
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
今回は、ChatGPTなどで好ましい応答を得られるように、人間からAIモデルの応答に働きかける、ヒューマンフィードバックというプロセスを支援する「Transformer Reinforcement Learning(TRL)」という強化学習ライブラリを紹介します。

こんにちは。アナリティクスサービス部の橋本です。
ChatGPTの学習プロセスとして取り入れられているRLHF(Reinforcement Learning from Human Feedback、人間のフィードバックによる強化学習)という手法の導入を支援するツールについて紹介します。
RLHFは人間好みの応答ができるように、元となる大規模言語モデル(Large Language Model, LLM)を微調整(ファインチューニング)する手法です。
この手法では、好ましい応答を得られるように、人間から言語モデルの応答に働きかける、ヒューマンフィードバックが必要となりますが、データセットの作成やプロセスの実装を自力で実施するのは容易ではありません。
そこで、今回はこのプロセスを支援するTRL、trlX、Argillaといったツールを取り上げます。
それぞれのツールの紹介に移る前に、まずはRLHFという手法について、簡単に概要をまとめていこうと思います。
RLHFとは
RLHFの目的は、GPTに代表されるLLMの応答を、より人間の好みの応答になるようにファインチューニングすることにあります。
「素」の言語モデルは、人間とのコミュニケーションに特化した学習はされていませんから、差別的な応答をしてしまったり(有害性)、事実でない情報をあたかも事実であるかのように語ったり(真実性)、人間の意図した自然な応答を返さなかったり(有益性)します。
したがって、単に言語モデルを大規模にするだけでは、人間にとって真に役立つツールとはならないのです。
「AIと自然なコミュニケーションを楽しみたい」とか「AIに仕事のアシスタントとして情報のキュレーションをしてもらいたい」というようなニーズに応えるためには、人間がどういう応答を好むのかをLLMに理解させる必要があります。
そこでGPTモデルやChatGPTを生み出してきたOpenAIは、RLHFという強化学習を用いた手法を開発しました*1。
ここで、強化学習とは機械学習の手法の1つです。仮想の学習者を立てて、その学習者が解きたい課題にトライし、試行錯誤をする中で徐々に課題の最適な解き方を学習していくというプロセスになります。強化学習の解説は本ブログでも過去に取り上げたので、興味があればご覧ください*2。
では、RLHFではどのような過程でLLMをファインチューニングしていくのでしょうか。
それは以下に示す3つのステップからなります。
- ステップ1:用意した複数のプロンプト(指示文)に対して、それぞれ人間が応答文を用意し、それを教師データとすることで既存のLLMに対して教師あり学習を実施
- ステップ2:ステップ1で用意したモデルを使って報酬モデルと呼ばれる「AIが生成した応答文の人間好み度を評価する」関数を作成
- ステップ3:ステップ2で用意した報酬モデルを使うことで、AI自らが「プロンプトに対して現状のモデルから応答文を生成 → 人間好み度の評価 → 学習結果をもとにモデルを更新 → プロンプトに対して現状のモデルから応答文を生成→...」というループを実行することで強化学習を実施
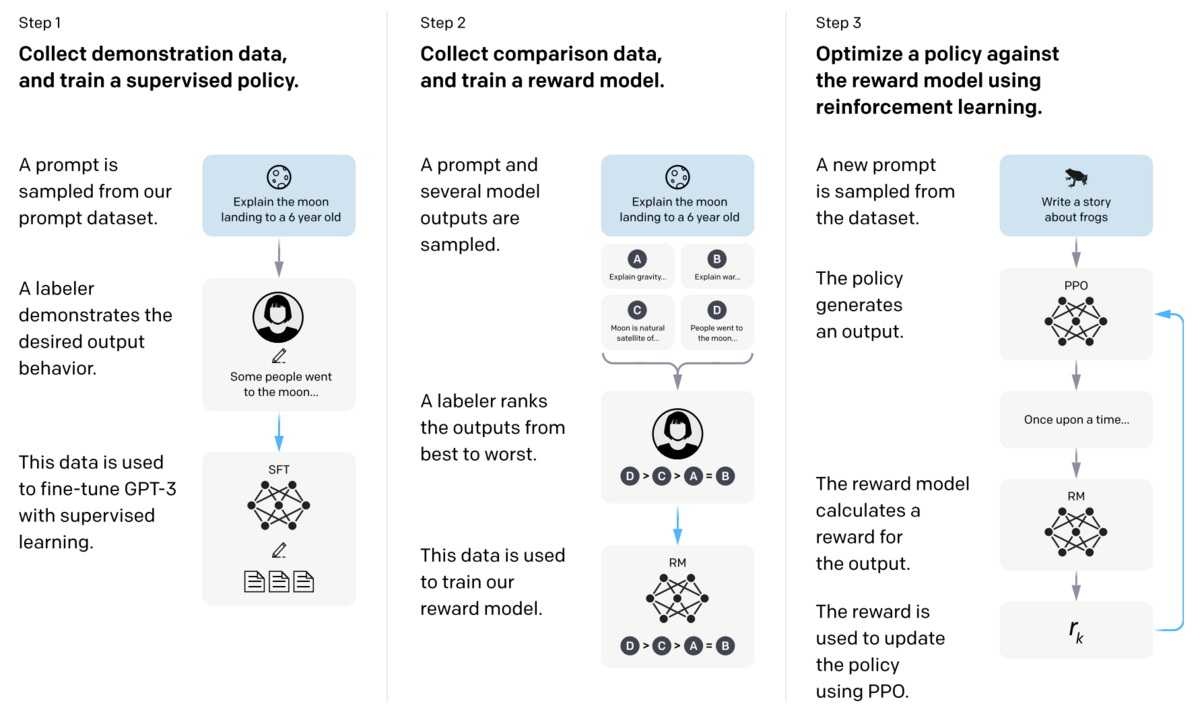
ここで述べたRLHFについて、より詳細を把握したい方は、こちらの記事で各学習ステップの内容や強化学習アルゴリズムの説明を取り扱っているので、ぜひご覧ください。
ツールの紹介
今回の記事では、TRL、trlX、ArgillaというPythonライブラリあるいはデータプラットフォームについて紹介します。
TRLとtrlXはともにHugging Faceライブラリであり、ヒューマンフィードバックの情報を含んだデータセットを用いた学習による、LLMのファインチューニングをサポートする分散学習フレームワークです。
一方で、Argillaはそうした学習によるファインチューニングを実行するだけでなく、ヒューマンフィードバックに必要なプロセス全体をサポートするプラットフォームです。
以下でそれぞれのツールについて概要や特色をまとめました。
TRLとtrlX
TRLは、GPT-2などのトランスフォーマー言語モデルのPPO (Proximal Policy Optimization)*3アルゴリズムによる最適化をサポートします。Hugging Faceのアカウントを取得することで、公開されているヒューマンフィードバックのためのデータセットや学習済みモデルにアクセスしたり、自作のデータセットを共有したりできます。
trlXは、CarperAI*4が提供するPythonライブラリで、GPT-NeoXなどの言語モデルについて、200億パラメータの規模までのファインチューニングをサポートしています。
TRLとtrlXの相違点の1つは、利用可能な強化学習アルゴリズムが異なることです。TRLはPPOアルゴリズムのみの利用ですが、trlXはPPOに加えてImplicit Language Q-Learning (ILQL)も利用可能です。
学習に必要なデータセット
この2つのライブラリを使用する場合、学習時に人間のフィードバックを反映するためのデータセットが必要となります。
- 教師あり学習に必要な「プロンプト+応答文+採用の可否(その応答文をよしとする可能か)」のデータセット
- 報酬モデル作成時に必要な「プロンプト+応答文+応答文のスコア」のデータセット
1例として、こちらの記事(LLAMAモデルをRLHFによってファインチューニングするチュートリアル)が参考になります。
TRLにおける強化学習
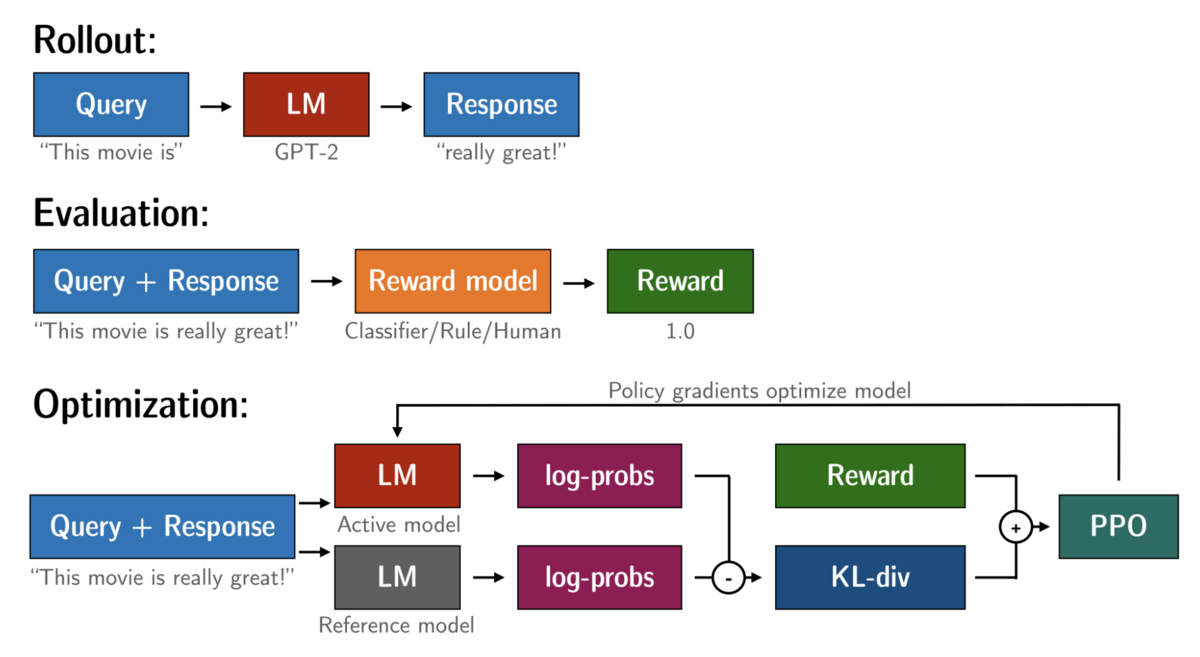
図2はTRLにおける学習に必要な3つのフレームワークを表しています。
1: Rollout
Rolloutはワーカー(強化学習時に行動を決定し環境に作用する主体、ゲームのプレーヤー)の行動過程を示しています。
"Query"(プロンプト)を受け取ったワーカー(言語モデル、ここではGPT-2)は何かしらの"Response"(応答文)を返します。
2: Evaluation
Evaluationは、ワーカーが作成した応答文を(Reward model)報酬モデルで評価し、"Reward"(報酬)を返す様子を示しています。
3: Optimization
Optimizationは、PPOアルゴリズムを利用した強化学習を実行することでモデルを最適化する様子を表しています。
適用例
日本語に特化した大規模言語モデルの開発
まず、rinna株式会社が開発した日本語特化のLLMを紹介します。
公式のプレスリリースにある通り、GPT系列の言語モデルであるGPT-NeoXをもとにしており、36億パラメータの汎用言語モデルと教師あり学習による対話言語モデル、さらにRLHFによる対話言語モデルの3種類をオープンソースで公開しています。
また、RLHFによる対話言語モデルはHugging Face上で商用利用可能なライセンスで公開されています。*5。
教師あり学習とRLHFによる2つの言語モデルによる応答を人間が判断(評価者がどちらのほうがより好ましいか、あるいは差がないかを選択)し、好ましいと判断される割合を比較すると、RLHF良しが47%、応答に差はないが31%、RLHF悪しが22%となり、RLHFがより好ましい応答を生成できると評価されました*6。これはOpenAIが実施したような既存の研究*7と同様であり、強化学習を取り入れたほうがモデルの性能が改善する結果となりました。
なお、強化学習には「日本語のプロンプトと応答」+「応答の良し悪しのラベル」からなるデータセットを用いています。こちらはHugging Face上に公開されていることから、誰でも利用することができます。
対話型モデルについては、もちろんチャットツールとして活用することができますし、汎用言語モデルについては、特定の利用目的に対して最適化させることによって、日本語ベースの特定用途特化モデルを作成することができます。
rinna社が開発した各言語モデルはこちらから参照できます。
また、その他の例として、日本語の感情データセットWRIMEを用いた実装例もあります。
以上が、TRLとtrlXの紹介になります。これらのライブラリは、教師あり学習や強化学習自体をローコードで実装できることが売りで、それら学習に必要なデータセットについては、既存の使えるデータセットを探し出すかそうでなければ自力でなんとかしなければいけません。
しかし、膨大な量の「プロンプト+応答文」をデータセットを用意することや応答文のスコアを逐一評価して報酬モデルを作成することが容易でないことは想像に難くありません。そこをサポートしてくれるツールが次に取り上げるArgillaです。
Argilla
Argillaは、RLHFのプロセスをより手軽かつ柔軟に実行するためのオープンソースデータプラットフォームで、単に作成済みのデータセットを使ってRLHFを実行するだけでなく、データセットの作成自体もサポートしています。
自分好みのLLMを作る際に最も面倒なプロセスは、「プロンプト→応答文」などの入出力のデータセットや報酬モデルを作成する際の応答文へのランク付などの作業になります。
作業自体だけでも面倒なことに加えて、このような学習プロセスは通常、一定規模のチームを構成して実施されることが想定されることから、データマネジメントも厳密に行わなければなりません。
そうした実際上の課題を少しでも緩和してくれるのが、このArgillaの役割です。
ArgillaのUI
教師あり学習によるファインチューニング
教師あり学習によるファインチューニングでは、プロンプトの適切に収集しデータセットの作成することに加え、担当者によるプロンプトへの応答文の作成が必要となります。
まず、プロンプトの作成ですが、次の3つの方法が利用可能です(詳しい記述はこちらをご覧ください)。
- 人力で作成する
- オープンデータセットを利用する
- LLMに作成させる
Argillaにおけるデータセットのセットアップについては、以下のようにArgillaのPython SDKを利用して設定することができます。
import argilla as rg questions = [ rg.TextQuestion( name="completion", title="Please write an accurate, helpful, and harmless response to the prompt", required=True, ) ] fields = [ rg.TextField(name="prompt", required=True), ] dataset = rg.FeedbackDataset( guidelines="Please, read the prompt carefully and write a response", questions=questions, fields=fields )
上記のような形でプロンプトが実行されると、UIを通して、各担当者に設定に応じたプロンプトデータセットの割り振りが行われ、担当者は以下のような画面で応答文の回答や品質チェックなどを実施することができます。応答文の品質は教師あり学習の結果に大きな影響を及ぼすので、注意深く作業を進める必要があり、Argillaはそこもサポートしてくれます。
例えば、複数の担当者間で同一のプロンプトに対する応答文を用意し、担当者全員による投票で最も質の良い回答を決定することができます。
詳しくはこちらのページを参照してください。
報酬モデリング
報酬モデルはRLHFにおける強化学習に不可欠な要素ですが、その作成は教師あり学習時のデータセット同様、作成が一筋縄ではいきません。
基本的には、1つのプロンプトに対して、複数の回答を教師あり学習済みのLLMに生成してもらい、人間がそれらをランク付します。
Argillaでは、これら一連の作業に対して、非常にローコードで統一された作業環境を提供してくれます。報酬モデリングに必要なデータセットを作るには以下のようなコードを実行します。
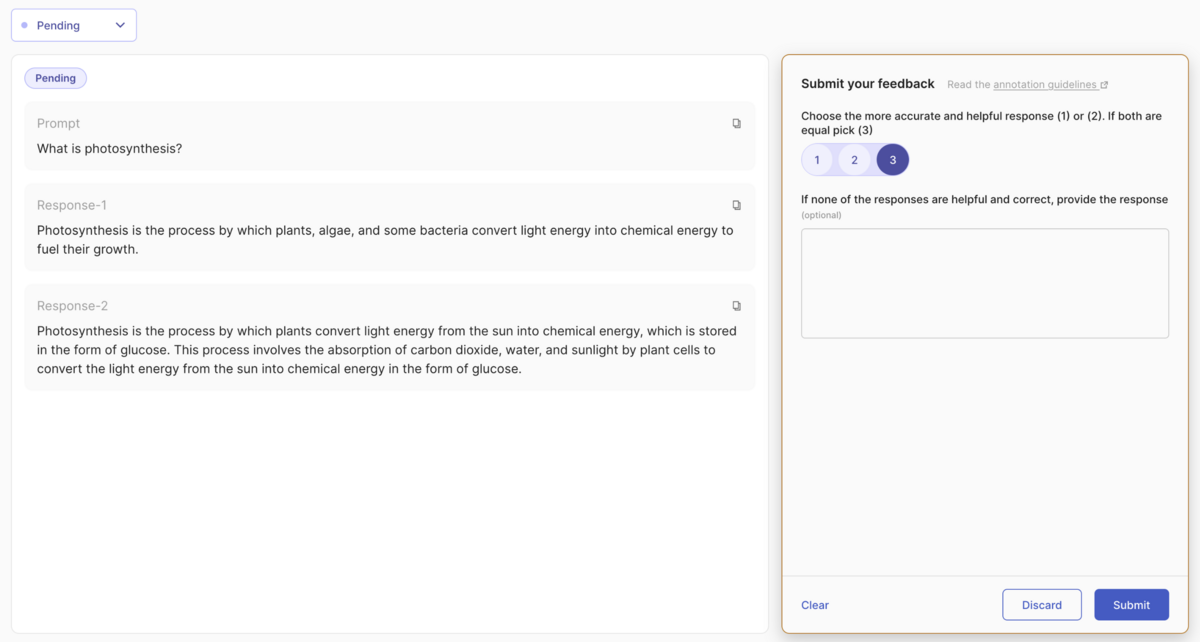
import argilla as rg questions = [ rg.RatingQuestion( name="response_ranking", title="Rank the responses\n1: first response is better,\n 2: second response is better,\n3: both are equal", required=True, values=[1, 2,3] ), rg.TextQuestion( name="correct_response", title="If none of the responses are helpful and correct, provide the response", required=False ), ] fields = [ rg.TextField(name="prompt", required=True), rg.TextField(name="response-1", required=True), rg.TextField(name="response-2", required=True) ] dataset = rg.FeedbackDataset( guidelines="Please, read the prompt carefully and...", questions=questions, fields=fields )
この例では、単一のプロンプトに対して、教示あり学習済みのモデルを利用して"response-1"と"response-2"の2つの回答を生成させています。
まとめ
今回の記事では人間(モデル作成者)好みのLLMを生成できるRLHFをサポートするライブラリやプラットフォームを紹介しました。 現在、ChatGPTのような人間の作業を補助・代替してくれるAIツールはまさに日進月歩の進化を続けています。特に日本においては従来のコンプライアンスへの意識から、自社データに特化した対話型言語モデルの需要は大きそうです。 この記事では、そのようなモデルの生成を支援するTRL、trlX、Argillaといったツールを紹介しました。 現状では、このようなツールを使用しても満足のいく対話型言語モデルを作ることはなかなか容易なことではないとは思います。しかし、現状のモデル生成周りの発展の仕方を見ていると、今ある障害はすぐに突破されるのではないかとの期待感は強いです。 当社では今後も引き続きこの分野を注視して、継続的にキュレーションした情報の公開を実施するとともに、実際に応用した結果についても共有していければと思っています。*1:https://openai.com/research/learning-from-human-preferences
*2:https://blog.brainpad.co.jp/entry/2017/02/24/121500
*3:強化学習アルゴリズムの1つで、OpenAIが開発した。TRPOという方策勾配法の1つから派生し、シンプルな実装に加えて学習効率が良いことで知られる。
*4:オープンソースのAI研究を実施しているコミュニティ"EleutherAI"から派生した研究者チームで構成される組織。
*5:rinna、人間の評価を利用したGPT言語モデルの強化学習に成功|rinna株式会社
*6:人間だけでなく、ChatGPTにも応答の良し悪しを判断させており、それぞれ63%、3%、34%でやはりRLHFのほうが良いスコアとなっています
*7:例えば、InteructGPTの論文を参照。