
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。

こんにちは、アナリティクスサービス部の辻です。
今回はLLM(Large Language Model、大規模言語モデル)の振る舞いを制御するためのアプローチについてのお話をさせていただきます。
問題意識
LLMは、大量のテキストデータを学習した様々なタスクに対応できる汎用的な言語モデルであり、文章生成や要約、質問応答などの応用例が多くあり、高い性能を示しています。しかし、LLMはその性質上、不適切な出力を生成したり、バイアスやエラーを含んだりする可能性があることが指摘されています。
実際に、こちらの記事にもあるようにMetaが開発したGalactica*1というLLMは科学論文などをベースに学習された大規模言語モデルでしたが、誤った内容や人種差別的な内容を出力してしまうことが判明し、公開から3日でデモを非公開にする事態となった事例もありました。
また、LLMは特定の目的やコンテキストに応じた回答をすることが難しい場合もあります。例えば、自社サービスのFAQに対応するチャットボットに十分なドメイン知識を獲得できていないLLMを導入した場合、デタラメな商品の説明や値段を顧客に伝えてしまう可能性があり、信用を損なうリスクが生じます。こういった問題を避けるためにも、LLMが正確性を担保できる範囲の特定の話題にのみ回答するように制御する仕組みや技術が必要となります。
LLMが抱えるリスク
LLMが人間の制御下から外れてしまった場合、どのような問題が引き起こされるでしょうか?
以下のような社会的なリスクが生じると考えられます。
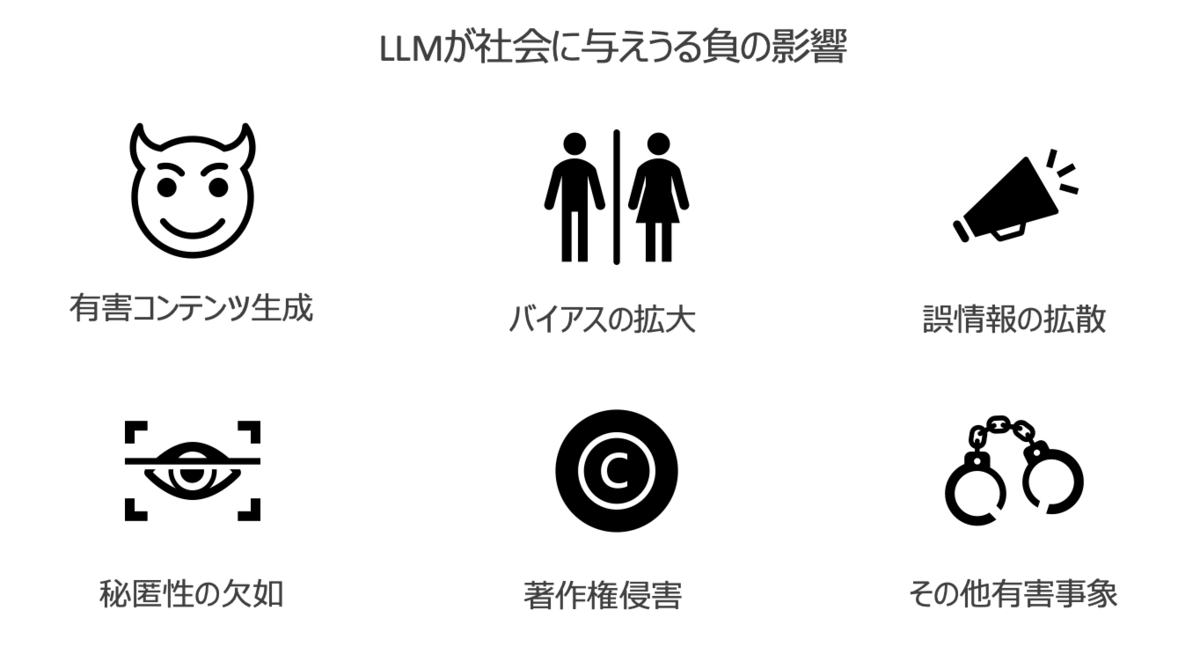
有害なコンテンツの生成
- 差別的、脅迫的、虚偽の情報などの生成することで、ヘイトスピーチやフェイクニュースの生成は社会にとって有害な影響を及ぼす
- 既にバイデン大統領がロシアへの攻撃を宣言するフェイク音声が生成されるなど社会問題になっている事例も多数発生
バイアスの拡大
- LLMが学習したデータセットに含まれるバイアス(性別、人種などに関する)を生成結果に反映してしまうことで既存の社会的偏見を助長することになる
- 政治的立場が偏った文章を指示を無視して生成してしまう事例も観測されている
誤情報の拡散
- 正しくない情報やでたらめな情報が拡散され人々が誤った判断材料に基づいて判断を下すことを助長する
- 幻覚(hallucination)と呼ばれるLLMが空想したデタラメな情報を提示する事例は数多く報告されており、実際に偽情報を記事として配信してしまった事例も報告されている
秘匿性の欠如
- 個人情報や機密情報が意図せず生成されてしまい、プライバシーや企業の競争力に対する脅威となる
- サムソンの社内情報がOpenAIに漏洩したニュースは記憶に新しい
著作権侵害
- 他者の著作物や商標を無許可で使用したテキストを生成してしまうことで、知的財産権の侵害し法的リスクを生む
- 生成AI画像に類似性が認められれば著作権侵害となりうる見解を文化庁が示している
その他有害事象
- 依存症行動の誘導、犯罪の教唆、他者への誹謗中傷など、想定外の有害事象を引き起こす
- GPT-4の検証の中でも初期バージョンのGPT-4が爆弾の作り方の手順を曖昧ながら答えてしまう現象が確認されている
こうしたリスクを抑制するために、LLMに対して適切な制御装置を設定し管理していくことはLLMを社会実装する上で非常に重要な課題となっています。十分な安全対策を施さない限り、一般社会での運用は難しいと考えられます。
LLMの振る舞いを制御するための技術
- LLMを制御するためには、モデルを調整するアプローチとモデルの前後を管理するアプローチが存在
- モデルを調整するアプローチはLLMが予期しない出力をしないようにパラメータを調整することで根本解決を目指すアプローチ
- モデルの前後を管理するアプローチはLLMが問題のある出力を行うのを前提にデータの除外やガードレールの設置を通じて出力の安全性を担保するアプローチ
- LLMを社会の中で安全に運用していくためには、出力のためのルールに従うガードレールの設置が重要と考えられる
では、LLMを制御するためにはどのような技術が必要でしょうか?
現時点でもLLMの振る舞いを制御するためのアプローチは色々と提案されていますが、大別するとモデルを調整するアプローチとモデルの前後を管理するアプローチの2つに分かれると考えます。
モデルの調整とは、モデルのパラメーターや構造を変更することで、モデルの性能や出力を改善することを指します。具体的な手法としては、以下のようなものが考えられます。
- プロンプトエンジニアリング
- ファインチューニング
- アライメント
モデルの前後の管理とは、モデルに入力するデータや出力する結果を監視したりフィルタリングしたりすることで、モデルの性能や出力を改善することを指します。具体的な手法としては、以下のようなものが考えられます。
- データクリーニング
- モデル監視
- 出力フィルタリング
モデルを調整するアプローチ
LLM自身のパラメーターや構造を変更することで、モデルの性能や出力を改善するアプローチであり、今も盛んに研究が行われている領域です。LLMはその表現力の高さが災いして有害であったりバイアスのかかった生成を行なってしまう可能性があるわけですが、それが野放しになったまま人類社会の中にLLMが入り込んでしまうと先ほど挙げた様々な負の影響を社会に及ぼすことになりかねないため、LLMを「良識ある」存在に調整する必要があります。
イメージとしては、素行が悪く他人を傷つけるような発言を繰り返す子供に対して、他人を傷つけたり不快な思いをさせないように更生させるためにあれこれと教育プログラムを受けさせる状況に近いかもしれません。
このアプローチの良い点は、LLMの持つ高い表現力を可能な限り制限せずに出力を制御できるようになる点だと考えられますが、一方で出力はあくまで確率的に推論されたものにすぎないため「絶対に」問題発言をしないことを担保できない点にあるところです。
また、差別発言や人類にとって有害な生成を抑制するのは公益性が高いためOpenAI*2やGoogle*3でも「Responsible AI」という文脈で取り組みを強化しており、今後も改善が進んでいくものと思われます。一方、人によって意見の分かれる価値判断(移民の受け入れ是非や死刑制度の容認是非など)や状況によって望ましいかどうかが異なる事象(子持ち世帯にとって児童手当増額は好ましいが独身世帯にとっては基本的に好ましくないなど)に対して特定の出力を行わないといった制御は行われないため、これからどれだけLLMが発展したとしてもLLMを利用するユーザーの状況に合わせた制御は必要になると思われます。
ここからは個別のアプローチについてご紹介していきます。
プロンプトエンジニアリング
プロンプトエンジニアリングとは、LLMに入力する指示文(プロンプト)やパラメータを工夫することで、LLMの出力を制御する方法です。
特にモデル自体を変更する必要がなく、すでに訓練されたモデルをそのまま使用することが可能なのが利点です。また、プロンプトを変えるだけなので、実装が比較的簡単です。しかし、一方で、必要な出力を得るための正確なプロンプトを見つけるのは難しく、多くの試行錯誤が必要になることがあります。さらに、場合によっては、人間が深い理解を必要とする複雑なプロンプトを作成する必要があります。
プロンプトエンジニアリングの性質の違いに基づいて3種類の手法をご紹介します。
入力プロンプトの工夫
LLMに与える入力文を工夫することで、出力の品質や多様性を向上させることができます。例えば、入力文にキーワードや質問文を含めたり、出力の形式や長さを指定したり、出力に含めたい情報や含めたくない情報を明示したりすることができます。皆さんが想像するプロンプトエンジニアリングのほとんどはこの入力プロンプトの工夫のことを指していると思われます。
以下は、入力プロンプトによって出力を制御する例です。
キーワード:「コロナウイルス」「ワクチン」「効果」
質問文:「コロナウイルスのワクチンはどれくらい効果があるのですか?」
出力の形式:「回答」
出力の長さ:「短い」
出力に含めたい情報:「ワクチンの種類」「効果率」「副作用」
出力に含めたくない情報:「政治的な意見」「個人的な感想」
プロンプトエンジニアリングについては、現在も数多くの手法が提案されており、今回の記事では紹介しきれませんので詳細についてはPrompt Engineering Guideをご参照ください。
パラメータの調整
LLMには、出力を制御するためのパラメータがいくつか用意されています。例えば、温度(Tempperature)は、出力の多様性やランダム性を調整するパラメータで、温度が高いほど出力は多様でランダムになります。また、Top Pは、出力に使用する単語の候補数を制限するパラメータで、候補数が少ないほど出力は安定します。
下図のようにOpenAI PlaygroundやAPIではTemperatureやTop Pを指定できるようになっていますのでパラメータを変更することで出力がどのように変化するか確認いただけます。
フィードバックの活用
LLMの出力に対してフィードバックを与えることで、LLMの学習や改善を促すことができます。例えば、出力に対して評価やコメントを付けたり、出力を修正したり、出力に関連する情報を追加したりすることができます。
入力プロンプトの工夫が指示の仕方(フォーマット)によって制御を行うアプローチであったのに対して、こちらは出力に対してフィードバックを与えることで出力の方向性を定め制御するアプローチとなります。
以下は、フィードバックの活用の例です。
出力:ワクチンは、種類によって効果率が異なりますが、一般的には80%以上の効果が期待できます。副作用は軽度なものが多く、重篤なものは稀です。
評価:Good
コメント:出力は簡潔で分かりやすい。
修正:ワクチンは、種類によって効果率が異なりますが、一般的には80%以上の効果が期待できます。副作用は軽度なものが多く、重篤なものは稀ですが、アレルギー反応などに注意が必要です。
追加情報:ワクチンの種類には、mRNAワクチンや不活化ワクチンなどがあります。
ファインチューニング
ファインチューニングとは、LLMを特定のタスクやドメインに関連するデータで再学習することで、LLMの出力を制御する方法です。特定のタスクやドメインに対して高いパフォーマンスを達成できるのが大きなメリットで、プロンプトエンジニアリングと比較して、より精密な出力制御が可能です。しかしながら、ファインチューニングには追加の訓練データと計算リソースが必要となり、その負担が大きいとされています。また、過学習のリスクがあり、訓練データセット外のタスクに対する性能が低下する可能性もあります。
ファインチューニングで指摘されている問題点を解消するために、PEFTと呼ばれる効率的な再学習方法も発展してきているため合わせて下記をご参照ください。
具体的にどのようなことがファインチューニングで可能かというと、GPT-3は、医療用語や医学知識を含むデータでファインチューニングすることで、医療関係者向けの回答を生成することができるようになります。最近では、PaLMを医療用データでファインチューニングしたMed-PaLM2*4なども出てきており、ドメインに特化したLLMが発展を続けています。
また、下記の記事のように自社ビジネスや社内用語に関連するデータでファインチューニングすることで、自社ビジネスの文脈に沿った言語生成を行うことができます。
意図していない出力をファインチューニングで抑制するアプローチはLLMのような言語モデルに閉じずに画像生成の分野でも注目されており、そちらでも盛んに研究が行われています。
Erasing Concept from Diffusion Models*5のようにヌード画像や著作権侵害が疑われるような画像を生成しないように制御する技術が発展し活用されるようにならなければ、技術的に画像生成や動画生成が行えるようになってもビジネスで運用するにはリスクが大きすぎますからこちらの発展にも注目していきたいですね。

論文のFigure.1から引用
アライメント
アライメントとは、LLMが生成するテキストが、人間の意図や価値観に沿っているかどうかを評価し目的に適合させる手法のことです。例えば、LLMが不適切な言葉や偏見を含むテキストを生成したり、事実と異なる内容を生成したりする場合、アライメントが低いと言えます。逆に、LLMが人間にとって有用で正確で公正なテキストを生成する場合、アライメントが高いと言えます。
アライメントはユーザーの目的や価値観を反映した出力を得ることが可能で、高度な制御が可能となります。しかし、実装が困難で、研究が進行中の領域です。また、ユーザーの目的や価値観を正確にモデルに反映させることは難しく、それを反映した取得コストの高い訓練データが必要となります。
アライメントを高めるためには人間のフィードバックや報酬を用いる強化学習の手法(RLHF)が有効だとされています。RLHF(Reinforcement Learning with Human Feedback)は、強化学習の一種で、人間のフィードバックを報酬として用いる手法です。RLHFでは、エージェントが生成したテキストに対して、人間が好ましいか否かを示すフィードバックを与え、エージェントの方策を更新するために利用されます。人間の意図や価値観をエージェントに反映させることで、アライメントを高めることができます。
OpenAIのCEOであるサム・アルトマンもアライメントがChatGPTの性能を高めるために有用であったと言及していますし(下記動画の6分あたり)、GPT-4もRLHFによってチューニングすることで有害な発言を軽減できたこと*6が報告されています。
RLHFの学習方法は発展段階で、実装まで含めた情報は限られていますが、DeepSpeed-ChatのようにRLHFに対応したフレームワークも登場してきています。
RLHFについてより詳細を確認したい場合には下記の記事を参考にしていただければと思います。
モデルの前後を管理するアプローチ
モデルに入力するデータや出力する結果を監視したりフィルタリングしたりすることで、モデルの性能や出力を改善するアプローチであり、どちらかといえばこれまでのMLOpsやDevOpsのような技術の延長にあるようなアプローチとなります。LLMそのものの調整は行わないため、基本的な姿勢としては「LLMは何らか問題のある生成を行う可能性がある」ことを前提に活用を考えるアプローチとなります。
イメージとしては、素行が悪く他人を傷つけるような発言を繰り返す子供に対して、更生ではなく厳格な行動規則を定めて監視し保護者が期待する振る舞い以外はさせないように強制する方法という感じでしょうか。あまりに厳格に人間に対してやると人権問題になりそうですね。
どのアプローチも基本的にはLLMの表現に制約を加える手法になるため、LLMが持つ表現力を奪うことになり得ますが、人類社会やビジネスは多くが確定的な情報に基づいて仕組みが作られている以上、一定のルールに従わせるというのは実務上有用だと思われます。LLMを社会実装することを考えた場合には、むしろこちらのアプローチをどのように洗練させていくかを検討した方が実効性の高いLLMの運用が可能になると考えています。
モデルの前後を管理するアプローチは、コンテンツモデレーションやガードレールといった言葉で表現されることが多く、今後これらの単語を目にする機会も増えていくのではと考えています。
では、それぞれのアプローチを確認していきましょう。
データクリーニング
データクリーニングとは、学習データから不適切な内容やノイズを除去することです。学習データは、モデルの出力に大きな影響を与えるため、学習データを事前に検査し、バイアスや偏見、誤情報などを含むテキストを削除することが重要です。
例えば、言語やドメインをフィルタリングしたり、重複や欠損値を削除したり、スパムや悪意のあるコンテンツを検出したりします 。
また、データクリーニングには、人手によるレビューだけでなく、自動化された手法も存在します。例えば、テキストのトピックや感情を分析してフィルタリングする方法や、モデル自身に不適切なテキストを検出させる方法などがあります。
データクリーニングによって学習データセット自体の品質が向上することで、LLMの学習時間やコストが削減され、不適切なデータを除外することで、LLMが不適切な出力を生成する可能性も低減されます。
一方でデータクリーニングの課題は、不適切なデータの定義や検出が難しいことが挙げられます。特に多言語や多ドメインの場合はその難易度が高まり、除外されたデータがどれだけあったかやその影響度が分かりづらいこともあります。
下記の記事の中では、データクリーニングのプロセスについてもまとめてあるので、ぜひご参照ください。
モデル監視
モデル監視とは、モデルの学習や出力のプロセスを常に監視し、異常や問題点を検知することです。モデル監視には、ログやメトリクスの収集や分析だけでなく、人間のフィードバックや評価も必要です。モデル監視によって、モデルが正しく学習しているかどうかや、モデルが予期しない出力を生成していないかどうかを確認し、得られた情報をもとに、モデルの改善や修正も行います。
モデル監視には、以下のような手法があります。
テストセット監視
- 事前に用意したテストセットを使ってモデルの出力を検証し、品質や正確さを測定
- テストセットは、モデルのタスクやドメインに合わせて作成される
- 例えば、GPT-3は、自然言語生成のタスクであるLAMBADAというテストセットで評価されている
- テストセットは定期的に更新されるように設計が必要
ライブデータ監視
- モデルが受け取る入力データを使ってモデルの出力を検証し、品質や正確さを測定
- モデルが未知のデータに対応できるかどうかを確認
- 人間のフィードバックやラベル付けを活用する
- 例えば、OpenAIは、GPT-3の出力に対して人間の評価者が品質や安全性などのメトリクスを付与している
メトリクス監視
- モデルの出力や性能に関するメトリクス(指標)を収集し、可視化や分析を実施
- 生成された文章の有害性やバイアスが評価指標となり得る
- モデルの傾向やパターンを把握し、閾値やアラートを設定して異常や問題を検知
モデル監視に関しては、MLOpsを拡張する形でLLM Ops*7という名称で議論がはじまったような段階です。
出力フィルタリング
出力フィルタリングとは、モデルが生成した出力から不適切な内容やノイズを除去することです。出力フィルタリングは、最終的なセーフティネットとして機能します。出力フィルタリングには、単純な単語や文のブラックリストだけでなく、より高度な手法も存在します。
高度な手法としては、出力の品質や信頼性を評価してフィルタリングする方法や、出力の倫理性や公平性を判断してフィルタリングする方法などがあります。例えば、unitaryのtoxic-bertを用いることで文章の有害性をスコアとして評価し、一定の閾値以上であればフィルターするといった運用が考えられます。
コンテンツモデレーションやガードレールの仕組みの中でも出力フィルタリングは重要な役割を果たしており、ビジネスへのLLMの適用を考えた場合には、消費者の安全と信頼を損なわないためにも確実に出力フィルタリングを実施できるかどうかが最も重要だと考えられます。
当然、LLMを提供する側もその点については感度高く対応しており、NVIDIAはLLMの安全性を担保するためにOSSでNemo GardrailsというLLMのためのガードレールを開発しています。その中で3種類のガードレール*8を設定しており、今後のガードレールを設定する際の指針となる考え方になると思われますので、今回はそこで提示されているガードレールをご紹介します。
話題のガードレール
- アプリケーションの目的やコンテキストに沿った話題に限定することで、望ましくない領域の話題に逸脱することを防ぐ
- 例えば、カスタマーサービスのチャットボットが天気や政治に関する質問に答えないように設定する
安全性ガードレール
- アプリケーションの利用者や社会に対して正確で適切な情報を提供することを保証
- 不要な言葉をフィルタリングし、信頼できる情報源のみを参照するように設定
セキュリティガードレール
- アプリケーションが安全性が確認されている外部のサードパーティアプリケーションとのみ接続するよう制限
- 例えば、メールやSNSなどの個人情報を扱うアプリケーションとは連携しないように設定する
今回は、LLMを制御するためのアプローチを大きくモデルを調整するアプローチとモデルの前後を管理するアプローチに大別して紹介させていただきました。
次回は、実務上最も有用性が高いと思われるガードレールの設置方法と設置した際の挙動の検証を実施していきたいと思います。
ここまでお読みいただきありがとうございました。