 概要 |
|---|---|
| Self-Refine: Iterative Refinement with Self-Feedback | FacToolの比較用のベースラインとして使用したCoTベースの自己評価方法。対話応答、数学的推論、コード生成などのさまざまなタスクに効果的であることが示されている。 |
| Survey of Hallucination in Natural Language Generation | NLGにおけるHallucination問題についてまとめたサーベイ論文。 |
MetaGPT: Meta Programming for Multi-Agent Collaborative Framework
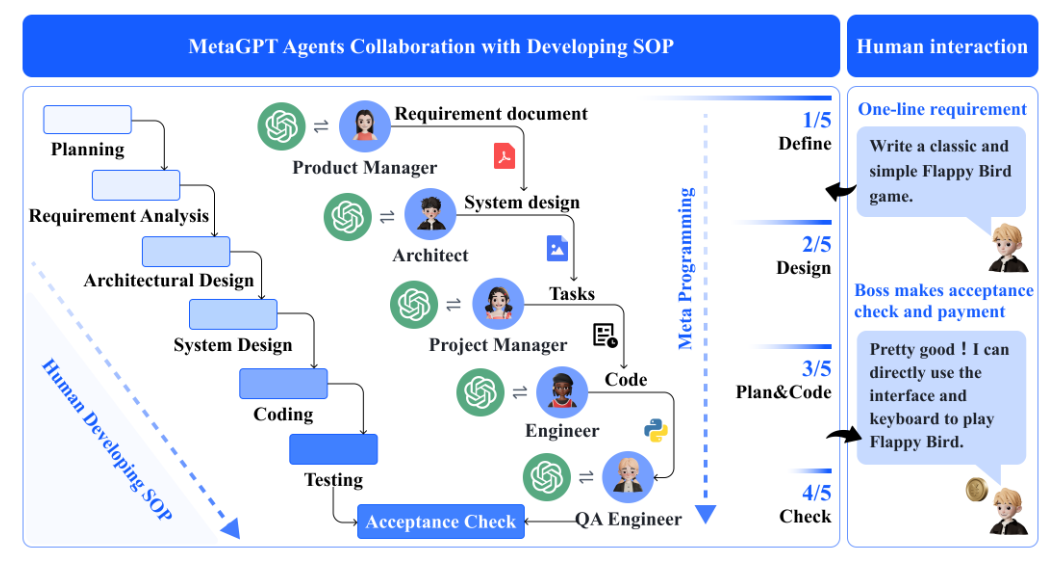
選定理由
LLMにツールの使用能力を与えるだけでなく、複数のエージェントをコラボレーションさせることで、より複雑な問題な対処させる研究も進んでいます。3本目は、ハルシネーションへ対処できるように標準作業手順(SOP)を組み込んだ「MetaGPT」という方法について紹介します。
論文概要
- 標準作業手順(SOP)を用いてLLMベースの多エージェントを調整するメタプログラミング技術を用いた、LLMベースのマルチエージェントシステムであるMetaGPTというフレームワークを提案。
- ロール定義、タスク分解、プロセス標準化などを通して、SOPをプロンプトにエンコードすることで、ソフトウェア開発の例では、MetaGPTが1行の要求からエンドツーエンドの開発プロセスを完了できることを示しています。
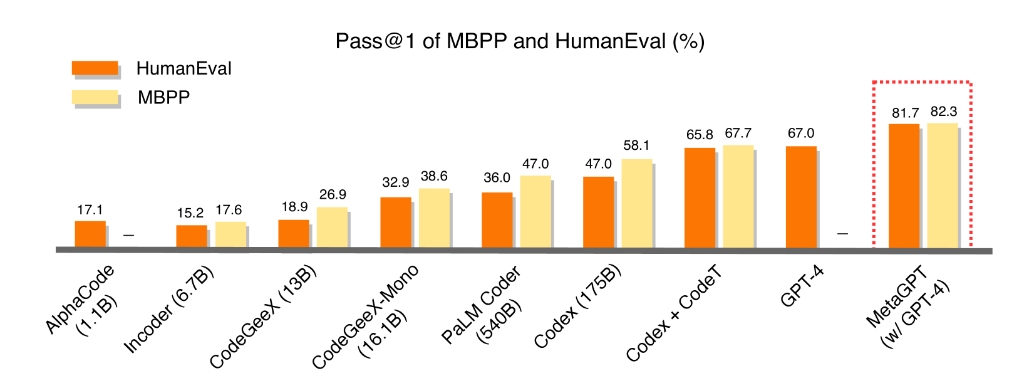
- HumanEvalとMBPPのベンチマークで、MetaGPTはdirect methodsよりも遥かに高い精度(Pass@1)を達成しています。
課題背景
LLMベースのマルチエージェント作業は、単純な対話タスクを解決することに焦点が当てられている。これはLLMの持つハルシネーションがタスク上流で発生すると、連鎖的に発生し、対処できなくなってしまうため、複雑なワークフローのタスクへの対応はほとんど研究されていませんでした。この論文では標準作業手順(SOP)をプロンプトにエンコードすることで、人間のワークフローをマルチエージェントコラボレーションへ組み込む革新的なフレームワークである「MetaGPT」を導入しています。
MetaGPTのコアメカニズム
以下のコアメカニズムを元に、SOPに沿った「アンカーエージェント」がインスタンス化されたエージェントが派遣される。派遣されたエージェント同士はコラボレーションして不雑なタスクを実行する。
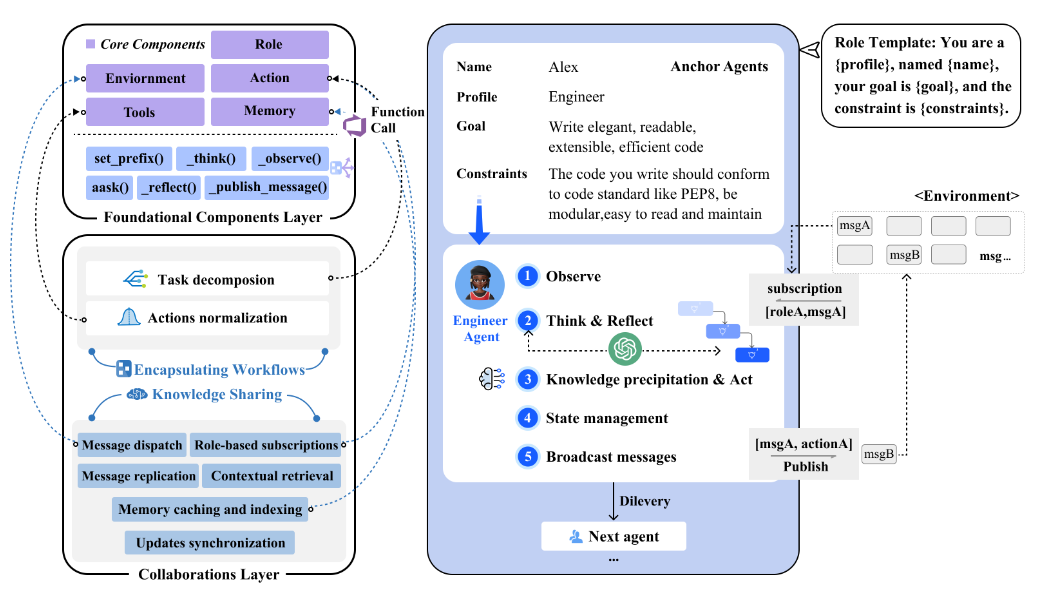
基礎コンポーネントレイヤー
環境、メモリ、ロール、アクション、ツールなど、個々のエージェントの操作とシステム全体の情報交換に必要なコア構成要素を確立します。実行時はSOPに沿ってインスタンス化されたエージェントが派遣されます。
コラボレーションレイヤー
複雑な問題を協力して解決するために、知識の共有やワークフローのカプセル化を通して、個々のエージェントの調整を行う。
MetaGPTの実験結果
ソフトウェア開発のSOPに沿って、「プロダクトマネージャ」、「アーキテクト」、「プロジェクトマネージャ」、「エンジニア」、「QAエンジニア」の5つのロールを設定することで、MetaGPT は「Make the 2048 sliding tile nubmer puzzle game」という要求から開発プロセスを完了できることが示されている。その他にも「Tank Battle Game」や「Excel data process」、「CRUD manage」など複数の複雑なタスクで実行可能性が示されている。
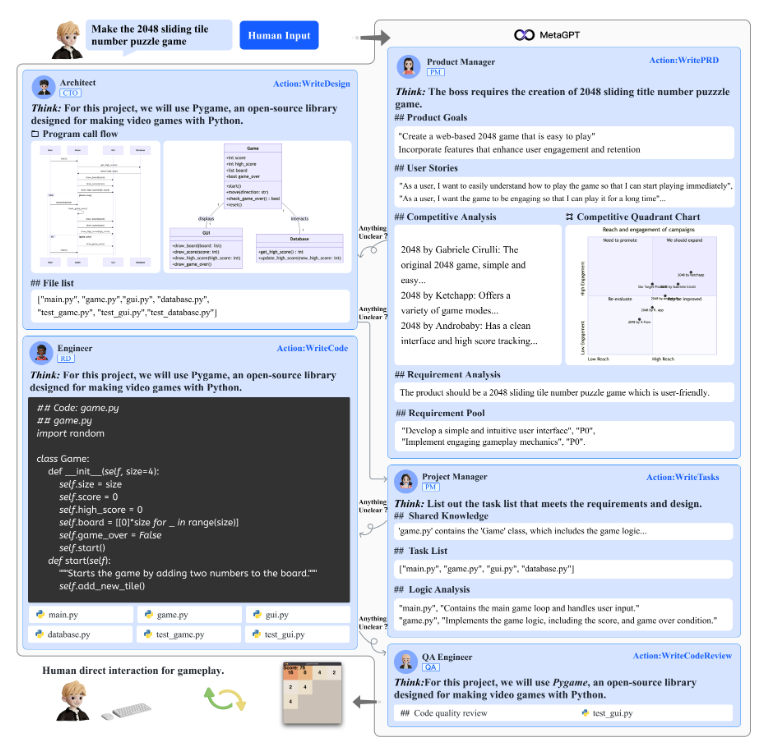
また一般的なコード生成ベンチマークにおいても、既存のGPT-4を用いた直接的なアプローチよりも、MetaGPTは遥かに高い合格率を達成できている。
レビュー会FB
Q: 人間とのコラボレーションは言及されているか?
- この論文ではマルチエージェント間のコラボレーションについて言及されているが、人とのコラボレーションについてはスコープ外のようです。
- ただLLMがボトルネックになる役割やサブタスクを人がサポートすることで、全体的な精度を上げる方法は有り得るかも。
関連論文
| タイトル | 概要 |
|---|---|
| Generative Agents: Interactive Simulacra of Human Behavior | 人間の行動をシミュレーションするマルチエージェントの先行研究として紹介。 |
| AutoGPT | 既存の自律システムの一つとして紹介。一貫性と検証に関する課題に直面しながら、高レベルの目標を複数のサブ目標に分割し、ReAct スタイルのループで実行することでタスクを自動化している。 |
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
選定理由
LLMにツールの利用能力の拡張は、様々なアプリケーションへLLMを展開する上で非常に注目されている技術となっています。4本目は、LLM内の公開されているAPIを利用能力を引き出す研究である「ToolLLM」について紹介します。
論文概要
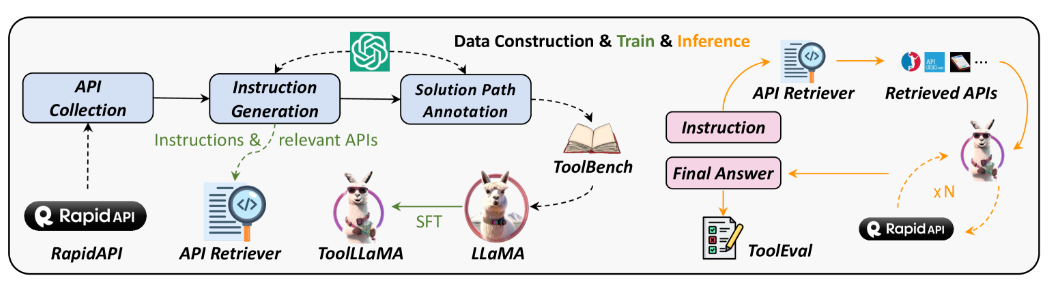
- 単一ツール及びマルチツールのユースケースを含む 16,000以上の実際のAPIを利用するインストラクションデータセット ToolBenchを、ChatGPTを用いて自動的に構築
- ソリューションパスのアノテーションを効率的に行うため、新しい意思決定戦略として決定木による深さ優先探索 DFSDT を提案し、広い探索空間と複数の推論パスの評価ができるように拡張した
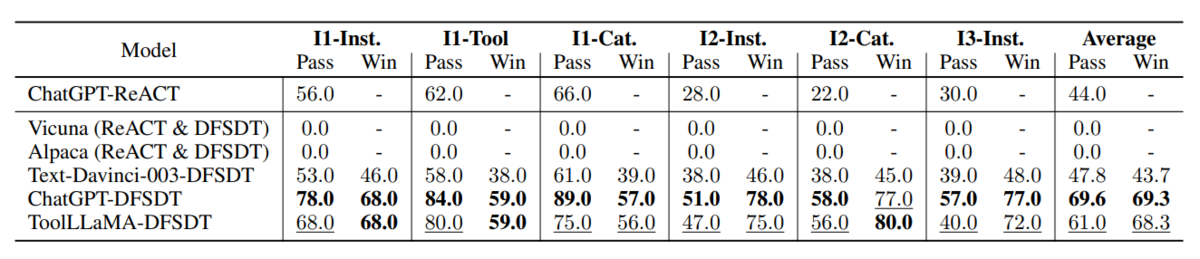
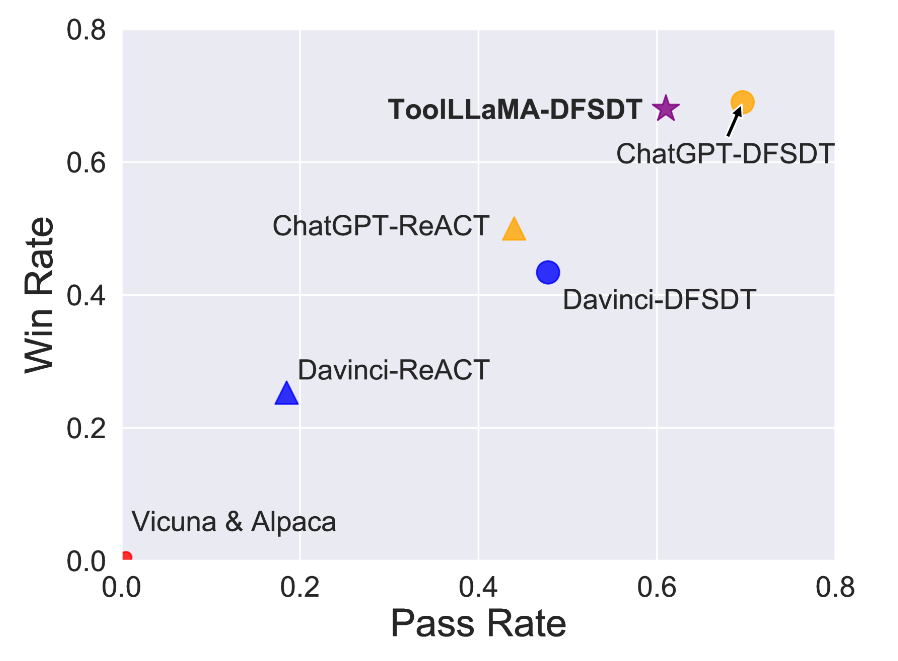
- ToolBenchによりファインチューニングされたLLaMAは、マルチツールを利用する複雑なタスクや未知のツールを利用するタスクにも対応可能で、ChatGPTと同等のパフォーマンスを発揮した
課題背景
ここ最近でLLMは大幅に進歩しましたが、悪魔で言語タスクに焦点を当ててチューニングされているもののため、外部ツールを使用するための人間の指示に従うなど、より高レベルのタスクの実行には依然として大幅な制限がありました。またLLMにAPIの使用能力を獲得させる研究においても以下のような課題が見られていました。
① 多様性に乏しい狭い範囲のAPIしか利用できない
② 一つのツールのみを使用する単純なシナリオしか想定していない
③ 計画と推論能力が劣っており、複雑な指示を処理できない
提案手法
これらの課題を克服するため、この論文では以下の取り組みを行いました。
① API使用のための高品質のインストラクションチューニングデータセット「ToolBench」の構築
- RapidAPIに登録されている16,000以上のAPIとそのドキュメントを利用
- 単一ツールだけでなく、マルチツール利用など複雑なユースケースシナリオを含むインストラクションデータセットをChatGPTで自動構築
② 深さ優先探索ベースの決定木(DFSDT)によるソリューションパスの決定
- LLMの計画と推論能力を強化するため、有望なソリューションパスを探索できるように、広い探索空間と複数の推論パスの評価を行える DFSDT を開発
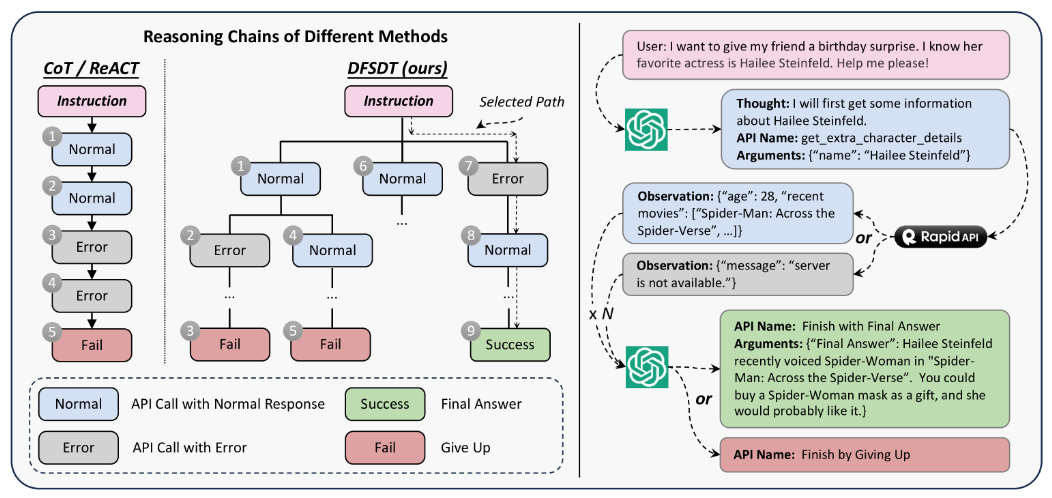
またToolBenchを用いてLLaMAをファインチューニングすることで、マルチツールを利用する複雑なタスクや未知のツールを利用するタスクにも対応可能なToolLLaMAの開発に成功しており、ChatGPTのAPI利用能力と同程度のパフォーマンスを発揮しています。
レビュー会FB
Q: 使うべきAPIは自分で探索するのか?
- インストラクションで使用するAPI自体は、レトリーバー用のファインチューニングされたSentence-BERTを使用。
- 候補となるAPIの中からソリューションパスを探索する方法は、ChatGPTによる深さ優先探索を行っている。
Q: ソリューションパスの推論は実際にAPIを実行しているのか?
- 深さ優先探索実行時にステップごとにAPIの実行を行っています。
- そのため、探索回数が多くなると、複数回ChatGPTとの会話やAPI実行を行うため、計算コストや時間がかかってしまいます。
関連論文
| タイトル | 概要 |
|---|---|
| Gorilla: Large Language Model Connected with Massive APIs | 多くのAPIに対応したモデルであったが、APIの多様性に乏しく、汎用性に疑問 |
| ReAct: Synergizing Reasoning and Acting in Language Models | LLM が行動について適切な理由を与えることを許可し、推論に環境フィードバックを組み込むことによって、推論と行動をより適切に統合することを提案した論文。本手法の比較用のベースラインとして紹介。 |
| Tree of Thoughts: Deliberate Problem Solving with Large Language Models | ToolLLMと同じく思考の計画と推論に決定木構造を利用することを提案する論文。 |
まとめ
今回はRAGやAgentなどLLMのツール拡張に関する技術論文を4つ紹介させていただきました。今後も、社内で実施しているレビュー会での発表内容をブログで発信させていただくつもりですので、ご期待ください。