

こんにちは。アナリティクスサービス部の藤本です。
2022年5月~8月にかけてKaggle(データ分析コンペサイト)で開催されたAmerican Express - Default Predictionコンペに参加し、金メダルを獲得することができました! コンペの紹介と、今回どのような手法が有効だったかについて、本ブログでご紹介したいと思います。
図: kaggleサイト( https://www.kaggle.com/
https://www.kaggle.com/competitions/amex-default-prediction/leaderboard
)より一部を加工して掲載
コンペの概要
タスク
クレジットカード会社であるAmerican Expressが主催したコンペで、クレジットカードの利用者が将来デフォルト(債務不履行)になるかどうかを予測するというタスクでした。詳細はKaggleのコンペティションページに記載されていますが、「より正確なデフォルトの予測ができれば、クレジットカードの審査が通りやすくなり、より良い顧客体験が実現できる」というのが開催目的のようです。

https://www.kaggle.com/competitions/amex-default-prediction/overview
)より)
データ
学習データとして、クレジットカードの利用履歴に関する情報が与えられました。テーブルデータであり、列名は「P_2」や「B_1」のように匿名化されていてそれぞれの列が何を意味するかは分からない状態でした。また、データはログデータの形式となっており、customer_IDごとに最大で13行のデータが存在しました。各行のデータがそれぞれのユーザーのある月のデータを表します。

学習に使う目的変数は別のテーブルデータで与えられました。各customer_IDごとにtargetがあり、将来デフォルトする場合は1、そうでない場合は0となっていました。

評価指標
評価指標は、本コンペ独自のものが採用されていました。GとDという2つの指標の平均で計算され、Gはジニ係数、Dは予測値上位4%のrecall(真陽性率)を表しています。やや理解しづらい指標ですが、2値分類でよく使われるAUCとジニ係数(G)が線形関係にあるため、基本的にはデフォルト有無を上手く予測できればスコアも良くなる状態でした。

コンペの特徴・重要なポイント
本コンペは、「データが匿名化されている」「評価指標が特殊」「データが50GBとテーブルデータにしてはかなり大きい」などいくつか特徴がありました。中でも個人的に一番重要だと感じたのは、「ログデータ形式の学習データを、どう集約して特徴量を作成するか」という点です。
目的変数は各customer_IDごとに1つなので、ログデータ(各customer_IDごとに複数行)のデータをそのままモデルに与えることはできません。平均値・最大値・最小値を計算するなどして集約する必要があります。この集約をどのように行うかによって、スコアが大きく変わりました。
自分のアプローチ(解法)
今回良いスコアを出すことができたのは、上述した「ログデータの特徴量作成」に関する工夫にあるので、そちらについて紹介していきます。工夫したポイントは大きく2つあります。
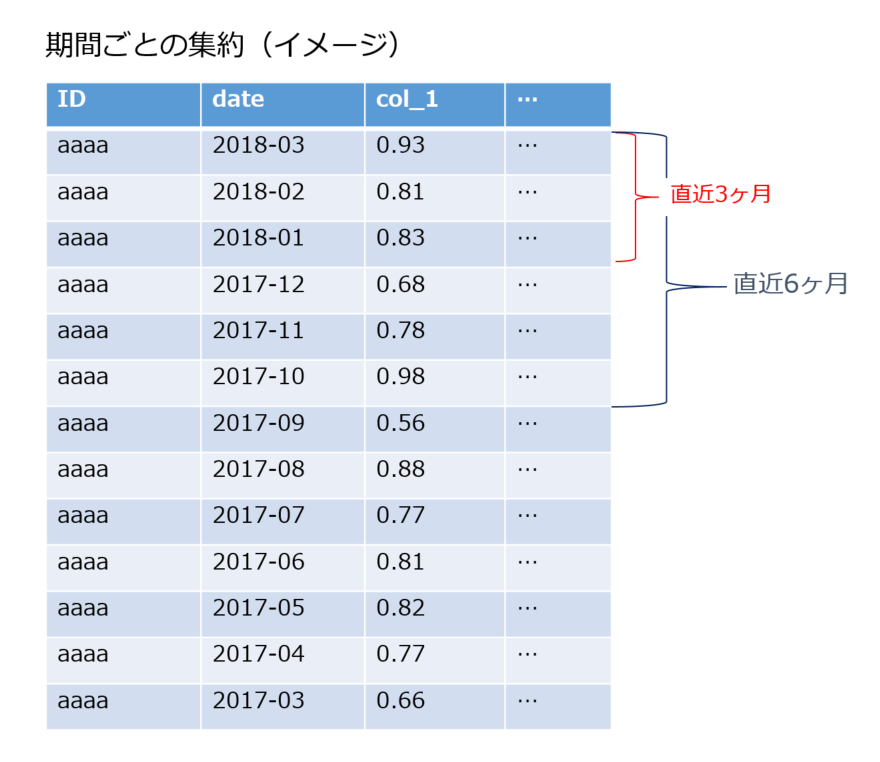
1. 期間を区切った集約を行う
1つは、ログデータの集約期間を変えて集計することです。公開notebookではログデータの集計時にcustomer_IDごとに全データ(13ヶ月分)の平均・最小・最大などを計算して集約を行っているものが多数でした。私の場合は、customer_IDごとに直近3ヶ月や6ヶ月という単位で区切って、平均・最大・最小などの集約を行いました。これにより、各ユーザーの全期間の集約ではできなかった直近3ヶ月での傾向なども特徴量として表現することができ、スコアの向上につながったと思います。
2. 個々のログデータにおける「targetの予測値」を算出して特徴量とする(メタ特徴量)
2つ目の工夫ポイントは、個々のログデータに対して「target(目的変数)の予測値」を計算して特徴量としたことです。過去のkaggleコンペにおいても使われていた手法で、メタ特徴量(meta feature)と言われています。代表的な例としては、DSB2019の2位解法があります。
複雑な手法なので、作成方法を順を追って説明します。
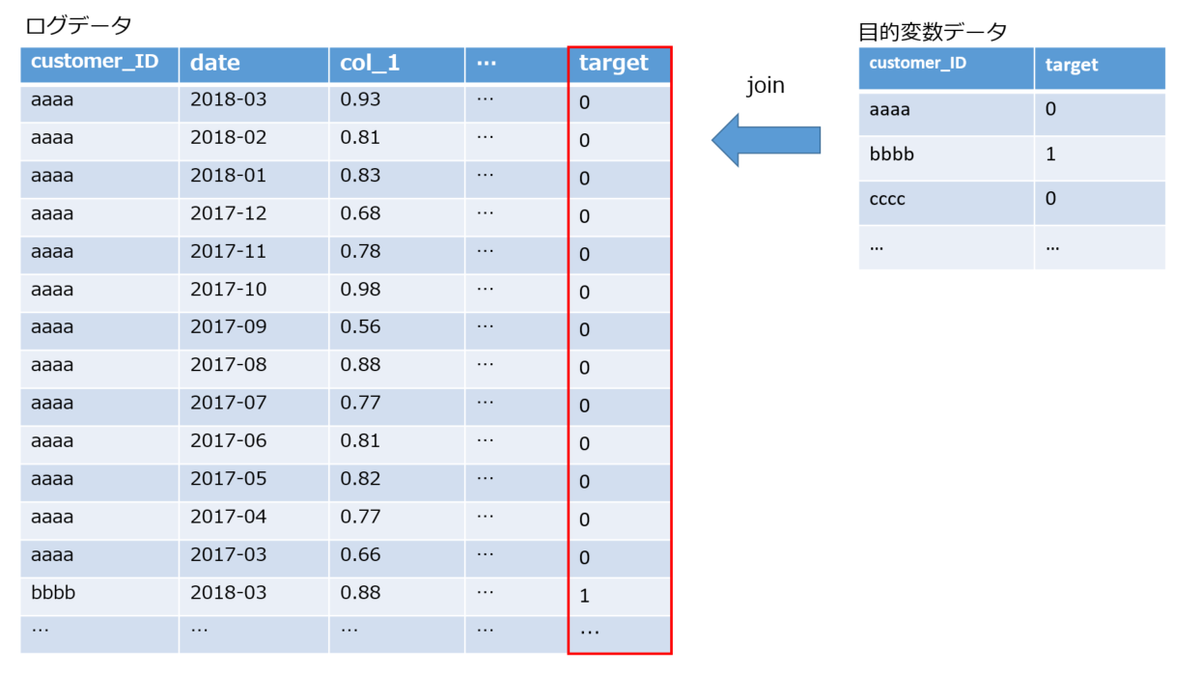
1. ログデータに対してtargetを紐づける
customer_IDをキーに紐づけます。目的変数が0のcustomer_IDの場合、そのログデータはすべて目的変数=0となります。
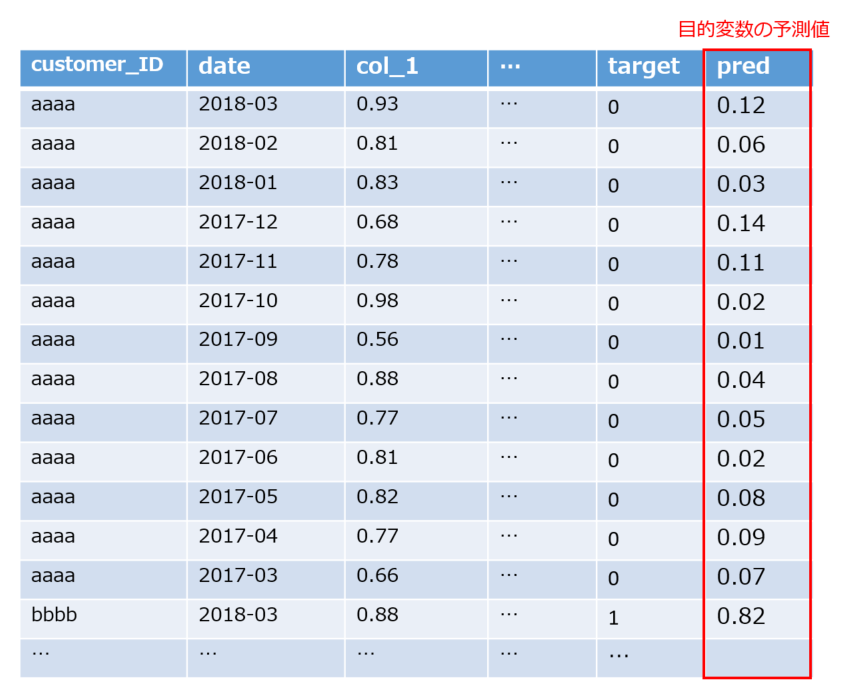
2. 紐づけたtargetを予測するモデルを作成し、目的変数の予測値を作る
まず、紐づけたtargetを使ってモデルを作成します。モデルを作成したら、作成したモデルを使ってtargetの予測値を作成します。
ここで注意が必要なのが、OOF(out-of-fold)の予測値を使うことです。クロスバリデーションの要領で学習と予測を分けることで、ある行の予測値を作成するときはその行のデータを学習に使っていないモデルを使うようにしてください。予測対象とするデータが学習データに含まれていると、データリークにより正しく予測値を作成することができません。
3. 作成した予測値を集約して特徴量を作る
最後に作成した予測値を集約して特徴量を作ります。集約方法は人それぞれですが、私の場合は
- 最新月の値
- 過去3ヶ月の平均・最大・最小
- 過去6ヶ月の平均・最大・最小
- 全期間の平均・最大・最小
のような集約を行っていました。
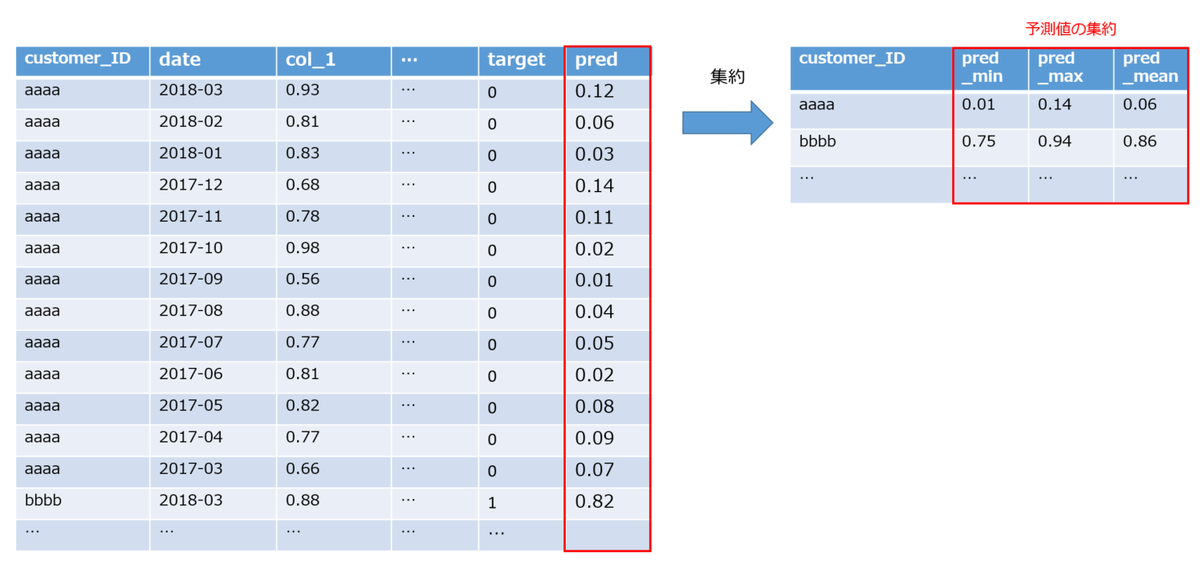
上記がメタ特徴量の作成手順です。
この手法の特徴は、個々のログデータに対してtargetの予測値を計算している点です。今回のケースでは、targetの予測値は「個々のクレジットカード履歴データが与えられた時のデフォルト確率」を表します。これを集約することで、「最新月のデフォルト確率」や「直近6ヶ月のデフォルト確率の平均」など計算することができます。
今回のコンペでは、上位解法にこのメタ特徴量を使ったものが多くありました。少し特殊な手法ですが、他の特徴量とは違う傾向を持つので精度向上に有効だったのではないかと考えています。
参加した感想
非常に学ぶことの多いコンペでした。私はLightGBMを使ってモデルを作成したのですが、他の上位解法を見ているとニューラルネットワークを用いた解法が多く非常に参考になりました。特にtransformerがよく使われており、自然言語処理で強いのは周知の事実ですが、テーブルデータにおいても今後主要なアプローチになっていくだろうと感じました。
最後に
ブレインパッドでは、自己研鑽としてSIGNATEやKaggleなどの外部コンペへの参加が推奨されています。
その他、社内では過去に行われていたコンペのコードを読む輪読会や、実際にコンペに参加した人からの知見共有会なども開催されています。ご興味のある方、ぜひご採用へのご応募お待ちしています!
www.brainpad.co.jp