
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。

目次
こんにちは、アナリティクスコンサルティングユニット所属の筒井です。
現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
1ヵ月程前にプロンプトエンジニアリングについてのレビュー論文が発表されました。そこで今回は、そのレビュー論文をメインとし、関連論文も交えながら昨今のプロンプトエンジニアリングを紹介していきます。
今回のテーマ
本ブログ読者に今更の説明は不要かもしれませんが、ChatGPTなどを始めとするLLMには通常の会話のように指示を出すことができます。そのような自然言語による指示を「プロンプト」と呼び、LLMをより上手に使うための”良い”プロンプトの書き方が、世界中で日々報告されています。そのようなプロンプトの構成の仕方は「プロンプトエンジニアリング」と呼ばれています。
社内のLLM論文レビュー会でも、新たなプロンプト手法が発表される度に共有されています。しかし「プロンプトエンジニアリングはまだ若い分野であるためかあまり体系化などが行われていない」かつ「1つのプロンプト手法だけだと文量的に一本の記事にしづらい」です。そのため、Platinum Data Blog での発表はこれまで少なめでした。しかし、昨今のプロンプトエンジニアリングをレビューした以下の論文が1ヵ月程前に発表されたため、今回はこの論文(以下)をメインに扱うことで、プロンプトエンジニアリングの基礎とその応用を紹介していこうと思います。
arxiv.org
上記論文が発表され、界隈ではプロンプトエンジニアリングがブームになりました。例えば弊社の田中がプロンプトエンジニアリングについて網羅的に調査し、その結果について纏めたQiitaの以下の記事もX(旧Twitter)で2.2万インプレッションという大きな反響を呼びました。
qiita.com
プロンプトエンジニアリングの網羅的な調査は上記記事で十分紹介されているため、本記事では具体的なプロンプトをたくさん紹介するということは避けます。代わりに「プロンプトエンジニアリングにおいて重要なことは結局のところ何なのか?」という問いに、本記事では焦点を当てていきます。具体的には、少数のプロンプトを例に挙げながら、基礎編と応用編に分けて説明していきます。
なぜプロンプトエンジニアリングが必要か?
「LLMの性能は何で決まるのか?」と聞かれたとき、皆さんはなんと答えるでしょうか。モデルの構造を決めるハイパーパラメータや学習データの品質など、多くのことが要因として考えられます。そしてもちろん、プロンプトの品質もその一つであり、ユーザー側で調整できる数少ない要因です。他の要因と比較した時、プロンプトエンジニアリングの特異性はその”コスパの良さ”です。なぜなら、モデルを再学習させることなく、LLMの性能を引き上げることができるからです(一般に学習には大きなコストがかかり、LLMに至ってはそれは並大抵ではありません)。Retrieval Augmented Generation (RAG) でも再学習することなくモデルの性能を上げることができますが、その前後の処理のためのプロンプトを書くことを考えると、プロンプトエンジニアリングはより根源的です。
プロンプトエンジニアリング:基礎編
性能を向上させるプロンプトは、以下の2つ(4つ)に分類できそうでした。(注:この分類はメイン論文で行われているわけではなく、本記事執筆者によるもの。)すなわち、以下の2つ(4つ)のことが「プロンプトエンジニアリングにおいて重要なことは結局のところ何なのか?」に対する1つの答えであると本記事執筆者は考えています。
- 文脈を曖昧さ無く伝えるタイプ
- ユーザーの要求を明確化するタイプ
- LLMの知識を引き出すタイプ
- ハルシネーション*1を抑えるタイプ
- 直列型:推論ミスを減らすタイプ
- 並列型:出力の堅牢さを高めるタイプ
抑えておきたい考え方
巷で話題の"技"の説明に移る前に、基礎のさらに手前である考え方について2つ言及しておきたいと思います。
明確に、正確に
大抵の場合、LLMは"答え"を知っています。なぜなら大抵のことは学習データに含まれているからです。しかし、LLMが"正しい答え"を出力するかどうかは別の問題です。なぜなら、LLMはこちらが何をして欲しいか何も知らないので、何が答えとして"正しい"のかも知らないからです。そこで、ユーザー側がLLMの返答を絞り込んでやる(文脈を絞り込んでやる)必要があります。その際、プロンプトを明確かつ正確に、詳しくすることで、文脈を曖昧さなく伝えることができるようになります。
ハルシネーションスノーボール (Hallucination snowball)
本記事でも「知っている、教える、伝える」など、LLMがさも人間かのように書いてしまいます。しかし、LLMはあくまで機械であり、物を考えているわけではありません。「これまでの文章」に繋げると「自然そうな文章」をただ生成しているだけに過ぎません。したがって、一度でも"嘘"を吐いてしまうと、それに矛盾しないよう嘘に嘘を重ねていきます ([2305.13534] How Language Model Hallucinations Can Snowball)。したがって、LLMの出力精度を向上させるためには、嘘を吐かせない/嘘の影響を抑える工夫が必要になってきます。
1.1 ユーザーの要求を明確化するタイプ
ここからは具体的な手法をいくつか眺めながら、上記の4分類が妥当そうなことを感じていこうと思います。
1つ目は「Role-prompting」です。有名なのでご存知の方も多いかもしれません。これは「あなたはAIの専門家です」のような役割を与えると、AI関連の話題に対する精度が向上するというものです。本記事執筆者は「役割を与えることで、文脈(ユーザーがLLMの出力として期待していること、LLMに行ってほしいタスク)が絞り込まれる」ことが効いているのではないかと考えています。言語化せずとも/できなくても、文脈を効率良く伝達できるのです。これは実務的には嬉しいです。なぜなら、プロンプトが短くできるということは、LLMが処理するトークン数が少ないので、LLMの使用料を安く抑えられるからです。
2つ目は「ユーザーの立場を示す」です。これはメイン論文内では紹介されていなかったのですが、LLM論文レビュー会で弊社の中島に「Role-prompting の逆」のようだと教えていただきました。具体的には「私はこの分野の素人です。私はデータサイエンティストです。」などと宣言するというものです。これも詳細な回答が欲しいというユーザー側の要求/文脈を明確化していると考えられます。
1.2 LLMの知識を引き出すタイプ
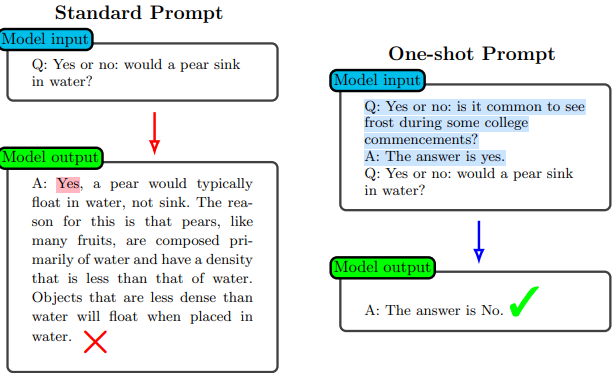
こちらは「One/few-shot prompting」です。こちらも有名で「回答例を1つ/数個つける」というものです。回答例をいくつ付けるかは、問題の複雑さに依るとメイン論文では説明されています。面白い点として、タスクによっては回答例を一つも付けない(Zero-shot prompting、つまり上図Standard Prompt)方が性能が良いようです。この理由として、著者らは「回答の仕方を例から学習している(メタ学習)わけではなく、回答例によってQ&Aという構造を思い出している、つまりLLMの知識を引き出している」からだと主張しています(ただしmight で書かれているため自信は薄いよう)。たしかに上図を見ると、Standard prompt では冒頭の Yes or no の意味(この文章の構造)が上手く伝わっておらず、単純に真似して冒頭にYes を付け、その後ハルシネーションスノーボールしているように見えます。
2.1 直列型:推論ミスを減らすタイプ
ここではLLMの推論が直線的になるものを紹介します。本記事中では直列型の手法と呼びます(一般的な呼称ではないことに注意してください)。
こちらの1つ目は「Chain of Thought (CoT)」です。こちらも有名で、派生形がたくさん報告されています。一番有名なものは「ステップバイステップで考えましょう」と書くというもの(特にZero-shot CoTと呼ぶこともある)ですが、目的の質問までの中間ステップを生成する質問をすること全般を指します。亜種としては、「具体的な思考のプロセスまでプロンプト中で設計しておく」というGolden CoT や、「画像などを含めた場合に同様のことを行う」というMultimodal CoT などが紹介されていました。CoT全般の利点として、推論の途中経過が見えるため、モデルがどのように考えたかをユーザーが追いやすいことが挙げられます(解釈性の向上)。本記事執筆者は「行間を狭くすることがタスクを簡単なものに分解することに対応しており、ハルシネーションを起きづらくしている」ことが精度向上に効いていると考えています。

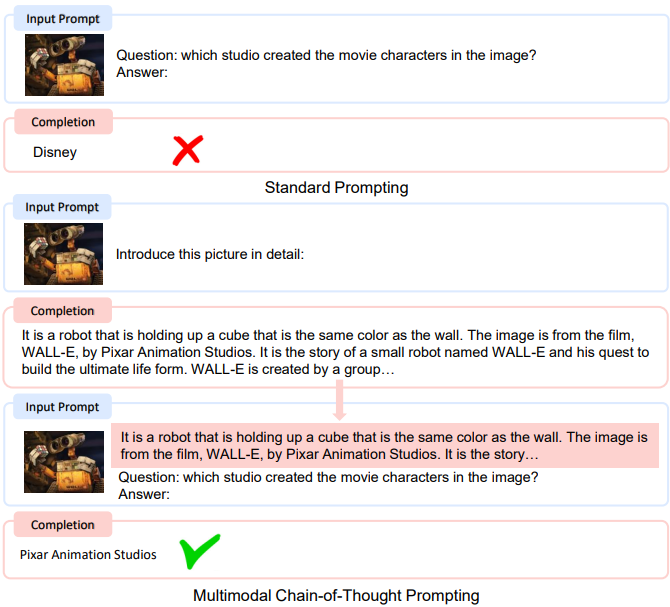
2つ目は「Generated Knowledge」です。こちらは「最初に前提や注意の必要な関連知識を書かせてからタスクに移る」というものです。関連知識を書かせることで、それらとの繋がりが自然になるように後続の文章を書こうとするため、精度が向上するのだと考えられます。

2.2 並列型:出力の堅牢さを高めるタイプ
ここではLLMの推論が複数になるものを紹介します。本記事中では並列型の手法と呼びます(一般的な呼称ではないことに注意してください)。
最も簡単なものとしては「Resampling」があります。これは同じ質問を何度か行い、その出力から最も良いものを探すというものです。LLMの出力は温度パラメータというもので制御でき、高温にすることで出力のランダムネスを強めることができます。ただし、高温にするとハルシネーションが発生しやすくなることも報告されているため、注意が必要です。
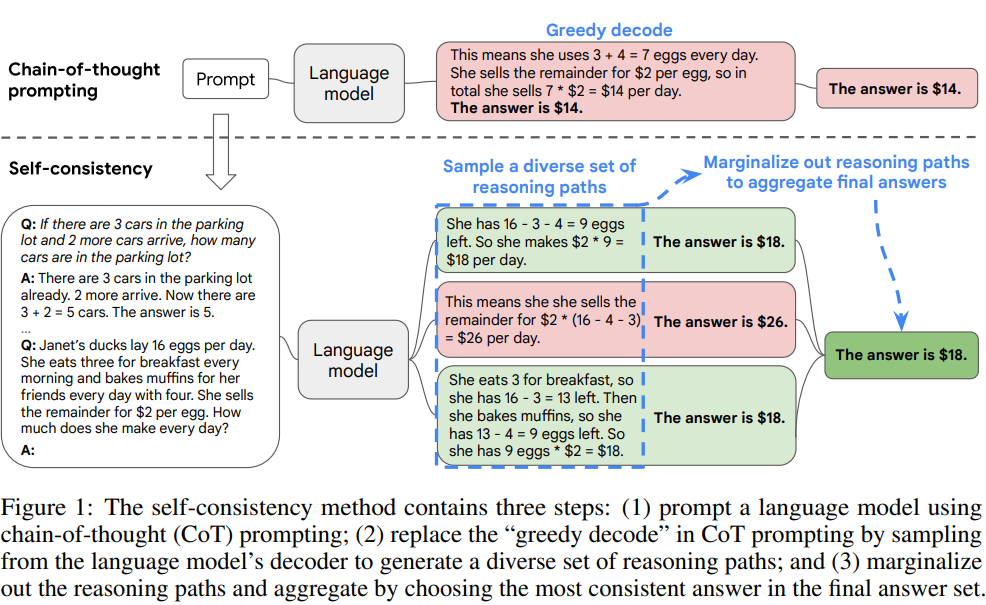
続いて「Self-consistency」です。これはLLMの一貫性を強化する手法で、主に二種類あるようです。1つは「LLMの出力の一貫性を監視するためのLLMを用意する」というものです。2つ目は「1つのLLMに何パターンか推論させ、多数決で最も一貫性のある出力を選ばせる」というものです。LLMは計算問題が苦手な傾向にありますが、Self-consistencyによって算数・常識・記号的推論の性能向上が報告されたようです。
「1つの推論パスにハルシネーションが混じっていても、他の推論パスに混じっていなければ、そのハルシネーションの影響を抑えることができる(堅牢になっている)」ことが、精度向上に効いていると考えられます。
プロンプトエンジニアリング:応用編
ここからは、基礎編で紹介した手法の応用や、少し毛色の違う手法について紹介しようと思います。
直列型&並列型のコンビネーション
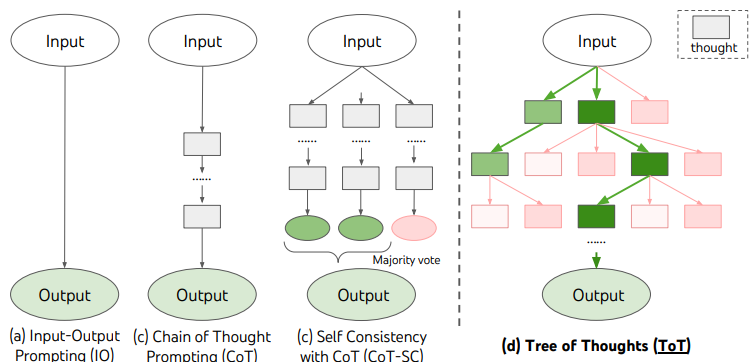
1つ目は「Tree of Thoughts (ToT)」です。この手法はSelf-consistencyに似ていますが、推論パスの途中で推論を更に分岐させるというものです。「直列型のハルシネーションの少なさ」かつ「並列型の堅牢さ」という良いとこどりで、精度が悪いはずがないというものです。パッと聞くと、そのような指示をどうやって行うのかと思いますが、役割を複数与えて(Roll-prompting)それぞれに議論させるということで実現できます(下図)。

2つ目は「Graph of Thoughts (GoT)」です。これは、ToTに対して更に「Aggregation (枝の合流)」と「Refining (枝を自分に戻す、推論を洗練させる)」ことを許したものです。ソート問題では、ToTより更に62%も性能が向上したそうです。

Program of Thoughts (PoT)

これはプロンプトを洗練することで性能向上を図るというもではなく、python のプログラムを書かせることで、苦手な計算を行わせようというものです。python による計算は決定論的で、推論を行うわけではないため、出力したプログラムが正しければ必ず正しい答えを返します。この手法により、論文著者らは全ての数学の問題用のデータセットでSoTAを達成したようです。
強化学習によるプロンプトの自動探索
arxiv.org
さて、ここまでいくつかの具体的な手法を眺めてきましたが、全ての手法は世界の誰かが閃いた方法です。しかし、閃いたプロンプトが最良のものであるかは不明ですし、閃くのを待つのも大変です。そこで、プロンプトを強化学習で探そうという仕事が、上記論文で行われています。その具体的な方法は以下です:
- まずLLMを2つ用意します(仮にLLM1, LLM2と呼びます)
- (LLM1) 初期プロンプトs0 として例えば「Let’s solve this problem step-by-step」などから始めます(ユーザー側が与える)
- (LLM1) 教師データ(question-answer set などが使われるよう)に回答させます
- (LLM2) 回答が間違っていた場合、なぜ間違えたかを考えさせます
- (LLM2) プロンプトの改善案を複数考えさせます(枝が分岐する)
- (LLM1) 改善されたプロンプトで、再び教師データに回答させます
- 「4」に戻ります
- 所定の深さまでプロンプトが改善したら、報酬を計算し、「2」まで戻って再探索します
- 最良のプロンプトが見つかります

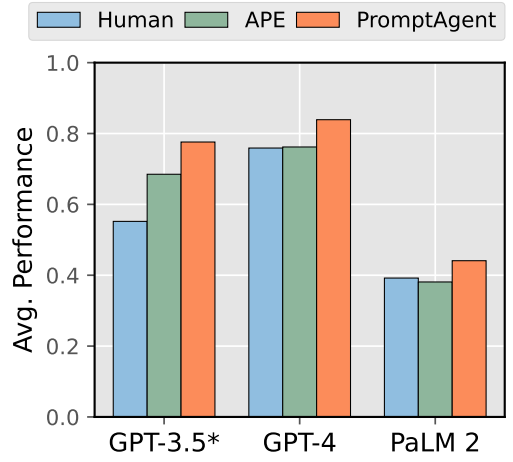
GPT3.5, GPT4, PaLM2 に対して、この強化学習によるプロンプトサーチが行われたようですが、その全てで上図のような性能向上が見られたようです。
まとめ
- プロンプトはLLMの性能に大きく影響するが、モデルの再学習が不要で"コスパ"が良い
- プロンプトエンジニアリングにはとても多くの手法が存在するが、それらの基本的なものは2つ(4つ)に分類できそうである
- 強化学習などによる、ベストプロンプトの自動探索も行われている
*1:Hallucination。日本語では幻覚、嘘を吐くなどと呼ばれる。LLMが正しくない結果を出力すること。