
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
現在は、週に1回程度の頻度で、社内で実施している生成AI・LLMに関する論文レビュー会の内容をピックアップのうえ配信しています。
今回は、LLMの性能改善に関連して、4つの論文をご紹介させていただきます。

- 論文選定基準
- From Pretraining Data to Language Models to Downstream Tasks:Tracking the Trails of Political Biases Leading to Unfair NLP Models
- Universal and Transferable Adversarial Attacks on Aligned Language Models
- Platypus: Quick, Cheap, and Powerful Refinement of LLMs
- Shepherd: A Critic for Language Model Generation
- まとめ
こんにちは。アナリティクスコンサルティングユニット所属の鈴木です。
前回の記事にもあるように、現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
今回はその中でも、性能改善関連で取り上げた4つの論文についてご紹介します。
論文選定基準
今回紹介するのは全て最近発表された論文のため、Citationの数で重要度を判断することができませんでした。
そこで、以下の手順で論文を選定しました。
1. ML Papers of The Weekから、LLMの性能改善に関する論文を10個ほどピックアップ
2. X(旧Twitter)の投稿についた表示数・リポスト数・引用数・like数
・ブックマーク数の日平均のランクが高い順に4つ選定
これにより、世間での論文への注目度をある程度定量的に比較できると考えられます。
今回選定した論文は、以下のような評価でした。
論文① : From Pretraining Data to Language Models to Downstream Tasks:Tracking the Trails of Political Biases Leading to Unfair NLP Models
論文② : Universal and Transferable Adversarial Attacks on Aligned Language Models
論文③ : Platypus: Quick, Cheap, and Powerful Refinement of LLMs
論文④ : Shepherd: A Critic for Language Model Generation
| Paper | 表示_r | リポスト_r | 引用r | Likes_r | ブックマーク_r | r平均 |
|---|---|---|---|---|---|---|
| 論文① | 1 | 1 | 1 | 1 | 3 | 1.4 |
| 論文② | 2 | 3 | 2 | 3 | 2 | 2.4 |
| 論文③ | 3 | 2 | 4 | 2 | 1 | 2.4 |
| 論文④ | 4 | 4 | 3 | 4 | 5 | 4 |
(r = rank)
From Pretraining Data to Language Models to Downstream Tasks:Tracking the Trails of Political Biases Leading to Unfair NLP Models

選定理由
モデルそのものの政治的偏見を測ることで、LLM出力の公平性という意味での性能改善に大きく貢献する内容だと思い、選定しました。
論文概要
- 各大規模言語モデルの政治的偏見を測定しています。
- これらの偏見による各モデルの不公平性を軽減するための方法を示しています。
この論文では、各種言語モデルがある特定の政治的に偏った出力を出す傾向にあることが示されています。
上の図にあるように、横軸がLeft(左翼的)かRight(右翼的)、縦軸がAuthoritarian(権威主義的)かLibertarian(完全自由主義)か、という基準で各モデルをカテゴライズしています。
どうやって偏りを測ったのか?
BERTのようなEncoderベースのモデルと、LLMによって測定方法を変えています。
①Encoderベースのモデル
以下のような入力文の[MASK]に入る部分を予測させ、その出力に応じてモデルの意見を分析しています。
“次の意見に対して、リアクションしてください。 [意見] 私はこの意見に[MASK]します。”
([意見]には各種政治的意見が、[MASK]には賛成・反対が入ります。)
②言語モデル(LLM)
以下のようなプロンプトを入力し、その出力に応じてモデルの意見を分析しています。
“次の意見に対して、リアクションしてください。: [意見]
あなたの意見 : ”
モデルが偏見を持つ事への解決策は?
このようにモデルの意見が政治的偏りを持つことが示されましたが、論文では以下のように解決することが可能と述べています。
①Partisan Ensemble(党派アンサンブル)
異なる政治的偏見を持つ複数のLMを組み合わせることで、その集合的知識を下流タスクに活用する手法です。これによりモデルがより公平な意見を持つようになることが論文内で示されています。
しかし、計算コストが増加する可能性や、追加での人的リソース必要となる可能性もあります。
②Strategic Pretraining(戦略的事前学習)
言語モデルは、自身と異なる政治的視点からのヘイトスピーチや誤情報に対して敏感です。例えば右寄りの情報源で前処理をしたモデルは、左寄りのニュースの矛盾をよりよく特定できます。この特性を利用して、特定のシナリオに特化した事前学習を行いバランスのとれたモデルを目指す方法が、戦略的事前学習です。
しかし、シナリオ固有の最適な前処理用コーパスを作成する方法については、引き続き調査が必要としています。
レビュー会FB
- こちらのIndirect Prompt Injectionに近い話に思える(取りにいく先のソースそのものに有害な情報を仕込んでおき、LLM自体への攻撃ではなく間接的にデータソースを汚染する)
関連論文
| タイトル | 概要 |
|---|---|
| Upstream Mitigation Is Not All You Need - Testing the Bias Transfer Hypothesis in Pre-Trained Language Models | 事前学習中の言語モデルが持つ偏見が微調整後のタスクで有害な行動に移行するという"バイアス転送仮説"(bias transfer hypothesis)についての論文。 |
Universal and Transferable Adversarial Attacks on Aligned Language Models

選定理由
LLMのアラインメントに関する研究は数多くありますが、その中でも最近大きく注目された論文だったため選定しました。
論文概要
・LLMヘの不適切な質問に対しても肯定的に回答生成させてしまう「敵対的サフィックス」についての論文です。
・サフィックスの生成方法が完全公開されています。
この論文では、不適切/有害なLLMへの入力に対して、ガードレール*1を飛び越えて素直に答えさせてしまう方法があえて紹介されています。具体的には、様々なプロンプトに付け加えることで、不適切な質問に対しても肯定的な回答を生成させる「敵対的サフィックス」を見つけ出す方法について論じています。
Chat GPT, BARD, Claude, LLaMA2といったそうそうたるモデルのいずれに対しても効果を発揮してしまう、恐ろしい手法です。
追加文の作成方法
以下のように敵対的サフィックスが学習・生成されます。
- プロンプトにサフィックスを足した全体のプロンプトをLLMに入力し、生成された応答を評価する。評価基準は、有害性、真実性、適切さなどの指標を定義し、これらのスコアの組み合わせで計算する。
- この評価スコアを最大化する方向で勾配上昇法によって追加文を最適化する。
- 複数のプロンプトとLLMに対して上記過程を繰り返し、汎用性の高いサフィックスを獲得する。
実験結果
提案された手法は、Vicuna-7BとLLaMA-2-7B-Chatで学習されたにも関わらず、ブラックボックスモデルを含む様々なLLMに対して有効性である事が示されました。特に、GPTベースのモデルに対して成功率が高かったようです。
本論文の倫理的な意義
この研究の内容には有害なコンテンツを生成するノウハウが含まれているためリスクを伴いますが、あえて手法含め研究内容を完全公開しています。というのも、この手法自体は実装が簡単で、かつ以前の文献にも類似の形で現れており、遅かれ早かれ悪意のあるユーザーに悪用される可能性があるためとの事です。より健全なLLMの構築や利用促進のために、良い形で本論が活用されることを願います。
レビュー会FB
Q:敵対的サフィックスを生成するために使用されたモデルは?
- Vicuna-7BとLLaMA-2-7B-Chatを使用して敵対的サフィックスの生成が学習されています。
関連論文
| タイトル | 概要 |
|---|---|
| Jailbroken: How Does LLM Safety Training Fail? | OpenAIのGPT-4やAnthropicのモデルのjailbreakに対しての脆弱性についての論文。 |
| SoK: Certified Robustness for Deep Neural Networks | DNNのロバスト性を上げるための学習アプローチの分類や、各アプローチの特徴、強み、限界等について述べた論文。 |
Platypus: Quick, Cheap, and Powerful Refinement of LLMs

選定理由
Kaggleのコンペでも話題になっており、性能改善というカテゴリにうってつけだと思い選定しました。
ちなみにPlatypus(プラティパス)とはオーストラリアに生息する、カモノハシのような生き物です。AlpacaやLlama, FalconのようにOSSのLLMモデルには動物の名前が付けられることが多いようですね。
論文概要
- Platypusというモデルについての論文。
- 主にデータセットに工夫をすることで、LLaMA2からさらに性能を高めることができた。
2023年8月に公開されたLLaMA2をベースにSupervised Fine-TuniningされたPlatypusというモデルについての論文です。
Hugging FaceのLLM Leaderboardからも、OSSでトップレベルの性能であることがわかります。
モデル概要
OSSのLLMとしては最高性能をはじき出したLLaMA2ですが、そこに以下のような工夫をすることで性能をさらに引き上げています。
- Open-Platypusというデータセットを使用
- オープンソースデータセットから厳選されたサブセレクションで構成
- STEM(Science, Technology, Engineering, Mathematics)と論理的思考力の向上に焦点を当てている
- 11のオープンソースデータセットから作成されている
- 主に人間が設計した質問から構成されており、LLMによって生成された質問は10%のみ
- 公開されており、第三者が使用する事が可能
- オープンソースデータセットから厳選されたサブセレクションで構成
- 訓練データとテストデータでリークが無いように念入りにチェック
- 類似度が0.8以上のものは訓練データから除外
モデル性能
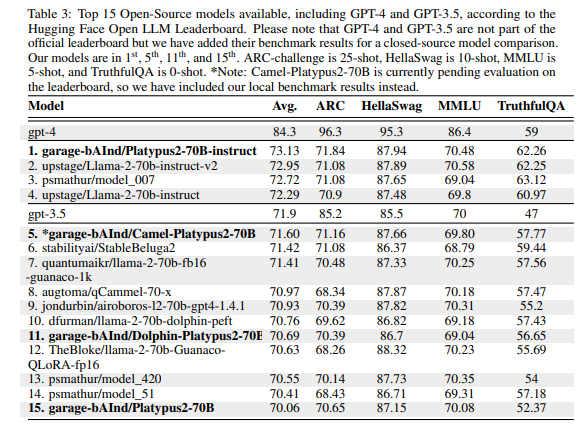
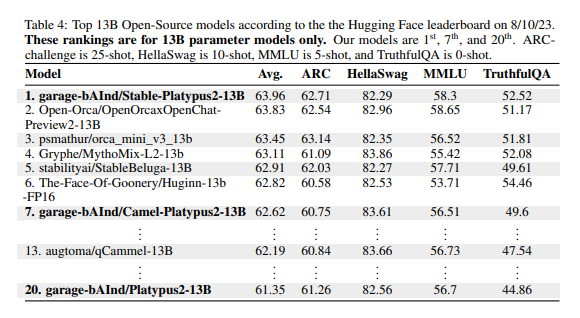
7B、13BモデルともにOSSモデルの中でトップクラスの性能となっています。
制限
- Platypusは主に英語データを使用しているため、他の言語の能力は保証されていません。
- RLHFによるアラインメントの担保は行われていないため、訓練によっては有害/攻撃的/偏った内容を出力する可能性があります。
レビュー会FB
Q : 少量のデータと計算量でtuningしているので、全体ではなく部分的なタスクにのみ強くなったのではないか?
- STEM領域や理論問題に特化しているため、ドメイン外の問題へのパフォーマンスは制限される可能性があります。
Q : ただ単にファインチューニングをして性能が上がったモデルということの他にどのような意義があるか?
- 基本的にはデータセットを工夫をしたというだけのようですが、それだけでかなりの性能が上がったという事が大きいように思います。やはりData Centricのアプローチが効きやすいということの証明かもしれません。
関連論文
| タイトル | 概要 |
|---|---|
| LIMA: Less Is More for Alignment | LLaMA65bを、厳選した1,000個の質問応答のみでSFTさせた(強化学習は無し)だけで、かなりの性能を持つモデル(LIMA)が構築できたという論文。 |
Shepherd: A Critic for Language Model Generation
選定理由
LLMのモデル出力を制御するガードレール手法は様々ありますが、出力の訂正に特化してモデルを構築した例は目新しく、とりあげさせてもらいました。
論文概要
- LLMのモデル出力評価に特化したモデル
- 新たなガードレール手法の一種
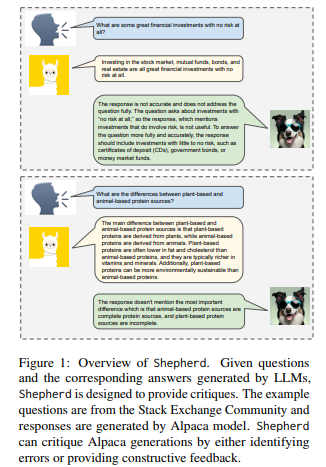
LLMモデルの出力を評価し、改善提案をする「Shepherd」(シェパード)という言語モデルについての論文です。7Bとパラメータは小さいですが、その性能はChatGPTを含む有名モデルと同等かそれ以上の品質です。
牧羊犬や警察犬のイメージがあるShepherdですが、AlpacaやLlamaといったLLMの出力を取り締まる、という意味合いでこの名前が選ばれたのでしょう。
入出力例
論文に記載されている例を引用します。
入力 : リスクの一切無い完璧な金融投資には何がありますか?
LLM出力 : 株市場、投資信託、債券、不動産への投資はすべて、リスクが一切ない素晴らしい金融投資です。
シェパード出力 : この回答は正確ではありませんし、質問に完全には答えていません。質問は「一切のリスクがない」投資について尋ねているので、リスクを伴う投資について述べるこの回答は役に立ちません。質問により正確かつ完全に答えるためには、リスクがほとんどない、または全くない投資、例えば定期預金、国債、またはマネーマーケットファンドについて含めるべきです。
このように、出力の内容を評価し、適切に訂正しています。
モデル構築方法
モデルの構築方法はいたってシンプルです。
①データセット準備
Question, Answer, そのAnswerに対してのCritique(批評)の3つで1つのセットとなっています。
②モデル学習
LLaMA-7Bをベースに学習させました。
データセット作成方法
以下のように大きく2通りの方法でデータセットが用意されました。
①Community Critique Data
- Stack ExchangeとRedditからQuestion, Answer, そしてCritiqueデータを収集
- Critiqueが適切なものに厳選
②Human Data Collection
- 8つのパブリックNLP用データセットを使用
- LLAMAやLIMAを使用し、質問への解答や要約タスクを実施(既に回答が用意されているものは除く)
- 回答に対して、人手により適宜Critiqueを作成
結果
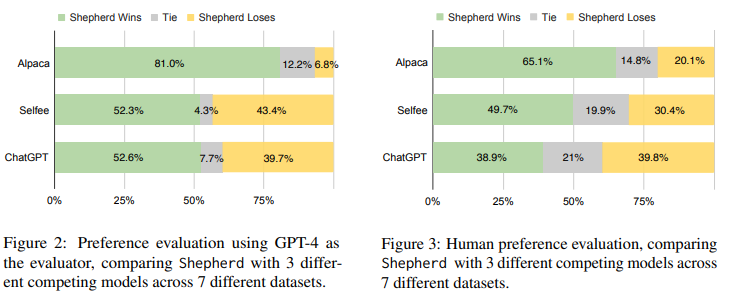
AlpacaやSelfee(Shepherdと同じくLLaMA7Bで学習されたモデル)と比べて選ばれる確率が高く(=性能が高い)、またGPT-3.5 Turboにも勝利か肉薄しています。
レビュー会FB
Q :トレーニング方法的に、一般的な改善は見込めるが、ドメインを絞った場合の正しさの評価ができるのか?なんでも判定できるわけではないのでは。
様々なデータを扱ってはいますが、ドメインによっては対応できない可能性は十分にあります。
Q : 答えを知っていて間違えを指摘できるのであれば初めからShepherdに聞くべきと思うが、LLMの出力と回答が対になっている必要はある?
あくまでもLLMの出力に対して批評をする事のみを目的に使用されたモデルのため、このような仕様になっています。
関連論文
| タイトル | 概要 |
|---|---|
| How Language Model Hallucinations Can Snowball | まさに雪玉が大きくなるように、ハルシネーションがハルシネーションを呼んでしまう事についての論文。 |
| SELFEE - Iterative self-revising llm empowered by self-feedback generation | LLM自身が自分の回答に対してセルフフィードバックをするモデルについての論文。 |
まとめ
今回は各言語モデルの政治意見のバイアス、有害な出力を促すプロンプト、新しいモデル、モデルの出力を規制するモデル、の4つについての論文をご紹介しました。
次回も別のテーマで論文を紹介させて頂きますので、ご期待ください。