

こんにちは。デジタルソリューション本部 プレディクティブマーケティングサービス部の西村です。
弊社が販売支援やコンサルティング等を行っている機械学習・予測分析システム「SAP® Predictive Analytics」は、2006年の販売支援開始以降、マーケティング分野(顧客反応予測 等)を中心にご活用いただいています。
一方で最近は、働き方改革の流れから、人事労務分野での機械学習の導入と、SAP® Predictive Analyticsの活用を目指すクライアント企業が増えてきたように感じています。
SAP® Predictive Analyticsは、マーケティングに特化した予測分析ツールというわけではなく、特にデータの前処理や予測モデル作成の自動化を強みとして、製造業分野(不良品(異常値)検知等)、保険・証券分野(信用リスクの予測等)など、多種多様な分野で活用されています。もちろん、人事労務分野でも活用できますが、人事労務分野での特殊なデータ構造や、適切なKPI設定の重要性等きちんと考えて運用しなければ、宝の持ち腐れとなってしまいます。
本ブログでは、退職者・休職者予測を例にして、特に人事労務分野での機械学習導入における課題(人事データの取り扱い、KPIの設定)などをお伝えさせていただき、SAP® Predictive Analyticsを導入することで、複雑な人事データをデータマートとして構築し、予測モデルを構築する流れも簡単にご紹介します。
目次.
1. HR(人事労務分野)での機械学習利用
皆様は、「HRテック(テクノロジー)」という言葉を聞いたことはあるでしょうか(*1)。
HR(Human Resources)とTechnologyをあわせた造語で、日本でも2015、2016年頃から定着しはじめた概念で、テクノロジーの力でHR(人事労務等)を良くしていこう、という考え方です。HRテックの分野において、主に機械学習は下記の様な領域で使われています(*2)。
(1). 採用(応募者選定の効率化、スキルセットの予測)
(2). 人事評価(パフォーマンス予測、タレントマネジメント)
(3). 休職・退職者予測
特に、退職者予測については、企業からみた退職のコストの高さと、売り手市場による転職者数の漸増傾向から、特に注目されている分野です。
当記事では、(3)の「退職者予測」を題材に、HR領域で機械学習を利用する際の注意点についてご説明させていただきます。
*1: HRテクノロジーとは
*2: 人工知能が変えたHR(ヒューマンリソース)の領域。海外に習う最先端HRTechサービスまとめ
*3: 総務省統計局 労働力調査(詳細集計) 平成30年(2018年)平均(速報)結果
2. 退職者予測における機械学習の導入とその課題
・KPI設定の重要性
他領域と同様にHR領域においても、「機械学習を導入することによって何を目指すか」という点をきちんと定義することが重要です。
今回例にあげる退職者予測においては、もちろん「退職者の人数を低減する」ことが共通の大目的となりますが、小目的に優先順位をつけようとする場合、企業のおかれた状況によって、以下のような分類ができるのではないでしょうか。
(1-1). ハイパフォーマーの退職を食い止めたい。
(2-1). (メンタルヘルスの問題などによる)突発的な退職の兆候を、早期発見したい。
(3-1). 恒常的に退職が多い理由を突き止め、業務的な改善を行いたい。
実際の施策に落としこむ場合にも、小目的に応じて、取るべきアプローチも変わっていきます。
(1-2). 退職確率が高いと思われるハイパフォーマーに対し、面談などを行う。
(2-2). 退職確率が高いと思われる社員について、〇か月前に担当部署宛てにアラートを出す。
(3-2). 退職の要因と思われる部署、業務などに対して、改善措置を講じる。
目的と施策をつなぐ役割となる「機械学習による予測分析」において、上記のように言語化をきちんと行わないと、コストが見合わなかったり、施策と乖離していたり、精度が要求水準に達しない、などのピントはずれの分析になってしまう可能性が高くなっていきます。
例として、 (2-1)「突発的な退職の兆候の早期発見」という目的と、(2-2)「退職・休職確率が高いと思われる社員について、〇か月前に担当部署宛てにアラートを出す」という施策について、どのように機械学習を導入するべきか考えてみましょう。
突発的な退職の直前の傾向として、転職活動を精力的に実施しているのであれば、「有給休暇取得数」といったデータに現れてくるでしょうし、体調やメンタルの不調で退職しそうなのであれば、「遅刻数・早退数」といったデータに現れてくるでしょう。最近では勤怠管理システムと連動した退職予測ツールがリリースされており、そういった普遍的なデータを使って、直近の退職・休職者予測を行うのであれば、こういったツールを導入したほうが適切でしょう。むしろ、自社の勤怠データのみを使って退職予測モデルをスクラッチで開発するより、アルゴリズム・学習モデルが洗練された退職予測ツールの方が高い予測精度を実現できるかもしれません。
一方で、上司とのミスマッチングや、部署ごとに仕事の特性や、社員のスキルセットが全く異なっている場合など、導入する部署、企業、業務の特殊性が高くなるほど、勤怠データを使うだけでは適切な予測は行えなくなるでしょう。また、勤怠データは直近の状況に対するバロメーターになると思われるので、1年後の休職・退職者の予測には利用しにくいデータになるかと思います。
このように、皆様のおかれた状況や目的に応じて、適切な導入手法は異なってくることがご理解いただけたかと思います。
・データ準備
さて、実際に機械学習による退職予測モデルを開発することになった場合、退職に関係しそうなデータを各所から集めてくる必要があります。おそらく、以下のようなデータを利用できるでしょう(*4)(*5)。
・基本属性情報(年齢、性別、資格、給与、家族構成など)
・実績、履歴
・職務内容
・勤怠管理データ(早退・遅刻、休暇取得状況、残業時間など)
・社内での各種アンケート・テスト結果(満足度調査、適性検査、昇進試験など)
・健康診断情報
・行動データ(社内システムログ、PC利用ログ、メール、カレンダー情報など)
なお、上に記載したデータの中には、かなりセンシティブな個人情報も含まれており、例え自社社員の情報であっても、全てのデータをフリーハンドで利用することは許されません。
例えば、自分の持病の情報や家族関係などの情報を使って分析されている、というのは(予測モデルの構築にしか使われないとしても)かなり心理的に抵抗があるのではないでしょうか。
実際に予測モデルを作る際には、上記を念頭において、社員に向けてデータ利用についてきちんと確認をとる、データに直接触ることができる人材を制限する、そもそも分析に使うデータ自体を制限する等、適切な取り扱いを行ってください。
*4: 【人事のためのピープルアナリティクス入門】ハイパフォーマー分析をするメリットと分析方法
*5: 人材データベースとは? 構築の目的、項目例、活用事例
・データの注意点
人事データは、もともと機械学習に利用するために取得した情報ではないため、機械学習に利用しやすいようなフォーマットになっていなかったり、データが欠落していることが数多く発生しているかと思います。(*6)
例えば、
・年毎に取得できる項目に増減がある。(アンケート、テストなど)
・直接分析にかけづらいテキストなどの項目が多く含まれている。
・客観的でない、個人による評価が多数含まれている。(社内評価など)
・そもそも、データ数が少ない(最高でも、過去に所属したことのある延べ社員数がデータ数の上限となる)
1番目の問題であれば、そもそも年を通じて共通した項目しか利用しない、という選択が挙げられます。一方で、人事データ(特に社内にあるデータだけ)ではデータ数が不足しがちなため、因子分析などを実施し、似たような内容の項目であれば縮約して説明変数とすることも適切かと思います。
2番目の問題については、ドメイン(業務)知識に基づいて、ネガポジの分析などを丁寧に行う必要があります。
3番目の問題であれば、例えば評価を行った上司や同僚がどのように評価されているか、などの説明変数を組み合わせて、多角的な分析を行うとよいかもしれません。
(このような分析を行うことで、「上司と部下の相性」のようなものを可視化できる可能性があります。)
4番目の問題であれば、あまりにもデータ数が少ない場合はそもそも機械学習を導入するべきではないですし、そうでない場合も過学習などを回避するために、アルゴリズムや説明変数の選定を慎重に行う必要があります。
・目的にあわせた分析KPIの策定
ビジネス上の目的にあわせて、予測の精度、期間をきちんと決めることも重要です。
例えば、退職の予測について、退職1か月前に退職者を90%当てる予測モデルを作ったとして、ビジネス上有効でしょうか。1か月前であれば、例えば退職前にまとめて有給取得しているなど、説明変数に退職の兆候が多く含まれていて、実際に高い精度のモデルは得られるでしょう。しかし、そもそも退職であれば1か月前に申請しているのが常なので、誰もが分かる退職者を予測しているだけ、という結果になりがちです。また、直前の予測だけでは、ビジネス上有効な施策を打つ時間も足りません。
一方で、3年後の退職を予測するモデルを作っても、予測精度が絶対的に不足してしまうでしょう。予測の精度・期間のトレードオフを考慮して、分析KPIの策定に取り組んでみてください。
・アルゴリズムの解釈可能性について
機械学習を使った退職予測モデルを構築する場合、予測の精度と同じくらい、「どういった人が辞めやすいか」といった、理由の可視化が重要です。
深層学習やランダムフォレストといった、「予測精度は高いが、(退職の)理由がブラックボックスになりやすいアルゴリズム」を採用して予測を行った場合、実際の現場での活用は難しくなります。
例えば、Aさんの退職確率が高いとして、どのような施策を実施すればいいでしょうか?Aさんが退職しようとしている理由は、家庭の事情で実家に戻るからかもしれませんし、残業時間が長すぎるからかもしれませんし、あるいは逆に仕事が少なすぎてキャリアに不安を感じたからかもしれません。退職理由によってフォローアップすべき内容も異なるため、退職理由を可視化しなければ、実際の施策として「退職確率の高い社員に対してアラートを出す」以外のことは行いにくくなります。現場での納得感や協力も、得られにくくなってしまうでしょう。
3. SAP® Predictive Analyticsの導入
SAP® Predictive Analyticsでは特にデータ加工(データマート)の機能が充実しており、各種データベースのつなぎ込みや、データの加工について、データベースやSQLの知識がなくても実施することができます。
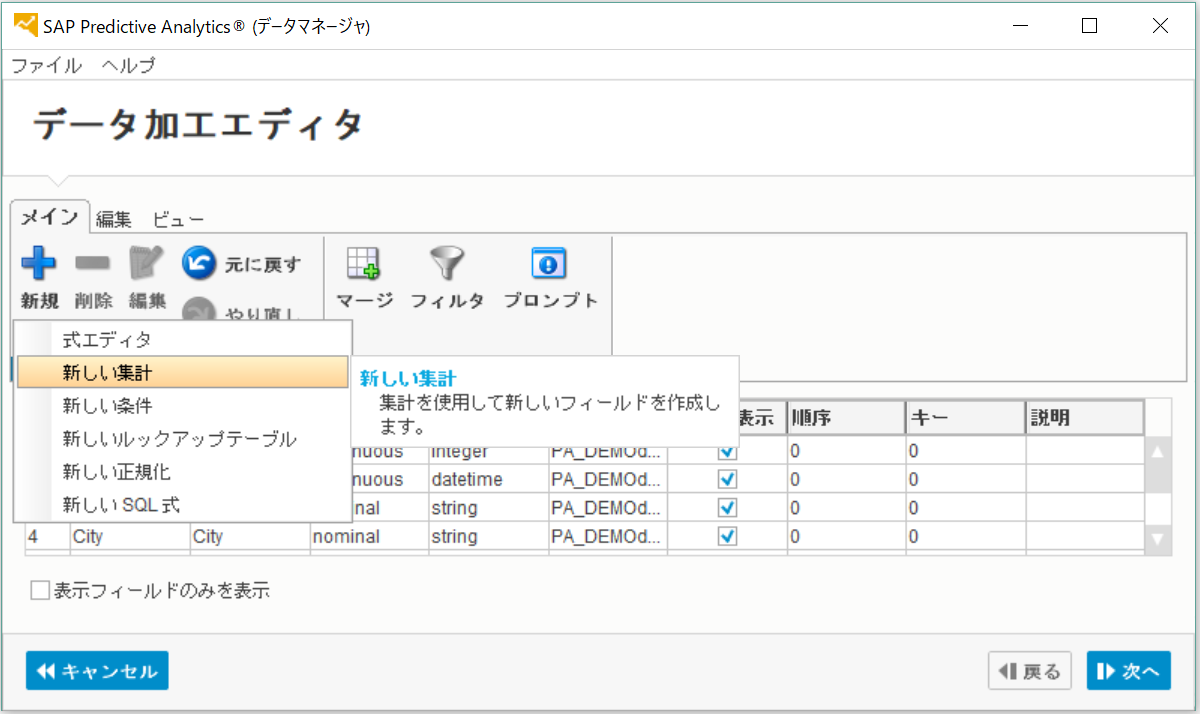
HR領域で利用するような、上述した特殊な人事データについても、データの欠損を補完する仕組みが整っており、作成したい予測モデルに合わせて、下記のような様々な加工をSQL等を使わずに行うことが可能です。
・説明変数を組み合わせて合成変数を作成する
・トランザクションデータを任意の期間等に合わせて集計する
・データの正規化を行う
このように作成したデータマートを使って、退職者分析に限らず様々な予測モデルを構築することが可能となります。
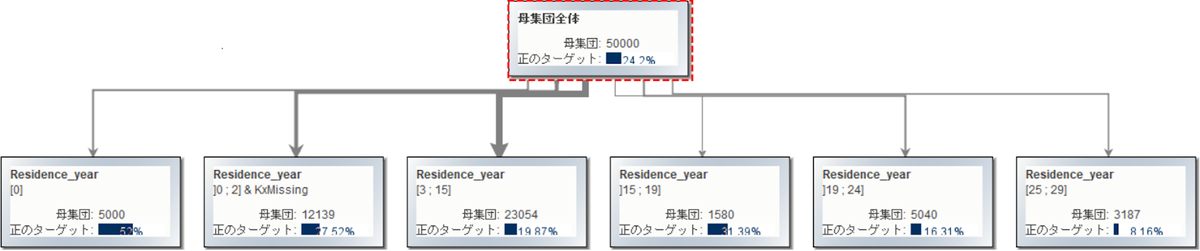
なお、SAP® Predictive Analyticsは、各説明変数ごとに点数づけし、「退職しやすさ」と「原因」をわかりやすくスコア化した「リスクスコアカード」の出力を行ったり、作成したモデルの予測精度を維持したまま人間の理解しやすい決定木状で出力する機能もあり、予測精度とモデルの解釈しやすさ(≒施策への転換しやすさ)を両立させることが可能です。

カテゴリ、連続値を問わず、データの分布に応じて説明変数が自動でビン分割され、それぞれが目的変数に与える効果を数値化しています。
弊社では、データ活用支援やコンサルティングを積極的に行っていますので、自社での機械学習導入を検討する場合には、ぜひご相談ください。
当社では、SAP® Predictive Analyticsをはじめ、独自性の強い海外製品を活用したデータ活用支援を積極的に行っています。ご興味のある方は、ぜひエントリーください!
www.brainpad.co.jp