
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。

こんにちは、アナリティクスサービス部の辻です。
今回は、LLMを効率的に再学習する手法として今後重要性が高まっていくと考えられるPEFT(Parameter-Efficient Fine Tuning)という技術について紹介したいと思います。
問題意識
- 特定の目的や事業ドメインに即してLLMを用いるためにはFine Tuningが必要
- 数千億パラメーターを持つLLMをFull Fine Tuning(Full FT)によって再学習するのは時間的にもコスト的にも現実的ではないため、効率的な再学習アプローチの検討が必要
ChatGPT*1がリリースされて以来、大規模言語モデル(LLM)が世界中から注目を集めています。
ChatGPTやBERTなどのモデルは、膨大なテキストから一般的な言語知識を獲得し、さまざまなタスクに対応できる能力を持っています。例えば、ChatGPTやAlpaca*2などのLLMは、要約、翻訳、分類、生成などの多くのタスクを行うことができます。
しかし、LLMをそのまま利用するだけでは、特定の目的や自社のビジネスに適した性能を発揮するとは限りません。LLMが学習しているのはWEB上で得られるデータやデータ化されている論文や会話が中心であり、ビジネスに関わる正確な知識は獲得できていないと考えられます。そこで、LLMを追加のデータやタスクに合わせて学習させることで、自社のビジネスやワークフローに沿うようにモデルをカスタマイズする方法が必要となります。この方法をファインチューニング(Fine Tuning)と呼びます。
ファインチューニングを行うことで、LLMのような事前学習済みモデルのパラメータを一部または全体的に更新し、モデルの振る舞いを変化させます。
しかし、事前学習済みモデルを特定の下流タスク*3に適応させるためには、通常、モデルの全パラメータを再学習する必要があります。しかし、現在の事前学習済みモデルのパラメータは数千億を超えるものも出てきており、容易には実行できない状態となっています。
LLMや大規模な事前学習モデルを用いたサービスやビジネスが広く社会に普及していくには、通常のファインチューニング(Full FT)とは異なる効率的なファインチューニングのアプローチが必要とされており、社会的なニーズに応えるように現在PEFT(Parameter-Efficient Fine-Tuning)が大きな発展を遂げています。
なお、本記事では通常のファインチューニング手法をFull FT(Full Fine Tuning)と呼び、効率的なファインチューニング手法であるPEFT(Parameter-Efficient Fine-Tuning)と区別します。
ビジネスで利用する際に乗り越えるべき壁
PEFTの具体的なアプローチを紹介する前にFull FTの性質について整理しておきます。
Full FTは高い精度と汎化性能を達成できる反面、ビジネスや実社会での利用を考えた場合には乗り越えるべき障壁が複数存在します。仮に、企業固有のタスクや事業ドメインを適用させるためにFull FTを利用するのであれば、下記のような問題に悩まされることになるでしょう。

全パラメータの更新には膨大な計算コストが掛かる
- モデルのサイズが大きくなるにつれて、計算コストやメモリコストが増大し、実行が困難になる
- 例えば、GPT-3は1750億パラメータを持っているため膨大な時間とリソースが必要であり大規模な計算リソースを有している企業や団体でなければそもそも実行が不可能
壊滅的忘却が発生するリスクがある
- モデルのパラメータが新しい概念やタスクを学習する過程で、事前学習時に獲得した一般的な言語知識を失う壊滅的忘却と呼ばれる事象が発生する可能性がある
- 壊滅的忘却が起こることで、意図しないモデルの汎用性や転移性能の低下が発生することにつながる
学習データが少ない場合にオーバーフィットしやすい
- 新たなタスクの適用のために用意できるデータが少ない中で全てのパラメータを更新した場合には過学習(オーバーフィット)が起こる可能性が高く、タスク固有の知識に依存してしまう可能性がある
モデルサイズが大きく管理運用コストが大きい
- 異なるタスクに対してFull FTを行うたびに、モデルのパラメータを保存するために多くのストレージスペースが必要
- また、モデルのサイズも大規模であるためモデルの管理や共有が困難
これらの問題を解決するために、PEFTと呼ばれる手法が提案されています。
PEFTとは何か?
- PEFTは一部のパラメータだけをファインチューニングするアプローチ
- Full FTと同程度の精度を保ちつつ計算コストを削減し、優れた汎化性能を獲得することが可能
- 現在発展しているPEFTのアプローチは大きく3つのコンセプトに分類可能
- トークン追加型
- Adapter型
- LoRA型
PEFTとは、LLMのような事前学習済みモデルを、新しいタスクに効率的に適応させるための手法です。モデルの全体ではなく、一部のパラメータだけをファインチューニングすることで、Full FTの持つ問題を解決できる手法として注目を集めています。
PEFTのアプローチは数多く提案されていますが、どのアプローチにも共通する特徴があり、性能面でも管理運用面でもビジネス適用において好ましい性質を持っています。

計算コストとストレージコストを削減
- PEFTでは、事前学習済みモデルのほとんどのパラメータを凍結したまま、少数の追加モデルパラメータのみをファインチューニングするため、計算コストとストレージコストを大幅に削減することが可能
致命的な忘却を抑制
- Full FTの場合には、モデルが事前学習で学んだ知識を忘れてしまう壊滅的忘却が発生することがあるが、PEFTでは限られた数のパラメータ(0.1%~数%)を更新するだけに留まるためこの問題を回避できる
未知の状況に対する優れた汎化性
- PEFTでは、学習に用いることが可能なデータが限られている状況ではFull FTよりも優れた性能を発揮し、未知の状況に対しても優れた汎化性を発揮することが示されている
モデルサイズが小さく管理運用コストが小さい
- Full FTでは大規模なモデル(数十GB)が作成されるのに対して、PEFTでは数MBの小さなモデルで済むことが多い
- PEFTで学習した重みは、モデル全体を交換することなく、複数のタスクに簡単に導入可能
PEFTのコンセプト分類
PEFTは発展中の技術であるため、今後も様々なアプローチが提案されることが考えられますが、現時点(2023年5月)で発表されているアプローチはコンセプトの違いによって3つに分類が可能であると考えます。
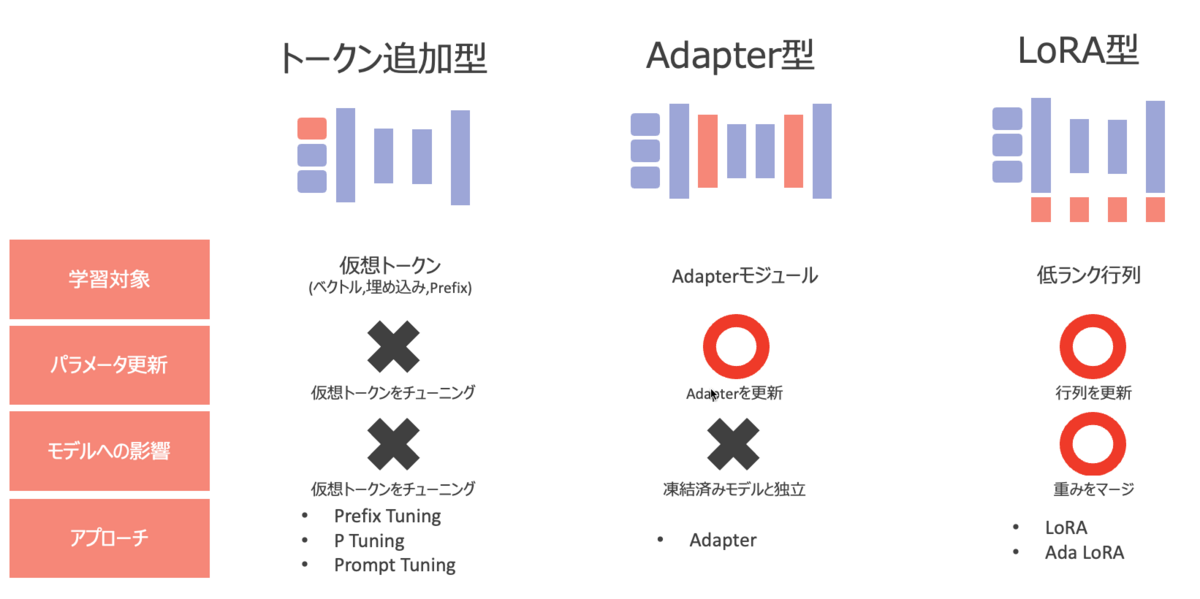
トークン追加型
- 入力層に仮想トークンを追加することで、特定のタスクに固有の特徴を学習
- 事前学習済みモデルのパラメータ自体は更新せず凍結させる
- 言語理解やテキストの翻訳・要約タスクに対しての適用が可能で画像分類などには適用できない
Adapter型
- 事前学習済みモデルの外部に特殊なサブモジュールを追加しパラメータを更新
- Adapterのパラメータを更新し、元の事前学習済みモデルのパラメータは凍結させる
- 言語理解やテキストの翻訳・要約タスクに対しての適用が可能
LoRA型
- 事前学習済みモデル自体は凍結させ、低ランク行列のみを更新
- 低ランク行列を更新した上で元の事前学習済みモデルの重みを加算しパラメータを更新する
- 言語理解やテキストの翻訳・要約タスクだけでなく、画像生成や画像分類のタスクにも適用可能
以降はコンセプト毎にどのようなアプローチがあるかを解説していきます。
トークン追加型
トークン追加型に属するアプローチは、事前学習済みモデルの重みをファインチューニングする代わりに、入力層に仮想トークンを追加することで、特定のタスクに固有の特徴を学習するアプローチとなります。
Huggingfaceでは、Prefix TuningとP TuningとPrompt Tuningの3つのアプローチがすでに実装されています。事前学習済みモデルの重みを更新しないアプローチという点は共通していますが、どのような形で学習を行うかはアプローチごとに特徴がありますので、それぞれ簡単にご紹介していきます。
Prefix Tuning
アプローチ概要
Prefix Tuning*4は事前学習済みモデルのパラメータを凍結し、入力の先頭にk個の連続したタスク固有のベクトル(プレフィックス)を追加した上で、プレフィックスのみを学習し、事前学習済みモデルの各層に加算する手法です(下図参照)。プレフィックス自体は学習可能なパラメータであるため、プレフィックスにタスク固有の情報を与えることになります。
また、プレフィックスは、タスクに応じてファインチューニングされるため、モデルの出力をタスクに適したものに変えることができます。下図では翻訳用のプレフィックスや要約用のプレフィックスを付与し、プレフィックスがタスク固有の情報を獲得しています。
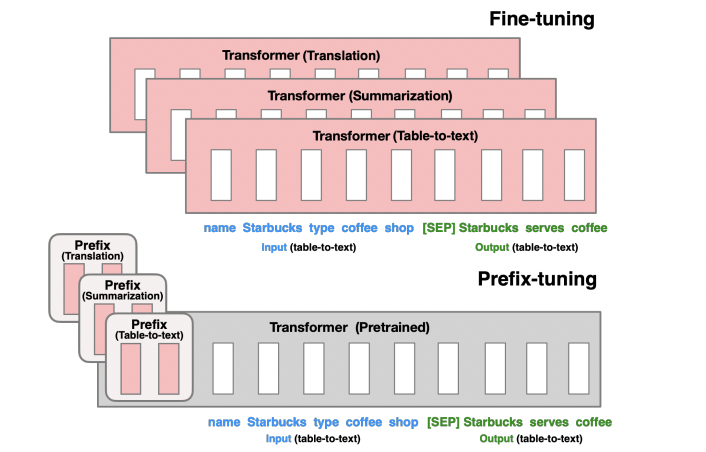
論文の図表.1から抜粋
Prefix Tuningは、事前学習済みモデルのパラメータ数に比べて、非常に少ないパラメータ数でタスクを学習できるため、効率的なファインチューニングが可能となっています。
特徴
トークン追加型のアプローチ全てに共通する点ではありますが、事前学習済みモデルのパラメータを凍結することで、学習に必要な計算資源や時間を大幅に削減できます。
プレフィックスは連続的なベクトルであり、実際のトークンではないため、語彙サイズや入力長に制限されないところが大きな特徴となります。
また、プレフィックスはタスク固有のものであり、複数のタスクに対して同じ事前学習モデルを使い回すことができます。
パラメータ全体のうち0.1%のパラメータを学習しただけで、Prefix TuningはFull FTと同等の性能を獲得し、データ量の少ない場合ではFull FTの精度を上回っていることが論文内で報告されています。
P Tuning
アプローチ概要
P Tuning*5とは、事前学習済みモデルの入力に、パラメータ化されたプロンプトを追加することで、タスク固有の情報を与える手法です。Prefix Tuningと同様にプロンプトは、タスクに応じてファインチューニングされるため、言語モデルの出力をタスクに適したものに変えることができます。
P Tuningもまた、事前学習済みモデルのパラメータ数に比べて、非常に少ないパラメータ数でタスクを学習できるため、効率的なファインチューニングが可能となっています。
特徴
モデルのパラメータ数に依存しないため、大規模なLLMでも低コストでファインチューニング可能でありプロンプトが連続的なトークンであるため、LLMの入力長制限に影響されない点が大きな特徴となります。
P Tuningはプロンプトエンジニアリングの手間を減らし、論文発表時点でのSuperGLUEベンチマークにおいて、最先端のアプローチを凌駕する性能を発揮しました。
Prompt Tuning
アプローチ概要
Prompt Tuning*6は、事前学習済みモデルのパラメータを凍結し、事前学習済みモデルのパラメータを更新する代わりに、ソフトプロンプトを学習しラベル付けされたサンプルを取り込むことでファインチューニングを行うアプローチとなります。下図のようにPrompt Tuningでは、タスクごとにモデルのチューニングを行う代わりにタスクごとに小規模なプロンプトを付与することでチューニングを行います。
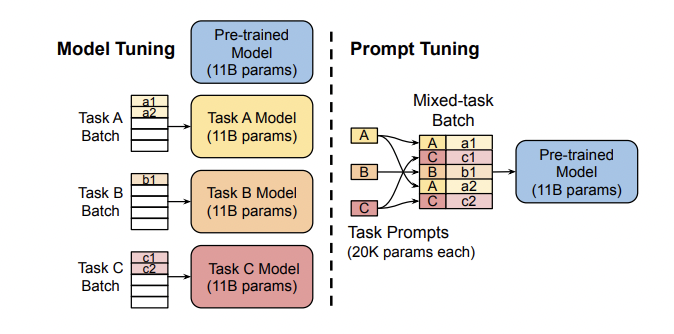
論文の図表.2から抜粋
特徴
タスクごとに付与されるソフトプロンプトはモデルに依存しないため、頑健にドメイン転送が可能である点がこのアプローチの特徴と言えます。
論文ではモデルサイズが大きくなるほど性能が改善することが示されており、モデルのパラメータが数十億を超えると大きな性能改善が見られています。
Adapter型
次に、Adapterと呼ばれる特殊なサブモジュールを事前学習済みモデルの外部に追加するアプローチをご紹介します。Adapterは事前学習済みモデルに付加される独立したコンポーネントとして機能するため、Adapterを追加/除去するだけで事前学習済みモデルを再利用可能です。
HuggingfaceにおいてPEFTのライブラリーとして取り込まれていないもののLoRAとのコンセプトの違いを明確にするためにAdapterのアプローチについてもご紹介しておきます。
Adapter
アプローチ概要
Adapter*7は事前学習済みモデルの外部に追加される特殊なサブモジュールで、下図にあるようにTransformerのMulti-Head Attention層とFeed -foward層の後に挿入することで、ファインチューニングの際に事前学習済みモデルのパラメータを凍結したままAdapterのパラメータのみを更新するアプローチとなります。
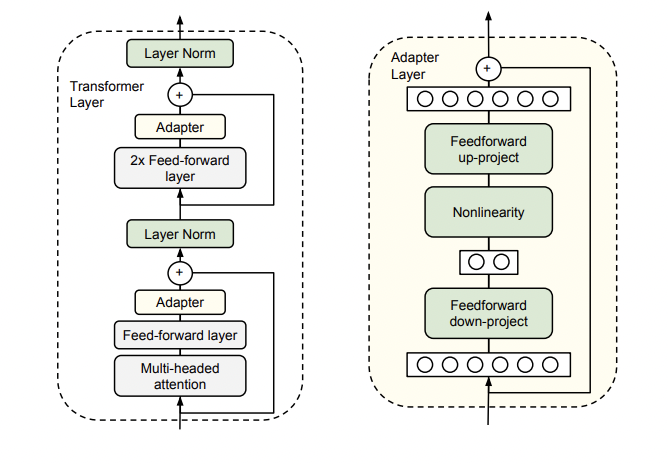
論文の図表.2から抜粋
特徴
AdapterはTransformerのMulti-Head Attention層とFeed Foward層の出力を入力として受け取り、出力を生成する仕組みとなっているためTransformerの機能に直接影響を与えない構造となっています。
柔軟にAdapterの挿入と削除ができる代わりに、推論が行われるたびに凍結された重みを持つTransformerの出力をAdapterが入力として受け取り出力を返す必要があるため推論に時間がかかる傾向があります。
LoRA型
最後にLoRAと呼ばれる低ランク行列のみを更新することで効率的にパラメータをファインチューニングするコンセプトのアプローチをご紹介します。
HuggingfaceのPEFTのライブラリーとしてはLoRAとAda LoRAが実装されています。LoRAは言語タスクのみに留まらず画像タスクに対しても効率的なファインチューニングが可能となっており、非常に応用範囲の広いアプローチとなっています。
LoRA
アプローチ概要
LoRA(Low-Rank Adaptation)*8は、事前学習済みモデルのAttention層のクエリとバリューに対して、低ランク行列を適用することで、パラメータ数を大幅に削減しながら、元のモデルと同等かそれ以上の性能を達成する手法です。
具体的には、下図のように事前学習済みモデルのパラメータを凍結した上で、クエリとバリューの行列に対して低ランク行列を掛け合わせて新たな行列を作ります。この低ランク行列は、ファインチューニング時に学習される唯一のパラメータとなります。
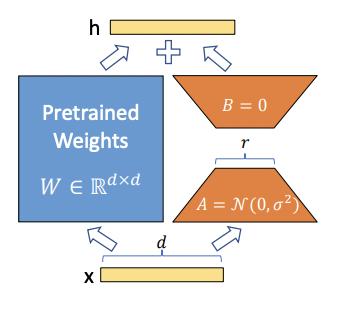
論文 の図表.1から抜粋
特徴
LoRAは事前学習済みモデルの99.9%以上のパラメーターを凍結した上で新しいタスクを学習するために低ランク行列のみを更新しています。これによりFull FTと同等の性能を実現する一方で、パラメータ数と計算要件を大幅に削減することに成功しています。
Adapter では、事前学習済みのモデルにトレーニング可能なパラメーターが追加されるため、推論の待ち時間が長くなる可能性がありましたが、LoRAでは、トレーニング可能な低ランク行列が事前学習済みモデルの各層に注入され、推論中に凍結された重みと更新された重みをマージできるため、推論の遅延が発生しにくくなります。
LoRAを用いることで、計算リソースとストレージコストがシビアとなる本番環境において、LLMをデプロイしやすくなります。
大きな有用性のあるLoRAですがいくつか課題も指摘されています。
変換した低ランク行列が元のモデルの表現力をある程度損なう可能性がある点やパラメータの更新が元の事前学習済みモデルに依存しているために、その事前学習済みモデルの性能と制限事項を受け継ぐ点が課題として指摘されています。
Ada LoRA
アプローチ概要
Ada LoRA*9とは、Adaptive Low-Rank Adaptationの略で、LoRAを拡張した手法です。Ada LoRAは、低ランク行列を追加するだけでなく、各層に適応的な学習率を与えることで、パラメータ数や学習時間をさらに削減します。
Ada LoRAは、LoRAよりも高い性能を達成できる可能性がありますが、パラメータ数や計算量が増加することが想定されます。
特徴
事前学習済みの言語モデルのパラメータを凍結し、追加した低ランクな行列だけを学習することでパラメータ数や計算量を抑えるという点は、LoRAと同じですが層の重要度に応じて学習率を変化させることで、重要な層はより多く学習し、重要でない層はより少なく学習している点が改良点となります。
また、Ada LoRAではファインチューニング時に使用するデータセットやタスクに応じて、最適な低ランク行列や学習率を自動的に決定することができます。
一方、LoRAと比較すると低ランク行列や学習率を決定するために必要なハイパーパラメータが多いため、そのチューニングが難しい場合があります。
まとめ
今回は大規模な事前学習済みモデルに対して、効率的に新たなタスクを適用可能にするPEFTという技術を紹介させていただきました。本記事では、PEFTにどのようなアプローチがあるのかを中心にご紹介しましたが、今後は実際にPEFTを用いてどの程度学習コストが低下したか、どの程度の精度を保つことができたかについてもご報告していく予定です。
参考文献
*1:OpenAIが2022年11月に公開したAIチャットボット
*2:スタンフォード大学の研究チームが開発したオープンソースLLM
*3:ダウンストリームタスクとも言われる
*4:Prefix Tuning: https://aclanthology.org/2021.acl-long.353.pdf
*5:P Tuning: https://arxiv.org/pdf/2103.10385.pdf
*6:Prompt Tuning: https://arxiv.org/pdf/2104.08691.pdf
*7:Adapter: https://arxiv.org/pdf/1902.00751.pdf
*8:LoRA: https://arxiv.org/pdf/2106.09685.pdf
*9:Ada LoRA:https://arxiv.org/pdf/2303.10512.pdf