
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
今回は、Google から提供されているLLMやGenerative AIサービスのうち、直近にリリースされた各サービスの紹介と、それらの基盤となっている新しいモデルの一つ「PaLM2」をFine-Tuningする方法を紹介します。

こんにちは。アナリティクスサービス部の安田です。昨今、LLMやGenerative AIが大きな注目を集めていますが、Google からもそれらを利用するためのさまざまな機能・サービスが提供されています。今回は直近リリースされた各サービスの紹介と、それらの基盤となっている新しいモデルの一つである「PaLM2」をFine-Tuningする方法について紹介したいと思います。
※本記事は6/19時点の情報に基づいて記載しています。各種機能は今後も追加やアップデートが行われていくと思われますので、最新の情報にご注意ください。
Google が発表したGenerative AIのサービスについて
Google が提供している基盤モデルについて
昨今、LLMやGenerative AIといえば、こちらが入力したテキストに対してテキストでの返答がある、いわゆるチャットbotを想起される方が多いと思います。
しかし、最近は画像や音声など様々な形式を扱えるAIについても関心が集まっており、それらはマルチモーダルと呼ばれています。blog.brainpad.co.jp
そして、Google からもこれらマルチモーダルタスクを扱うための、いくつかの基盤モデルが発表・公開されているのでまずは簡単に紹介します。詳細についてはこちらの記事をご覧ください。
また利用方法については後述しますが、これらのモデルを扱うためのAPIも提供されています。
そのため、ユーザーは実施したいタスクにあわせたモデルを簡単に実装できます。
| モデル名 | 扱えるタスク | 備考 |
|---|---|---|
| PaLM2 | テキスト → テキスト | チャットbot「Bard」などに利用されている |
| Codey | テキスト → コード | |
| Imagen | テキスト → 画像 画像→テキスト など |
今後一般公開される予定 |
| Chirp | テキスト → 音声 音声 → テキスト |
現在はpreview版で公開 |
「Vertex AI Model Garden」と「Generative AI Studio」
Google Cloud における機械学習プラットフォームであるVertex AIでは、上記のモデルが利用できるサービスとして、「Vertex AI model garden」、「Generative AI Studio」が一般公開になっています。
Vertex AI Model Gardenでは、上記のモデルだけではなく、「BERT」や「YOLO」などのオープンソース・サードパーティを含めた様々な機械学習モデル、およびそのAPIが公開されています。
そのためユーザーはその中から自分の目的にあったモデルを検索・選択できます。
また、各モデルのAPI利用方法や Google Colab でのチュートリアルが用意されているため、ユーザーが手軽にそれらのモデルを利用する環境が整っています。
Generative AI Studioでは、UI上で基盤モデルを簡単に利用することができます。
また、UI上でテストした内容のコードも取得することもできるので、単純にテストするだけではなく、それをスムーズに実装することも可能です。
現在は、「言語」と「音声」に関して利用することができます。
※「画像」に関しても今後公開されていくと思われます。
「言語」では、PaLM2とCodeyの利用が可能です。
例えば、入力した文書の要約やポジネガ判定、コード生成などが可能です。
またユースケースごとにプロンプトの例が準備されているので、それを改変することでスムーズな実装が可能になっています。こちらの使用方法・使用感については後述します。
「音声」では、Chirpモデルを利用し、テキスト読み上げや音声文字変換を行うことができます。
テキスト読み上げでは、自身が入力したテキストを自然な発音で読み上げさせることができます。
また音声文字変換は、音声ファイルをアップロードすることで、その内容の書き起こしが可能です。
PaLM2 APIの紹介
ここでは上述の基盤モデルの中でも、特にPaLM2とそのAPIについて紹介します。
現在は、大きく分けて2つのPaLM2を利用したサービスがあります。
1. テキスト生成
2. エンベディング生成
テキスト生成ではユーザーの入力したテキストに応じた回答をテキストで返します。
一方で、エンベディング生成では入力した単語や文章などのテキストの意味合いをできるだけ保持したまま、数値ベクトルに変換することができます。
ここからは1のテキスト生成についてAPIの使い方を紹介します。
PaLM2 APIは「Vertex AI model garden」、「Generative AI Studio」のどちらからでも利用できます。
今回は「Generative AI Studio」からの利用を確認しましょう。
Vertex AIのコンソールページからGenerative AI Studio -> 言語をクリックすると、次のような画面に遷移します。
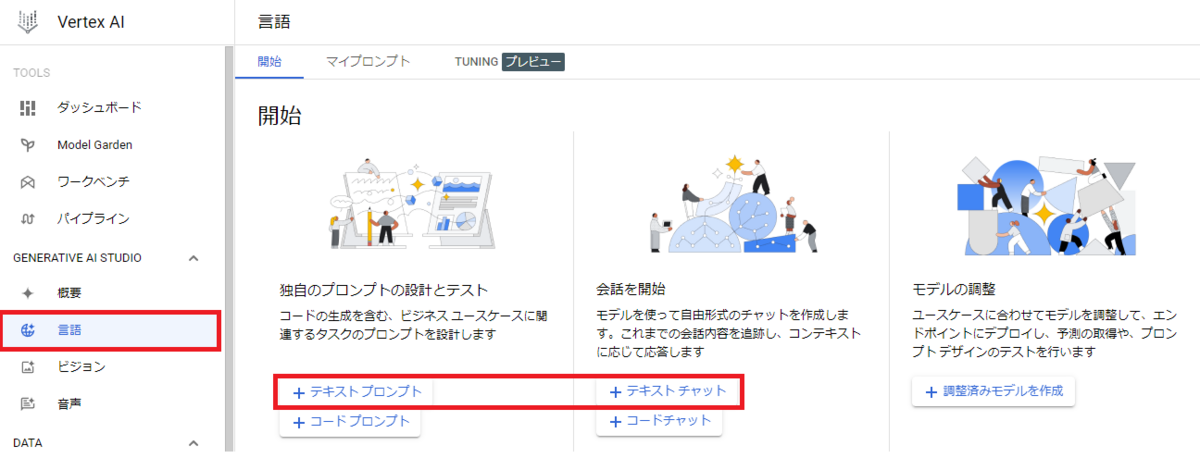
「言語」では、現在PaLM2を使ったテキスト生成とCodeyを使ったコード生成が行えます。またそれぞれに対して、プロンプトベースかチャットベースかを選べます。
| 機能 | 概要 | ユースケース | API | モデル |
|---|---|---|---|---|
| テキスト プロンプト | ユーザーとAPIの間で一度に限ったやり取りが可能 | 文章の要約やポジネガ判定など | PaLM 2 for Text | text-bison@001 |
| テキスト チャット | ユーザーとAPIの間で複数回のやり取りが可能 | チャットボットの作成など | PaLM 2 for Chat | chat-bison@001 |
| コードプロンプト | ユーザーの入力に対応するコードを作成 | 必要な処理が明確化しており、そのサンプルコードが欲しい場合など | Codey for Code Generation | code-bison@001 |
| コードチャット | 会話形式でのコード作成やその質疑対応が可能 | 生成されたコードに対して説明が必要な場合など | Codey for Code Chat | codechat-bison@001 |
現在PaLM2 APIはテキスト用の「PaLM 2 for Text」とチャット用の「PaLM 2 for Chat」の2つが公開されており、それぞれ使われているモデルも異なります。
ここではPaLM 2 for Textをテストしてみたいので、上記赤枠のテキストプロンプトをクリックしてみます。すると次の画面に遷移します。
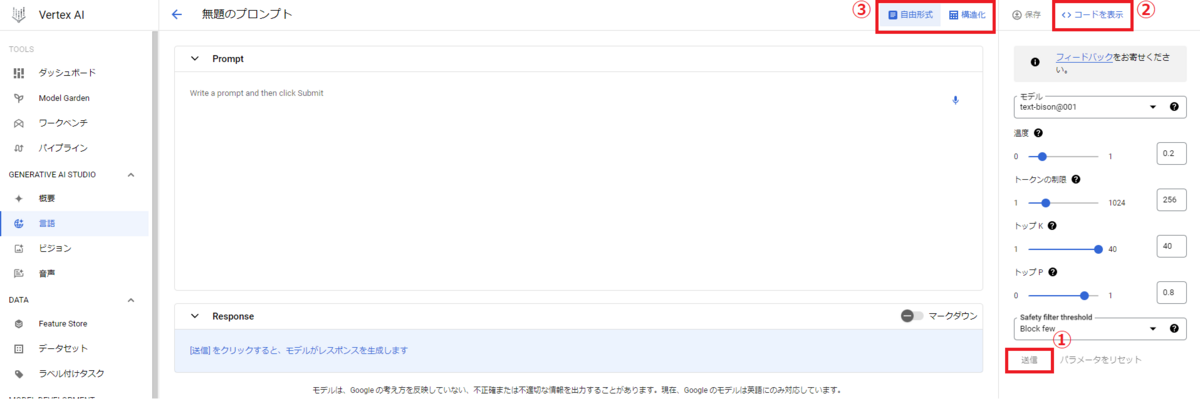
この画面では、真ん中の「Prompt」部に好きな入力を入れ、①の送信を押すことで、モデルにレスポンスを生成させて、PaLM 2 for Textを手軽に利用することができます。
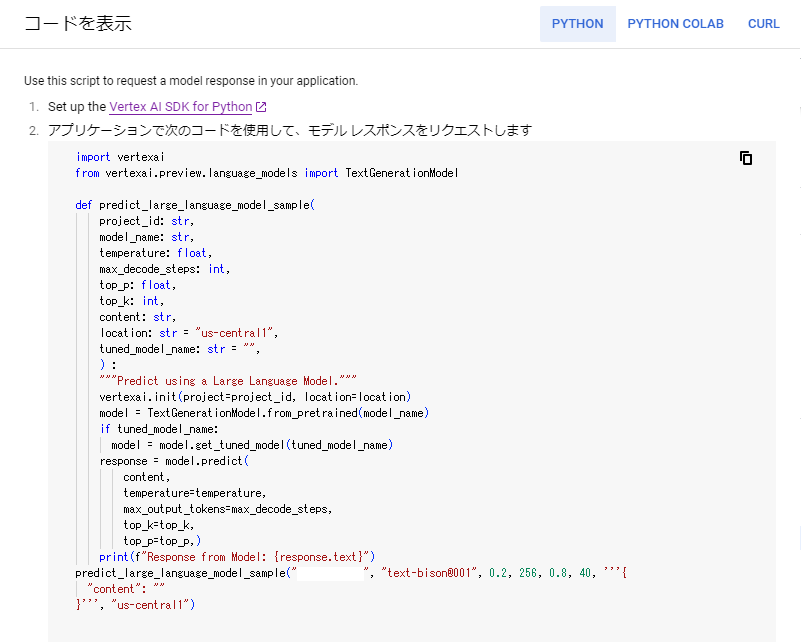
②「コードを表示」をクリックすると、現在入力しているPromptと設定しているモデル、パラメータを引き継いだまま、python、Google Colab 上のpython、Curlで実行するためのコードを表示することができます。
これを利用することで、UIでテストした内容をそのまま実装することができます。
また、③の構造化タブをスイッチすると、モデルに対して知って欲しい情報やどのように応答してほしいかを明確に指定した上で、レスポンスを生成することができます。
これにより学習データに入っていない情報についても、ある程度モデルに対応させることができます。
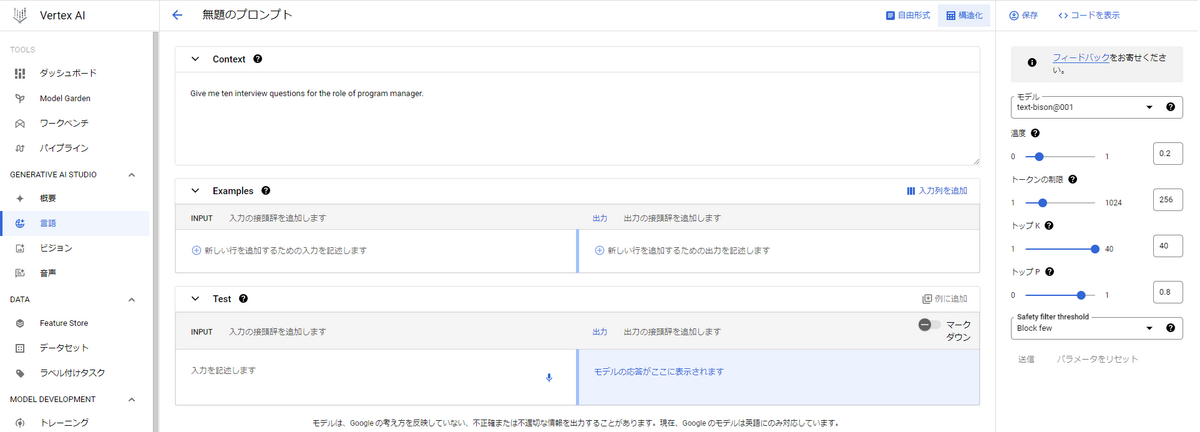
- Context
- モデルがレスポンスを生成するうえで、前提として知っておいて欲しい情報を入力します。
- 例:特定個人の経歴や家族構成など
- Examples
- モデルがレスポンスをより意図通りに生成するために、ユーザーが期待する会話例を入力します。
- 例:INPUT: Aさんの家族構成はどのようなものですか? 出力: 妻と子供が一人います。
- Test
- 実際にユーザーがモデルに生成させたい指示を入力します。
PaLM2を利用したFine-Tuningについて
上述の通り、すでに様々なデータを学習してあるモデルをAPIを通して利用することができます。
しかし、一般的なデータではない情報をモデルに知っておいてほしい場面もあります。
例:特定分野の技術情報、自社内の知見など
そのような場合、学習させたいデータを用いてFine-Tuningすることでそれらをモデルに学習させることができます。ここではその方法について紹介します。
データセットの準備
PaLM2のFine-Tuningに使用するデータセットを準備します。
ここではGenerative AI Studioから学習させる場合について紹介します。※pythonを使用する場合は後述
データセットはJSON Lines形式である必要があり、また各レコードのキーには”input_text”、”output_text”の両方を持っている必要があります。
{"input_text": "question: How many parishes are there in Louisiana? context: The U.S. state of Louisiana is divided into 64 parishes (French: paroisses) in the same manner that 48 other states of the United States are divided into counties, and Alaska is divided into boroughs.", "output_text": "64"}上記の例のように、”input_text”にはモデルに対して与える指示などを、”output_text“にはモデルが返すことを期待する回答を含めておきます。
また、上記の例では、モデルに対して与える指示を”question: “の後に、その指示に関して必要な情報を”context: ”の後に記述しています。
このようにどれが指示なのか、どれが必要な情報なのかを明示的に与え、またFine-Tune後のモデルに対しても同様の形式で入力することで、よりユーザーが期待する回答を得やすくすることができます。
Generative AI Studioを使ったFine-Tuning
Generative AI Studioを使って、UI上で簡単にPaLM2のFine-Tuningを行うことができます。
※6/19現在では、こちらの機能はpreviewでの公開となっています。
Generative AI Studioの「TUNING」タブをクリックすると下記ページが開きます。
このページの「+調整済みモデルを作成」をクリックすることで、Fine-Tuningする手続きに進みます。

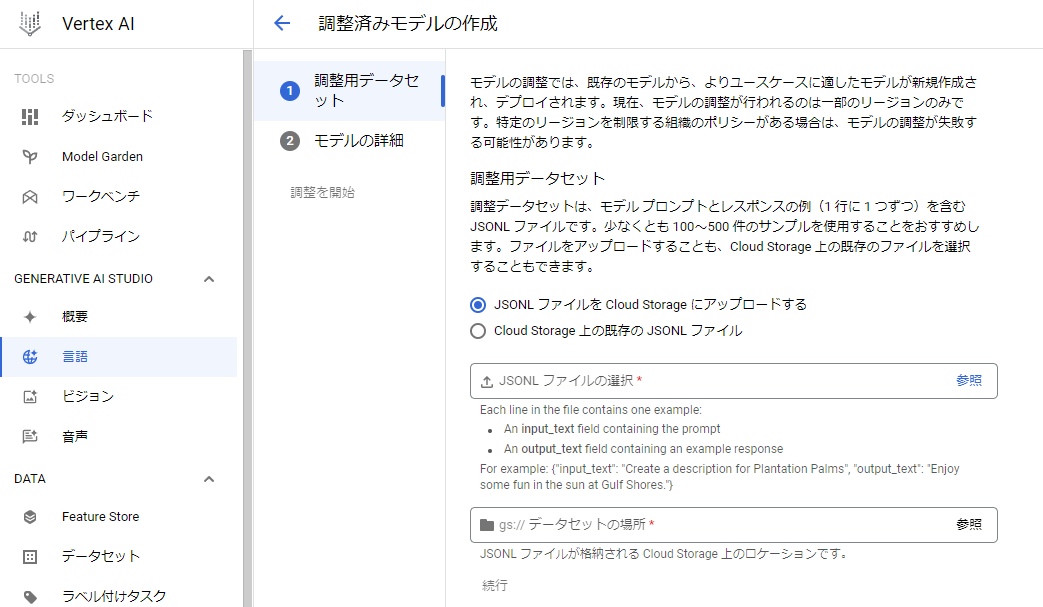
まずは学習させるデータセットを指定する必要があります。
データセットがローカルにある場合は、そのパスを指定して Google Cloud Storage へアップロードすることが可能です。
一方、データセットがローカルにない場合などは、Cloud Storageに別途アップロードの上、そのパスを指定する必要があります。
ここでは、Vertex AI Workbenchでデータセットを作成したと想定し、それをCloud Storageにアップロードするまでの方法を記載します。
1. gcloud認証
$ gcloud auth application-default login
2. Vertex AI Workbench内のフォルダとGCSをマウントする
# cloud bucket nameの指定 $ MY_BUCKET=<YOUR_BUCKET_NAME> # /home/jupyter/ に移動する $ cd ~ # マウント ポイントとして使用するフォルダを作成する $ mkdir -p gcs # MY_BUCKETと"/home/jupyter/gcs"をマウント $ gcsfuse --implicit-dirs --rename-dir-limit=100 --max-conns-per-host=100 $MY_BUCKET "/home/jupyter/gcs"
3. GCSとマウントされたフォルダに作成したデータセットを移動/コピーする
ここまでできれば、先ほどのページの「Cloud Storage 上の既存の JSONL ファイル」選択後、該当するファイルを選択すれば、学習させるデータセットの指定が完了します。
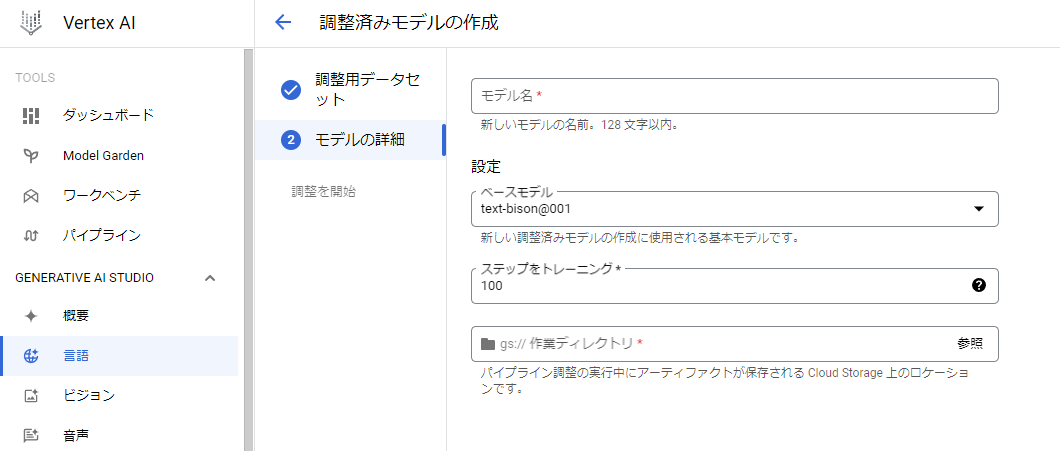
その後は、学習時の設定へ移ります。
ここでは、学習後のモデル名、ベースとするモデル、学習のステップ数、学習後モデルの保存先を選択します。※現在はベースモデルには”text-bison@001”のみが指定可能です。
上記の設定後、「調整を開始」をクリックするとFine-Tuningが実行されます。
Fine-Tuning開始後は、先ほどの「TUNING」タブの調整済みモデル一覧から、どのようなパイプラインで学習が実行されているかや現在の進捗状況などの情報を確認することができます。

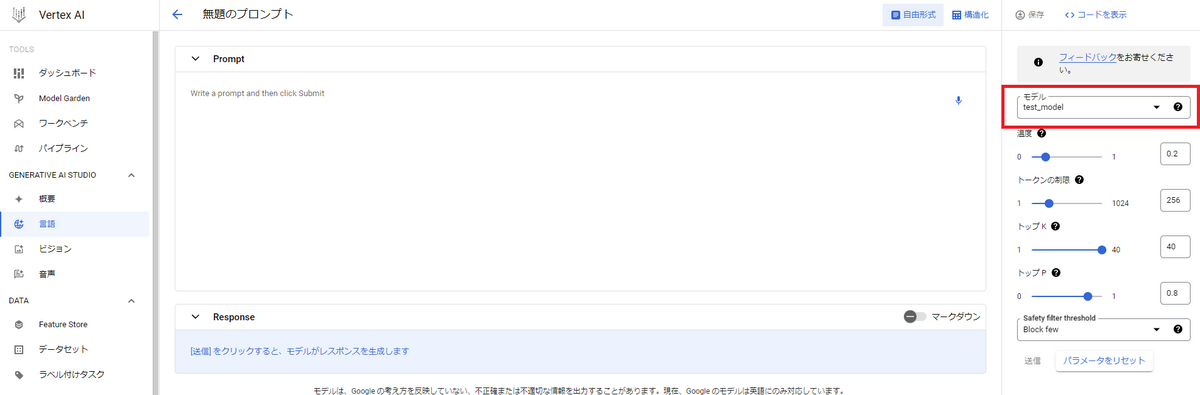
学習完了後は、Generative AI Studio -> 言語 -> テキストプロンプトから下記のページに遷移後、右の「モデル」から先ほど自分で設定した名前のモデルを選択することで、Fine-Tuningしたモデルの検証をすることができます。
もちろんpythonからの利用も可能です。
Vertex AI Workbench上でのpythonを用いたFine-Tuning
最後にpythonを使ってのFine-Tuning方法についてご紹介します。
大まかな流れはGenerative AI Studioから実行する場合と同様ですが、異なる点として、データセットをpandas.DataFrame形式で与えることが可能になっています。
この場合、DataFrameに”input_text”, “output_text”の2つのカラムを持っていることが必要です。
まずは必要モジュールのimportとデータセットの準備です。
from __future__ import annotations from datasets import load_dataset from google.auth import default import pandas as pd import vertexai from vertexai.preview.language_models import TextGenerationModel
今回はHuggingFaceのデータセットを利用する想定で実行しています。
データセットにはモデルへの指示である”instruction”(上述のquesion)とその指示に関して必要な情報である”input”(上述のcontext)の2つのカラムが存在すると仮定します。
PaLM2 のFine-Tuningでは、データセットはinput_textとoutput_textの2つのカラムである必要があるので、これらを一つの”input_text”へまとめています。
dataset = load_dataset('xxxx') df = pd.DataFrame(dataset['train']) def _make_input_text(sr: pd.Series): if sr.input == '': input_text = f'question: {sr.instruction}' else: input_text = f'question: {sr.instruction} context: {sr.input}' return input_text df_train = pd.DataFrame() df_train['input_text'] = df.apply(_make_input_text, axis=1) df_train['output_text'] = df.output # jsonl形式で出力する場合は下記を実行する # df_train.to_json('train_dataset.jsonl', force_ascii=False, lines=True, orient='records')
つぎに実際のFine-Tuningのためのスクリプトです。
先ほどと同様、現在はベースモデルとして’text-bison@001’のみが選択可能です。
また、ジョブを実行するリージョンも’europe-west4’のみとなっています。下記を実行すると学習のジョブが開始されます。
出力には先ほどの学習パイプラインへのリンクも表示されるので、そちらから学習の状況をモニタリングすることも可能です。
credentials, _ = default(scopes=['https://www.googleapis.com/auth/cloud-platform']) project_id = <your_project_id> location = 'us-central1' def tuning( project_id: str, location: str, training_data: pd.DataFrame | str, train_steps: int = 10, ) -> None: vertexai.init( project=project_id, location=location, credentials=credentials ) model = TextGenerationModel.from_pretrained('text-bison@001') model.tune_model( training_data=training_data, # Optional: train_steps=train_steps, tuning_job_location='europe-west4', tuned_model_location=location, ) print(model._job.status) # Fine-Tuningの実行 tuning(project_id, location, df_train, train_steps=100)
それでは、最後にベースモデルとFine-Tuningしたモデルをそれぞれ使ってみましょう。
Fine-Tuningしたモデルのmodel_nameはトレーニングジョブ後に表示されます。
もしくは、Generative AI Studio -> TUNING画面、または下記実行で確認できます。
TextGenerationModel.from_pretrained('text-bison@001').list_tuned_model_names()
tuned_model_name = <your_tuned_model_name> vertexai.init(project=project_id, location=location) base_model = TextGenerationModel.from_pretrained('text-bison@001') tuned_model = base_model.get_tuned_model(tuned_model_name) response_by_base_model = base_model.predict( prompt, temperature=0.2, ) response_by_tuned_model = tuned_model.predict( prompt, temperature=0.2, ) print(f"""Response from Base Model: {response_by_base_model.text}\n Response from Tuned Model:{response_by_tuned_model.text} """)
今回は出力された結果については省略しますが、こちらを実行すると学習前後での出力結果を比較することができます。
おわりに
今回は Google が提供するLLMサービスとPaLM2のFine-Tuningについて紹介させていただきました。
想像している以上に手軽にLLMや生成AIを扱えるので、皆さん是非試してみてはいかがでしょうか。
現在は、日本語に対応していないなど課題はありますが、今後も様々なアップデートがなされると思うので、楽しみにしていましょう。