
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。

目次
- 今回のテーマ
- 論文1: Multimodal Foundation Models: From Specialists to General-Purpose Assistants
- 論文2: Tracking Anything in High Quality
- 論文3: MVDream: Multi-view Diffusion for 3D Generation
- 論文4: AudioPaLM: A Large Language Model That Can Speak and Listen
- まとめ
こんにちは、アナリティクスコンサルティングユニット所属の中島です。
以前の記事にもあるように、現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
第6回となる今回は、マルチモーダルのトピックで取り上げた4つの論文をご紹介させていただきます。
今回のテーマ
今回のテーマは、マルチモーダルです。
画像・動画・3D・音声に関する論文を1つずつ、計4つの論文を選定しました。
論文1: Multimodal Foundation Models: From Specialists to General-Purpose Assistants
選定理由
1つ目の論文は画像に関する論文です。
ここ数年の基盤モデルのマルチモーダリティの進歩は著しく、とりわけ画像関連の研究は盛んに行われており、非常に多くの手法が考案され手法間の関係性も複雑になってきています。
今回選出した論文は、Microsoftによる視覚(Vision)関連のマルチモーダル基盤モデルに関するサーベイ論文です。2023年7月までの重要手法が網羅的に分類・解説されているため、画像関連の基盤モデルの全体感や動向を把握するのに適した論文となっています。
論文概要
- 視覚に関するマルチモーダル基盤モデルの分類と進化の変遷についての包括的な調査結果を提供している
- マルチモーダル基盤モデルは、NLPと同様に傾向を持ち、特定のタスクに特化したスペシャリストから汎用的なエージェントへと進化してきている
- 特定タスクに特化したスペシャリストは視覚理解モデルと視覚生成モデルに分けられ、汎用的なエージェントは多様なタスクの統合モデルとLLMを活用したモデルに分けられる
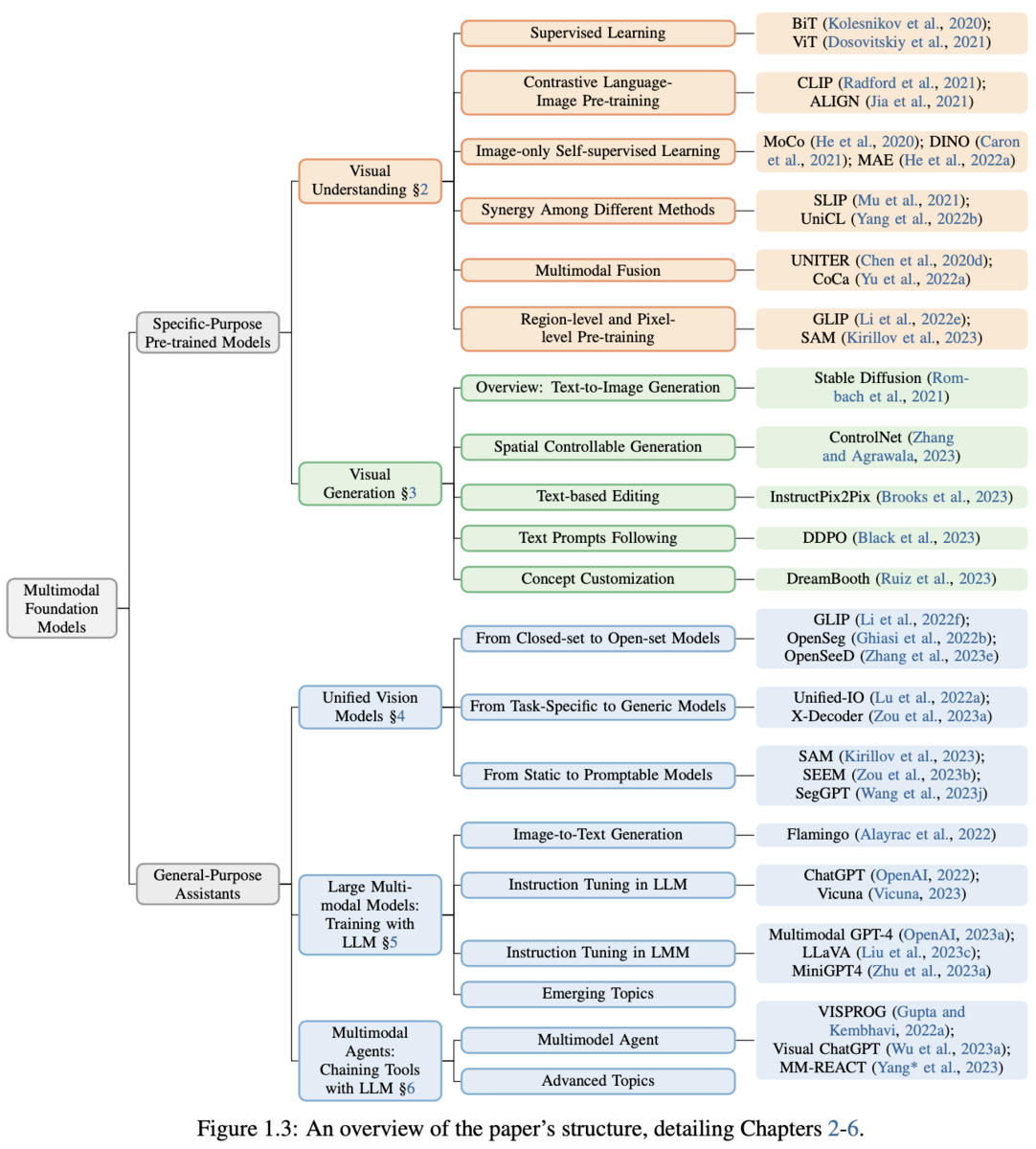
論文内では、(A)特定タスク特化のスペシャリストモデルを(1)視覚理解モデルと(2)視覚生成モデルに、(B)汎用的なエージェントを(3)多様なタスクの統合モデルと(4)LLMを用いてトレーニングしたモデル、(5)LLMとのチェーン可能なツールとしてのモデル、に分けて、各モデルの基本的な概念から、これまでの流れ、特性や課題、発展的なトピックまで詳細に解説されています。
マルチモーダル基盤モデルの分類
論文では各モデルを分類し包括的に解説していますが、一つ一つのアプローチを取り上げて解説するのは困難なため、紹介されている分類を表で整理しました。
気になる分類や手法がありましたら、本論文を参照して詳細を追っていただけますと幸いです。
| 大分類 | 中文類 | 概要 | 代表手法 |
|---|---|---|---|
| 特定目的のモデル(Specific-Purpose Pre-trained Models) | 視覚理解(Visual Understanding) | 画像レベル(画像分類・検索・キャプション)、領域レベル(検出・グラウンディング)からピクセルレベル(セグメンテーション)まで、様々なレベルでの画像理解モデル | CLIP, SAM |
| 特定目的のモデル(Specific-Purpose Pre-trained Models) | 視覚生成(Visual Generation) | テキストプロンプトからの画像生成モデル | DALL-E, Stable Diffusion |
| 汎用アシスタント(General-Purpose Assistants) | 統合モデル(Unified Vision Models) | 画像理解と画像生成の統合、視覚と言語の統合など多様なタスクを統合するアプローチ | GLIP, GPV |
| 汎用アシスタント(General-Purpose Assistants) | LLMとのトレーニング(Training with LLM) | LLMの能力をマルチモーダルに拡張しトレーニングするアプローチ | Flamingo, Multimodal GPT-4 |
| 汎用アシスタント(General-Purpose Assistants) | LLMとのチェーンツール(Chaining Tools with LLM) | LLMのツール使用能力を活用するアプローチ | Visual ChatGPT, MM-REACT |
マルチモーダル基盤モデルの流れと今後の展望
本論文では、下図で示す通り、マルチモーダル基盤モデルは言語における基盤モデルと同様に
- タスク特化のモデル(Task-Specific Models)
- 事前トレーニング済みモデル(Pre-trained Models)
- 統合モデル(Unified Models with Emerging Capabilities)
- 汎用アシスタント(General-purpose Assistants)
という変遷を経ており、現在は汎用アシスタントが構築されつつある段階にあると述べられています。

また、今後注目すべきトレンドについても言及されており、紹介されているトピックを表形式で整理しました。
| トピック | 概要 |
|---|---|
| マルチモーダリティを備えた汎用エージェント(Generalist agents with multi-modality) | 言語、視覚、音声、動作などの複数のチャネルを統合することで、人間と同じように世界を認識し対話が可能な汎用エージェントの構築に向けた取り組み。汎用エージェントが環境を理解する上で視覚は重要な要素となる。 |
| 人間とのアラインメント(Alignment with human intents) | 人間の意図した目的、価値観、倫理に向けてAIシステムを導く取り組み。人間の意図には言語や音声だけでは表現しきれない部分があり、視覚的な指示を組み込んでいくことは重要である。 |
| 計画、記憶、ツール利用(Planning, memory, tool use) | LLMを利用した自律エージェントシステムの構築に向けた重要な3つの要素。計画は実世界での複雑なタスクをどう実行可能なサブタスクに分解し処理していくか、記憶は短期記憶と長期記憶の両方をどう効率的に活用するか、ツール利用は目標達成に必要な基盤モデルに欠けている能力を補うために外部APIをどう使うか、がキーポイント。 |
レビュー会FB
Q: 近年のマルチモーダル基盤モデルの流れはどうなっているか?
- 特定タスクに特化したスペシャリストから汎用的なエージェントへと向かっている
- これは言語分野やAIにおける他の分野でも同じ傾向がある
関連論文
| タイトル | 概要 |
|---|---|
| Vision-Language Pre-training: Basics, Recent Advances, and Future Trends | 同じ筆者らによるビジョン-言語の事前トレーニング済みモデルについてのサーベイ論文 |
論文2: Tracking Anything in High Quality

選定理由
2つ目の論文は動画に関する論文です。
動画における物体追跡は、自動運転やロボットビジョン、スポーツアナリティクス、動画編集など広く応用が可能で技術であり、今後も進展していくであろう分野の1つです。
本論文で提案されている手法は、複数物体の同時追跡が高品質に可能であり物体追跡の大会(VOTS2023)でも好成績をおさめた手法のため、選出いたしました。
論文概要
- 物体追跡分野には、品質、複数同時追跡、急激な変化やフレームアウトや複雑な構造への対応、計算効率などの面で改善の余地がある
- 動画における複数オブジェクトを高品質に同時追跡できる新しいフレームワークであるHQTrackを提案している
- ビデオフレーム内の複数オブジェクトの同時追跡の役割を担うVMOSと得られたマスクを洗練する役割を担うMRを組み合わせることで追跡性能が向上し、VOTS2023チャレンジで2位を獲得した
課題背景
動画における物体追跡は、自動運転やロボットビジョン、スポーツアナリティクス、動画編集など多くの関連分野の基礎となる技術です。
物体追跡は深層学習の発展により大きな進歩を遂げ、最近ではTransformerを応用することで性能が大きく向上しています。しかし、長期に渡る追跡、ターゲットのフレームアウトへの対応、複雑な構造を持つオブジェクトへの対応、遮蔽物への対応など追跡が困難なケースもあります。
提案手法
HQTrackは、ビデオフレーム内の複数オブジェクトの同時追跡の役割を担うVMOSとVMOSから得られたマスクを洗練する役割を担うMRという2つのモジュールで構成されています。(下図参照)
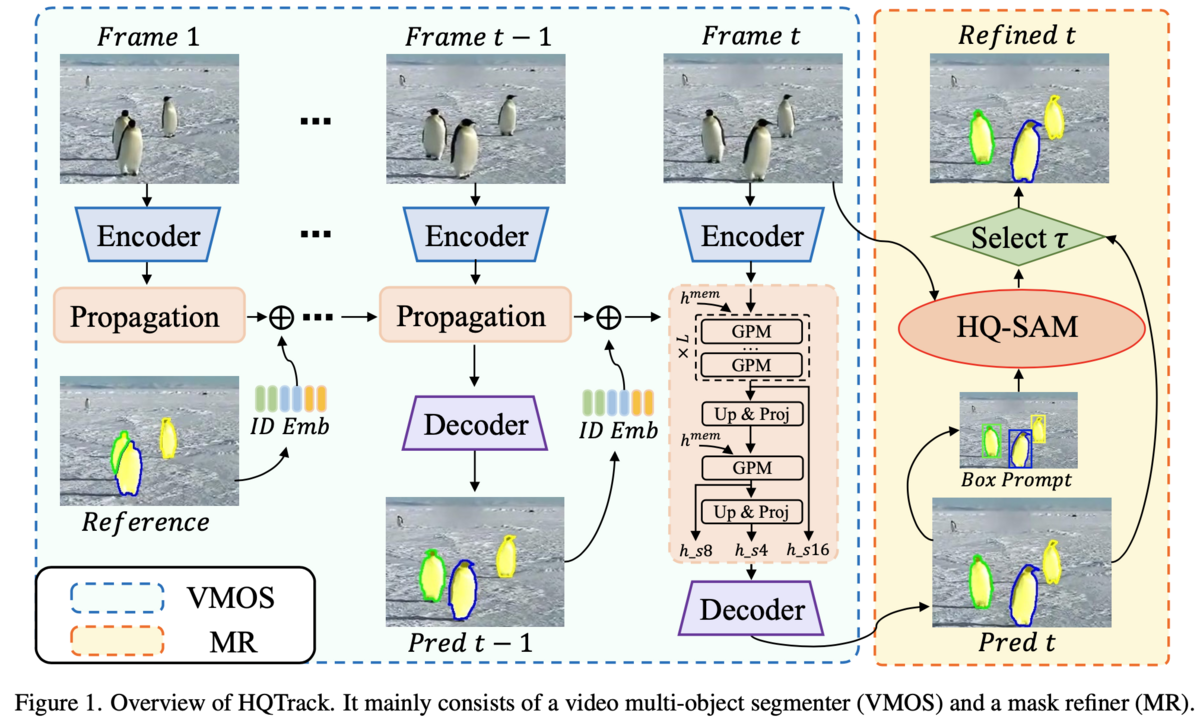
それぞれのモジュールを簡単に説明します。
Video Multi-Object Segmenter(VMOS)
VMOSはビデオフレーム間で複数オブジェクトのセグメンテーションマスクを伝播させる役割を果たします。

VMOSの機能
- オブジェクトのセグメンテーションマスクの伝播: ビデオフレーム間で複数オブジェクトのセグメンテーションマスクを効果的に伝播させ、オブジェクトの動きを追跡できます。
- 小さなオブジェクトの感知: GPMとマルチスケール伝播特徴を使用して、小さなオブジェクトも正確に感知し、セグメンテーションを実行できます。
VMOSの特徴
- DeAOTの後継モデル: VMOSは、ビデオオブジェクトセグメンテーションのためのモデルであるDeAOTの後継モデルです。
- Gated Propagation Module(GPM): 小さなオブジェクトをより効果的に感知するために、GPMを階層的に使用します。
- Intern-Tエンコーダ: オブジェクトの識別能力を強化するために、Intern-Tをエンコーダとして使用します。
- FPNデコーダ: デコーダにはシンプルなFeature Pyramid Networks(FPN)を用いています。
Mask Refiner(MR)
MRはVMOSのセグメンテーションマスクを洗練し、オブジェクト追跡とセグメンテーションをより正確にする役割を果たします。

MRの機能
- セグメンテーションマスクの改善: MRは、VMOSによって生成されたマスクを改善し、より正確なセグメンテーションマスクを提供します。
MRの特徴
- HQ-SAM: MRは、高品質なセグメンテーションマスクを生成するためにHigh Quality Segment Anything Model(HQ-SAM)モデルを使用します。
- ゼロショット学習: HQ-SAMは大規模なデータセットでトレーニングされており、多様なオブジェクトとシーンにゼロショットで対応可能です。
- マスクの洗練: VMOSからの予測マスクをHQ-SAMの入力として使用して、マスクを洗練させます。
- マスクの選択: VMOSとMRからのマスクのIoUスコア(物体検出で用いられる評価指標)を比較し、閾値に基づいて最終的なマスクを選択します。
レビュー会FB
Q: SAMはどこに応用されているか?
- MRの部分にSAMを応用したHQ-SAMが使われている
Q: 類似手法とは何が違うのか?
- 性能的な面では、マスクの品質とロバスト性が従来手法より高い
- 構造的な面では、VMOSでマスクを次のフレームに伝播させるだけでなく、MRを組み合わせてマスクを精緻化している点が異なる
Q: Optical Flowなどの古典的な手法は使われているか?
- Optical Flowはおそらく使われていない
- VMOSの元となっているモデルであるDeAOT(Decoupling Features in Hierarchical Propagation)およびAOT(Associating Objects with Transformers)では、Attention機構を活用してマスクの伝播を行っている
関連論文
| タイトル | 概要 |
|---|---|
| Decoupling Features in Hierarchical Propagation for Video Object Segmentation | VMOSの元となるDeAOTを提案している論文 |
| Associating Objects with Transformers for Video Object Segmentation | DeAOTの元となるAOTを提案している論文 |
| Segment Anything in High Quality | MRの元となるHQ-SAMを提案している論文 |
論文3: MVDream: Multi-view Diffusion for 3D Generation

選定理由
3つ目の論文は3Dに関する論文です。
3Dオブジェクトは現代のゲームやメディア産業において重要であり、通常は専門のデザイナーが何時間もかけて作成する必要があるため、AIによる3Dオブジェクト生成は価値のある研究領域です。
3Dオブジェクト生成にはいくつかのアプローチがありますが、本論文はその中でも最近注目されている2D生成モデルを3Dへリフティングするアプローチであるため、選出いたしました。
論文概要
- これまでの3D生成モデルでは、多視点での一貫性が取れない場合があるという課題があった
- テキストプロンプトから3次元的に整合性が取れた多視点画像を生成できるモデルであるMVDreamを提案している
- MVDreamを3D生成に応用することで従来手法より高品質な3Dオブジェクトが生成できる
課題背景
最近の3Dオブジェクト生成では、2Dを3Dにリフティングする手法が注目され、DreamFusionやMagic3Dといったモデルが登場し一定の成功を収めています。これらの手法は、損失関数を最適化することにより拡散モデルからのサンプリングを行う手法であるScore Distillation Sampling(SDS)と複数の2D画像から3Dオブジェクトを生成する手法であるNeural Radiance Fields(NeRF)を組み合わせています。
これらの手法は一定の精度のリアルな3Dオブジェクト生成が可能なものの、多視点での整合性が取れない場合や、視点によってオブジェクトが変動してしまう場合があるといった課題があります。
提案手法
本論文では、これらの課題を解消するために、3次元的に整合性の取れた多視点画像を生成する拡散モデルであるMVDreamを提案しています。

MVDreamの特徴
- 多視点データ: 3Dレンダリングされた多視点で一貫性を持つデータセットを使用します。
- 3D self-attention: U-Netに3D self-attention層を組み込むことで、視点間でギャップが大きい場合でも一貫性のある画像の生成が可能となります。
- カメラ埋め込み(Camera Embeddings): モデルが異なる視点の画像を区別するために、カメラパラメータを各視点に埋め込みます。
- 損失関数: 多視点画像とテキストプロンプトの一貫性を強化するために、多視点損失関数を定義しています。
- 3Dオブジェクト生成: MVDreamをDreamBoothのような手法に拡張することで、3Dオブジェクトの生成が可能です。具体的にはDreamBoothの拡散モデルをMVDreamに置き換えます。これにより3次元的に整合性の取れた高品質な3Dオブジェクトの生成が可能となります。
既存手法との比較
下図は、多視点画像の生成結果を既存の類似手法と比較した結果です。(下2段がMVDream)
MVDreamの結果は、どの視点からでも歪みやぼやけが少ないことがわかります。

また、下図はMVDreamを拡張したDreamBoothと、DreamBooth3Dにより生成された3Dオブジェクトの比較結果です。(下段がMVDream)
多視点画像の場合と同じく、MVDreamの方がよりリアルで歪みやぼやけが少ないことがわかります。

提案手法の課題
論文で言及されている課題は以下の通りです。
- 256×256のサイズの画像のみしか生成できない(オリジナルのStable Diffusionよりも小さい)
- モデルの汎用性がベースとなる拡散モデルに制限される
- モデルが生成できる画像のスタイルがレンダリングされたデータセットの影響を受ける
レビュー会FB
Q: 複製視点の整合性が取れたのか?
- 論文によると整合性は取れている
Q: 3Dレンダリングするモデルの精度に依存しそう
- 論文でも提案手法はベースモデルの精度やレンダリングされたデータセットに制限されると述べられている
Q: NeRFは使っているのか?
- 多視点拡散モデル自体には使われていなそうだが、3D生成時には使われている(論文中ではNeRFへの言及は少ない)
関連論文
| タイトル | 概要 |
|---|---|
| DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation | 提案手法が論文内で組み合わせて用いているDreamBoothを提案している論文 |
| DreamBooth3D: Subject-Driven Text-to-3D Generation | DreamBoothを3Dに拡張した手法であるDreamBooth3Dを提案している論文、提案手法の比較対象となっている |
| DreamFusion: Text-to-3D using 2D Diffusion | 3D生成モデルであるDreamFusionを提案している論文、提案手法の比較対象となっている |
| Magic3D: High-Resolution Text-to-3D Content Creation | 3D生成モデルであるMagic3Dを提案している論文、提案手法の比較対象となっている |
論文4: AudioPaLM: A Large Language Model That Can Speak and Listen
選定理由
4つ目の論文は音声に関する論文です。
選出した論文はGoogleが6月に発表した、テキストと音声の両方に対応可能な大規模な音声理解・生成モデルであるAudioPaLMについての論文です。
音声翻訳のベンチマークではOpneAIのWhisperを上回っており、今後の音声翻訳ツールのデファクトスタンダードにもなり得るモデルであるため、選出いたしました。
論文概要
- テキストと音声の両方に対応可能な大規模言語モデルであるAudioPaLMを提案している
- AudioPaLMはテキストベースのLLMであるPaLM-2と音声ベースのLLMであるAudioLMを統合したモデル
- 音声から他言語音声への翻訳、音声から他言語テキストへの翻訳、自動音声認識が高精度で可能となっている
- 話者のイントネーションなどの副言語情報も反映される
- 現在はデモページが公開されている
提案手法

AudioPaLMの機能
- 音声認識(ASR): 音声データをテキストデータに変換できます。
- テキストから音声への合成(TTS): テキストデータを音声データに変換できます。
- 音声から音声への翻訳(S2ST): ある言語の音声データを別の言語の音声データに変換できます。
- 音声からテキストへの翻訳(AST): ある言語の音声データを別の言語のテキストデータに変換できます。
AudioPaLMの特徴
- モデル構造: PaLMベースのデコーダのみのモデルです。
- Pre-trainingとFine-tuning: テキストベースのLLMであるPaLM-2で事前トレーニングを行い、音声とテキストの両方を含むデータでFine-tuningされます。
- トークンの拡張: モデルのトークン辞書を音声波形を表すアコースティックなトークンに拡張し、テキストトークンと音声トークンを同じembedding空間にマッピングされます。
- ゼロショット学習: トレーニング中に見られなかった音声入力/ターゲット言語の組み合わせを持つ音声翻訳が実行できます。
- 単一のアーキテクチャ: 音声認識、テキストから音声への合成、音声から音声への翻訳など、異なるタスクを単一のアーキテクチャで実行できます。
- 副言語情報の保持: 話者のイントネーションなどの副言語情報を保持できます。
既存手法との比較
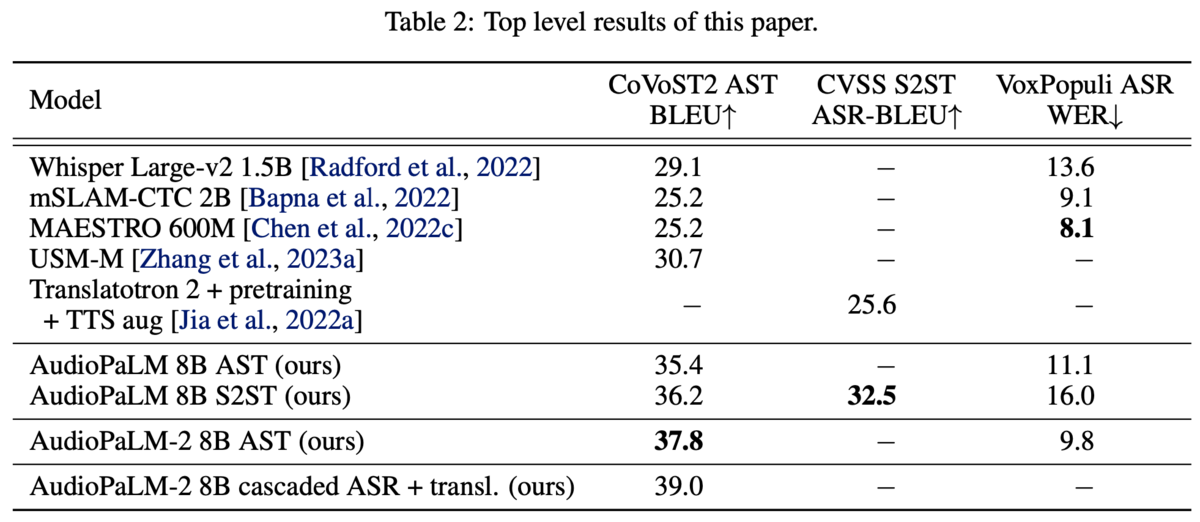
下表の通り、音声翻訳(AST)・音声認識(ASR)において既存手法を大きく上まっていることがわかります。
提案手法の課題
論文で言及されている課題は以下の通りです。
- オーディオ生成のクオリティは、オーディオトークナイザーの質に依存する
- 凍結ではなくモデル全体をfine-tuningする必要がある
- オーディオトークンやオーディオ生成タスクの評価ベンチマークには研究・改善の余地がある
レビュー会FB
Q: GoogleからAPIで提供されてるのか?
- デモは公開されているが、おそらくAPIとしてはまだ提供されていない
Q: 日本語には対応しているか?
- デモでは日本語の音声認識と日本語→英語の翻訳はあるが、他言語→日本語のデモはないため、どの程度対応しているのかは不明
- デモを見る限りでは日本語のクオリティは高くはなさそう
関連論文
| タイトル | 概要 |
|---|---|
| PaLM 2 Technical Report | GoogleのテキストベースのLLMであるPaLM2についての論文 |
| PaLM: Scaling Language Modeling with Pathways | GPaLM2の元となるPaLMについての論文 |
| AudioLM: a Language Modeling Approach to Audio Generation | Googleの音声ベースのLLMであるAudioLMについての論文 |
| Robust Speech Recognition via Large-Scale Weak Supervision | OpenAIの音声処理モデルであるWhisperについての論文 |
まとめ
今回は、生成AI・基盤モデルのマルチモーダリティに関する技術論文を4つご紹介させていただきました。
今後も、社内で実施しているレビュー会での発表内容をブログで発信させていただくつもりですので、ご期待ください。