
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。

こんにちは、AIソリューションサービス部の井出と申します。
この記事では、特に自然言語処理分野で幅広く使用される深層学習モデルTransformerを時系列データへ適用する方法に関してご紹介します。
以前の記事では、Transformerの構造や特徴などについて、自然言語処理分野の機械翻訳を例としてご紹介しております。はじめに、こちらの記事をご一読していただくことで、より本記事でご紹介する内容に対する理解が深まるかと思います。
Transformerとは
Transformerの詳細についてご興味がある方は、以前の記事をご一読ください。
本記事でも、簡単に概要をまとめておきます。
Transformerは、2017年に Google が発表した論文「Attention is all you need」で提案され、
自然言語処理分野で有名なモデルであるBERT, GPT, XLNetなどのベースとなっています。
Transformerの構成要素
- Source-Target-Attention
2つの系列データ(入力と出力)における時点間ごとの関係性を表現する。
- Self-Attention
1つの系列データ内での時点間ごとの関係性を表現する。
- Multi-head Attention
Attention構造を並列に組み合わせることで、同時に複数のパターンの関係性を学習・認識することができるようになり、更に豊富な情報を持つコンテキスト込みベクトルを表現する。
- Positional Encoding
系列データにおける順序情報を表現する。
- Position-wise Feedforward Network
系列データの時点ごとに共通の重みを持つFeedforward Networkである。
Transformerの特徴
- 計算速度が早い(=大量のデータを学習できる)
RNNでは1系列前の状態に依存して学習する必要があるため計算効率が低かったが、Self-Attentionでは依存性がなく並列計算も可能で高速である。
- 広範囲の依存関係をもとに高品質なコンテキスト込みベクトルを表現できる
Self-AttentionやSource-Target-Attentionでは、時点間ごとの関係を行列で表すことで広範囲な依存関係を上手く捉えられ、かつ、Multi-head Attentionによって、高い表現力で高品質なコンテキスト込みベクトルを取得できる。
自然言語処理における適用例
Transformerはその特徴から系列データを扱うことに適しています。そのため、系列データを代表する自然言語データに対する適用事例が数多く、BERT, GPT, XLNetなどのモデルも提案されています。
ここでは、自然言語処理分野でのTransformerの適用例をいくつかご紹介します。
- 機械翻訳
Heterogeneous Graph Transformer for Graph-to-Sequence Learning
- 自動要約
Hierarchical Transformers for Multi-Document Summarization
複数の文書間の相互関係を、単にテキスト単位で連結して平面的なシーケンスとして処理するのではなく、情報を共有することを可能にするSelf-Attentionを介して表現します。これによって、文書間の類似性や依存関係に焦点を当てて、複数文書を効果的に処理する文書要約モデルを開発しています。
- 感情-原因抽出
ECPE-2D: Emotion-Cause Pair Extraction based on Joint Two-Dimensional Representation, Interaction and Prediction
文書中の潜在的な感情のペアとそれに対応する原因を抽出することを目的とした感情-原因ペア抽出(ECPE)タスクにて、2D Transformerを用いて異なる感情-原因ペアの相互作用をモデル化したEnd2Endのアプローチを提案しています。
- 対話システム
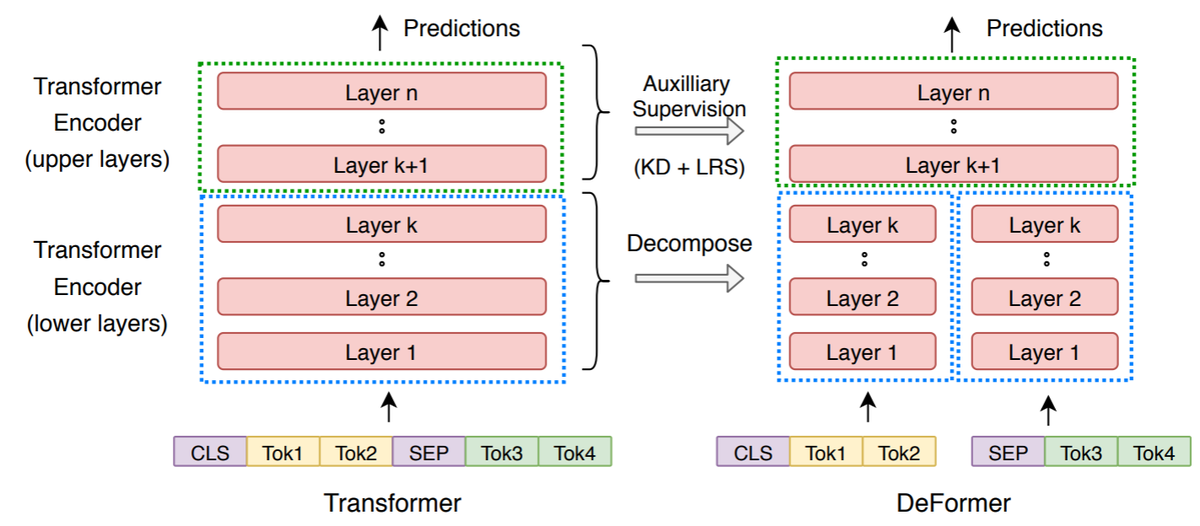
DeFormer: Decomposing Pre-trained Transformers for Faster Question Answering
従来のTransformerベースのQAモデルでは、全ての層で入力全体(質問とコンテキスト)に対するself-attentionを使用しているため、処理時間やメモリ効率の問題がありました。本論文では、Decomposed Transformer(DeFormer)によって、ネットワーク下位層において質問とコンテキストそれぞれに対するself-attentionで置き換えることで、入力されたコンテキスト表現は質問に依存しない処理を行うことができるアプローチを提案しています。その結果、各質問に対して、同様のコンテキスト表現を事前に計算することが可能となり、実行時間を大幅に短縮することが可能です。さらに、DeFormerはオリジナルのモデルとほぼ同様であるため、標準的なTransformerの事前学習済み重みでDeFormerを初期化し、対象となるQAデータセット上で直接ファインチューニングを行うことができます。
(画像は、記事末尾の参考文献より引用)
自然言語処理以外での適用例
Transformerは自然言語処理分野で扱われる事例が多かったですが、その他の系列データに対して適用される事例も増えています。
最近では、画像データに対しても、系列データのように扱うことでTransformerを適用し、成果を出した事例も報告されています。
ここでは、自然言語処理以外でのTransformerの適用例をいくつかご紹介します。
- 音楽生成
MUSIC TRANSFORMER: GENERATING MUSIC WITH LONG-TERM STRUCTURE
音楽は繰り返しによって構造や意味を表現しており、この特徴はTransformerのself-attentionが音楽のモデリングにも適していることを示唆しています。本論文では、Transformerによって音楽を生成することを試みています。
- 物体検出(画像)
End-to-End Object Detection with Transformers
物体検出問題を画像内のすべての物体の検出と分類(集合)を予測する「直接集合予測問題」として捉えることでTransformerを適用可能としています。
従来は、検出と分類を二段階に分けて予測する方法が用いられていましたが、本論文では、物体の検出と分類をEnd-to-Endで予測しています。これは、物体の位置(検出)と種類(分類)を集合とすることで、画像内の物体を系列データのように扱い、それらの位置と種類の関係性をTransformerによって学習しています。

(画像は、記事末尾の参考文献より引用)
- グラフデータ(分子構造データ)
Path-Augmented Graph Transformer Network
特に、分子表現の学習に関する最近の研究の多くはGraph Neural Networks(GNN)が用いられることが多いですが、GNNでは局所的な集約処理をしているため、高次のグラフ特性を見逃してしまう可能性があります。そのため、本論文では、グラフのパス特徴に関する広範囲の依存性をTransformerを用いて明示的に表現しています。
- 時系列データ
Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case
時系列データは、複雑なパターンや挙動が含まれた構造をしており、この構造をTransformerで学習しています。
また、本論文で述べられている手法は汎用的なフレームワークであり、単変量および多変量の時系列データにも適用可能です。
この記事では、上記の中でも時系列データに対する適用方法を取り上げてご紹介します。
時系列データに対するTransformerの適用方法について
2020年の論文「Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case」で提案された時系列データに対するTransformerの適用方法をご紹介します。
モデルのアーキテクチャは以下のようになります。

(画像は、記事末尾の参考文献より引用)
アーキテクチャは一般的なTransformerと大きな違いはないですが、回帰問題を扱う場合には最終層がLinearとなります。(分類問題を扱う場合には、Softmaxとなります。)
Encoder input、Decoder input、Decoder outputでは、Tが時間を表しており、Decoder outputの時間T5, T6における目的変数を予測するために、Encoder inputではT1~4、Decoder inputではT4~T5のおける特徴量を入力していきます。
自然言語処理での適用例と異なる点は入力データとなる特徴量の作成方法です。
特徴量
自然言語処理では、時間(単語)ごとの特徴量としてWord2Vecなどの分散表現を用いて単語ベクトルを作成します。
本論文では、単変量時系列データを対象として、時間Tごとの特徴量をベクトル化するためにTime Delay Embeddingが用いられています。
Time Delay Embeddingは以下の数式で表されます。これは、時間ごとに、時間間隔
で過去の値
を連結させた
次元のベクトルです。
多変量時系列データを扱いたい場合には、他の系列データ、系列属性、カレンダー情報、イベントなどを上記のベクトルに連結していくことで、Transformerの入力データとして使用することが出来ます。
学習データ
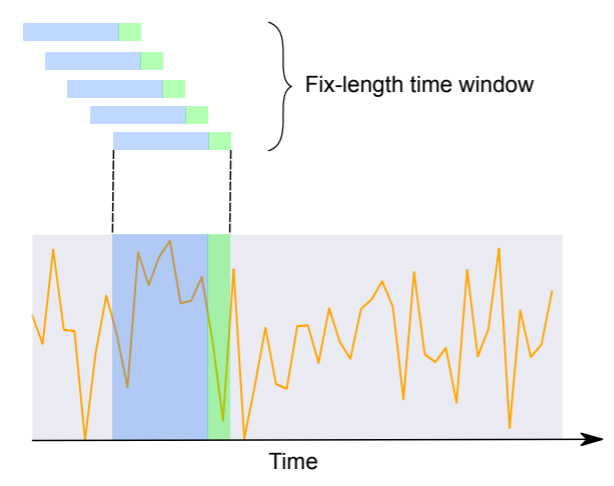
モデルに時系列データを学習させる際には、以下のようにラベル付きデータセットを作成します。
(画像は、記事末尾の参考文献より引用)
Encoder inputとDecoder outputとして使用する期間を固定長として、予測期間が重複しないように時間をスライディングしていき、Encoder inputでは特徴量とする期間における時点ごとの特徴量ベクトル、Decoder inputでは予測期間における時点ごとの特徴量ベクトル、Decoder outputでは予測期間における目的変数の実測値の組を用意していきます。
例:国ごとの週別インフルエンザ様疾患者数を対象として、過去10週間分の特徴量を使用して、1週間先までを予測するタスクで使用する学習用データセット
- Encoder input
- shape=(国数×スライディング数, 10週間, 特徴量ベクトルの次元数)
- Decoder input
- shape=(国数×スライディング数, 1週間, 特徴量ベクトルの次元数)
- Decoder output
- shape=(国数×スライディング数, 1週間, 1)
学習方法
用意したラベル付きデータセットを用いてモデルを学習していくのですが、Decoder inputでは予測対象となる期間の特徴量も必要となります。注意点として、評価時には予測期間での目的変数は未知であるため、モデルが予測した結果を入力として再帰的に使用していく必要があります。
一方で、学習時に評価時の状況に合わせてモデルを学習させようとすると連鎖的に誤差が大きくなっていき、学習が不安定になったり、収束が遅かったりしてしまうという問題が生じます。
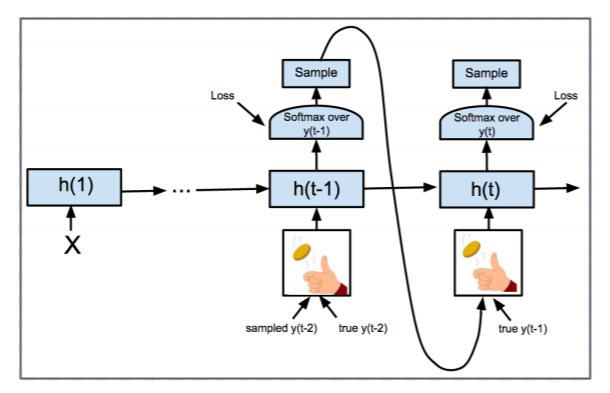
本論文では述べられていませんが、この問題に対して一般的に使用されるTeacher ForcingやScheduled Samplingという学習方法についてご紹介します。
- Teacher Forcing:Decoder inputとして目的変数の実測値をそのまま使用する。
- メリット:学習が安定し収束が早くなる。
- デメリット:評価時はDecoder inputとしてDecoder outputを使用するため、学習時の分布と異なってしまい過学習しやすい。
- Scheduled Sampling:Decoder inputとして目的変数の実測値をそのまま使用するか、Decoder outputを使用するかを確率的にサンプリングする。学習初期ではTeacher Forcingを実施し、学習が進むにつれてDecoder outputをサンプリングする確率を高くしていく。
- メリット:過学習しにくい。
- デメリット:Decoder inputを再帰的に用意する必要があるため、学習時間がかかる。
(画像は、記事末尾の参考文献より引用)
上記のように作成したEncoder input, Decoder input, Decoder outputを用いて、予測期間におけるモデルの予測値と正解となる実測値の誤差をまとめて最小化するようにミニバッチ学習を進めていきます。
他モデルとの比較
本論文では、週単位で地域別のインフルエンザ様疾患(ILI)比率を予測するタスクでTransformerを実験しています。
- 対象データ
- 期間
- 2010年~2018年
- 学習対象
- 過去10週間分のインフルエンザ様疾患(ILI)比率(前週の患者数との比)
- 予測対象
- 先4週間分のインフルエンザ様疾患(ILI)比率(前週の患者数との比)
- 評価指標
- Pearson Correlation(相関係数)
- RMSE
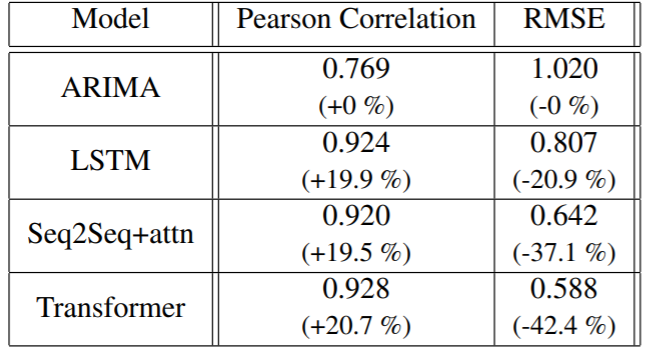
また、ARIMA、LSTM、Seq2Seq+attentionを適用した場合の評価結果とも比較されており、以下の表にまとめられています。()内の数字はベースラインモデルARIMAの評価結果に対する比率です。
(画像は、記事末尾の参考文献より引用)
深層学習モデル(LSTM, Seq2Seq+attn, Transformer)は相関係数とRMSEの両方でARIMAよりも全体的に優れていることが示唆されています。3つの深層学習アプローチの中で、相関係数は非常によく似ており、TransformerはLSTMとSeq2Seq+attnよりもわずかに高い結果でした。
RMSEに関しては、TransformerはLSTMとSeq2Seq+attnの両方を上回り、相対的なRMSEはそれぞれ、27%、8.4%減少した結果が得られています。
時系列データに対するTransformerの適用例
上記で紹介したアプローチを使って、別の時系列データに対してもTransformerを適用しました。
対象データとタスクは以下の通りです。
- 対象データ
- Sales_Transactions_Dataset_Weekly(製品ごとの毎週の購入量)
- データ量
- 期間:52週間(1年間)
- 製品:811種類
- 変数
- Product_Code:製品コード
- W0~W51:週毎の購入数
- タスク
- 先4週間における製品ごとの購入数の予測
- 学習用データと評価用データ:全ての製品を対象として、期間で学習用と評価用にデータを分割します。
- 学習用データ
- 期間:W0~W47
- 評価用データ
- 期間:W48~W51
- 学習用データ
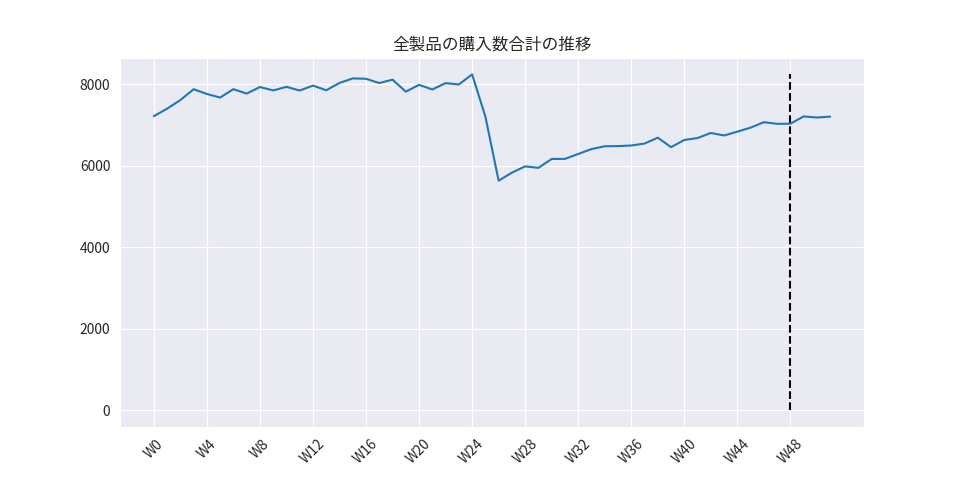
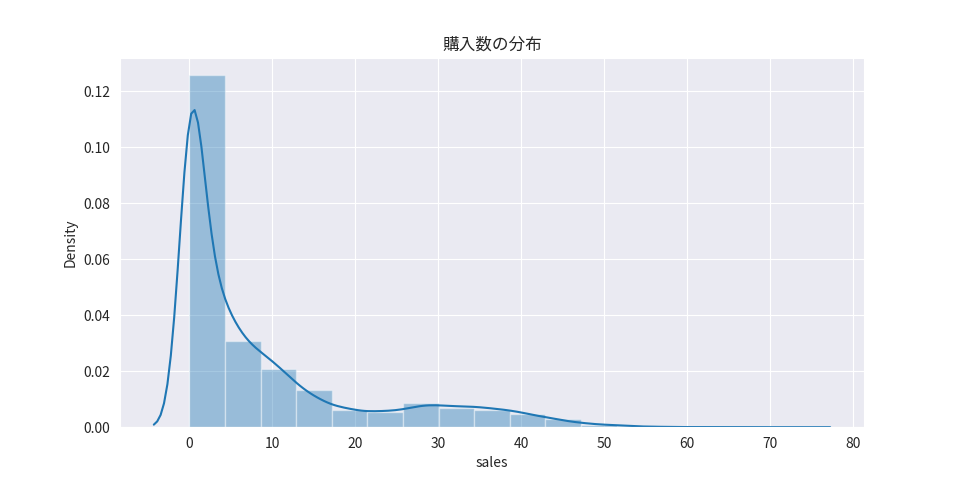
対象データをTransformerの学習・予測に適したデータセットにするため、前処理や特徴量の作成を実施していきます。
前処理
特徴量・目的変数として使用する購入数及び製品コードに対して前処理を適用していきます。
製品コードの前処理
欠損値の補完
深層学習モデルでは欠損値を扱う事ができないため、何らかの値で埋める必要があります。対象データには欠損値は含まれませんでした。
変数変換
深層学習モデルでは文字列を特徴量としてそのまま扱うことが出来ないので、Label Encodingによって製品コードごとにユニークな数字を割り振ります。
購入数の前処理
欠損値の補完
深層学習モデルでは欠損値を扱う事ができないため、何らかの値で埋める必要があります。対象データには欠損値は含まれませんでした。
変数変換
製品ごとに購入数のスケールが異なるため、予め揃える必要があります。また、深層学習モデルでは変数を正規分布に変換することで効率的に学習することができます。
対象データの購入数に対しては、対象日と前日の値との差分を算出した後に製品ごとに標準化することで変数変換しました。
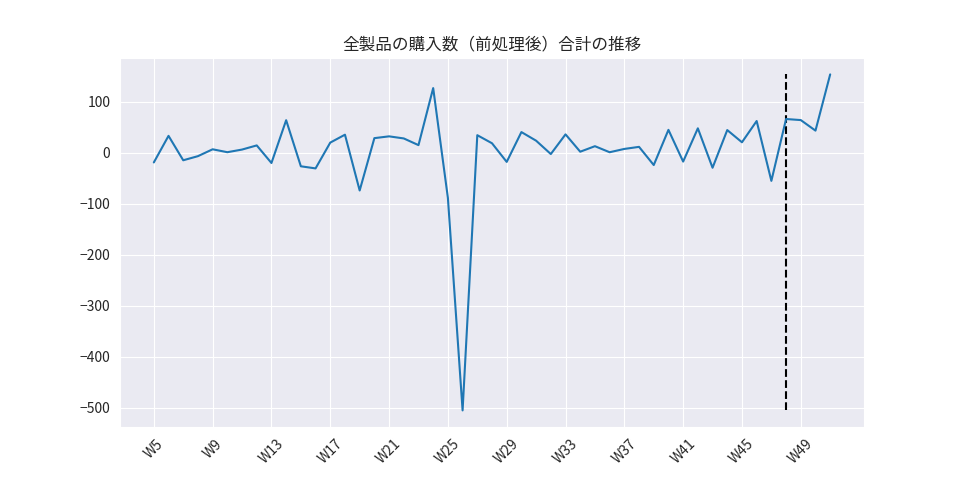
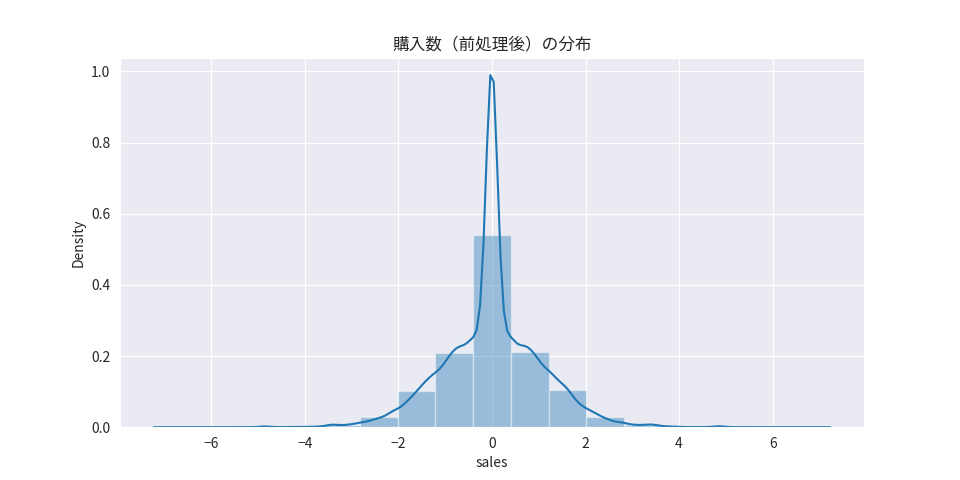
特徴量の作成
Time Delay Embeddingによって作成したベクトルとProduct_Codeを深層学習モデルでEmbeddingするベクトルを連結させることで特徴量を作成しました。
特徴量
- Time delay Embedding
- 過去4週分の購入数(前処理後)を連結したベクトル
- Product_Code
- 6次元のEmbeddingベクトル(LabelEncoderで割り振った数字をkeyとして対象となる製品のEmbeddingベクトルを参照しています。)
- 作成した学習用データセット
- Encoder input
- shape=(製品数×スライディング数, 12週間, 10)
- Decoder input
- shape=(製品数×スライディング数, 4週間, 10)
- Decoder output
- shape=(製品数×スライディング数, 4週間, 1)
- Encoder input
モデル
上記でご紹介したTransformerモデルをpytorchで実装しました。pytorchでは、torch.nn.Transformerモジュールを使用してTransformerモデルを実装することが可能です。
本実験で使用したモデルの実装は以下の通りです。
import math from typing import Optional, List, Tuple import torch from torch import Tensor import torch.nn as nn from torch.autograd import Variable from torch.nn import LayerNorm from torch.nn.init import xavier_uniform_ from torch.nn import TransformerEncoder, TransformerEncoderLayer from torch.nn import TransformerDecoder, TransformerDecoderLayer import numpy as np class TransformerModel(nn.Module): """Transformer model. Args: d_model: encoder/decoder inputsの特徴量数 nhead: Multi-head Attentionのヘッド数 nhid: feedforward neural networkの次元数 nlayers: encoder内のsub-encoder-layerの数 dropout: ドロップアウト率 activation: 活性化関数 use_src_mask: encoderで時系列マスクを適用するか cat_embs: 各カテゴリ変数におけるカテゴリ数とembedding次元数 fc_dims: decoder outputsに対するfeedforward neural networkの次元数 device: cpu or gpu """ def __init__( self, d_model: int = 512, nhead: int = 8, nhid: int = 2048, nlayers: int = 6, dropout: float = 0.1, activation: str = "relu", use_src_mask: bool = False, cat_embs: Optional[List[Tuple[int, int]]] = None, fc_dims: Optional[List[int]] = None, device: Optional[bool] = None, ): super(TransformerModel, self).__init__() if device is None: self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") else: self.device = device if cat_embs is not None: self.cat_embs = [ nn.Embedding(n_items, emb_size) if emb_size != 0 else nn.Embedding(n_items, n_items) for n_items, emb_size in cat_embs ] for i, (n_items, emb_size) in enumerate(cat_embs): if emb_size == 0: self.cat_embs[i].weight.data = torch.eye( n_items, requires_grad=False ) for param in self.cat_embs[i].parameters(): param.requires_grad = False total_cat_emb_size = np.array( [ emb_size if emb_size != 0 else n_items for n_items, emb_size in cat_embs ] ).sum() else: self.cat_embs = None total_cat_emb_size = 0 self.tgt_mask = None self.src_mask = None self.use_src_mask = use_src_mask self.pos_encoder = PositionalEncoding(d_model + total_cat_emb_size, dropout) encoder_layers = TransformerEncoderLayer( d_model + total_cat_emb_size, nhead, nhid, dropout, activation ) encoder_norm = LayerNorm(d_model + total_cat_emb_size) self.transformer_encoder = TransformerEncoder( encoder_layers, nlayers, encoder_norm ) decoder_layers = TransformerDecoderLayer( d_model + total_cat_emb_size, nhead, nhid, dropout, activation ) decoder_norm = LayerNorm(d_model + total_cat_emb_size) self.transformer_decoder = TransformerDecoder( decoder_layers, nlayers, decoder_norm ) if fc_dims is None: fc_dims = [] if len(fc_dims) > 0: fc_layers = [] for i, hdim in enumerate(fc_dims): if i != 0: fc_layers.append(nn.Linear(fc_dims[i - 1], hdim)) fc_layers.append(nn.Dropout(dropout)) else: fc_layers.append(nn.Linear(d_model + total_cat_emb_size, hdim)) fc_layers.append(nn.Dropout(dropout)) self.fc = nn.Sequential(*fc_layers) self.output = nn.Linear(fc_dims[-1], 1) else: self.fc = None self.output = nn.Linear(d_model + total_cat_emb_size, 1) self._reset_parameters() def _generate_square_subsequent_mask(self, sz): """未来の情報を考慮しないためのマスクを生成.""" mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1) mask = ( mask.float() .masked_fill(mask == 0, float("-inf")) .masked_fill(mask == 1, float(0.0)) ) return mask def _reset_parameters(self): """パラメータを初期化.""" for p in self.parameters(): if p.dim() > 1: xavier_uniform_(p) def forward( self, src: Optional[Tensor] = None, src_cat_idx: Optional[Tensor] = None, tgt: Optional[Tensor] = None, tgt_cat_idx: Optional[Tensor] = None, memory: Optional[Tensor] = None, ) -> Tensor: """Transformerを適用. Args: src: Encoder input(数値) src_cat_idx: Encoder input(カテゴリ) tgt: Decoder input(数値) tgt_cat_idx: Decoder input(カテゴリ) memory: Encoder output """ if src is not None: src = Variable(src, requires_grad=True).to(self.device).float() if src_cat_idx is not None: src_cat = torch.cat( [ emb_layer(src_cat_idx[:, :, cat_i]) for cat_i, emb_layer in enumerate(self.cat_embs) ], dim=-1, ) src = torch.cat([src_cat.to(self.device), src], dim=-1) src = self.pos_encoder(src) if self.use_src_mask: if self.src_mask is None or self.src_mask.size(0) != len(src): mask = self._generate_square_subsequent_mask(len(src)).to( self.device ) self.src_mask = mask memory = self.transformer_encoder(src, mask=self.src_mask) if tgt is None: return memory else: tgt = Variable(tgt, requires_grad=True).to(self.device).float() if tgt_cat_idx is not None: tgt_cat = torch.cat( [ emb_layer(tgt_cat_idx[:, :, cat_i]) for cat_i, emb_layer in enumerate(self.cat_embs) ], dim=-1, ) tgt = torch.cat([tgt_cat.to(self.device), tgt], dim=-1) # tgt = self.pos_encoder(tgt) if self.tgt_mask is None or self.tgt_mask.size(0) != len(tgt): mask = self._generate_square_subsequent_mask(len(tgt)).to(self.device) self.tgt_mask = mask decoder_output = self.transformer_decoder( tgt, memory, tgt_mask=self.tgt_mask ) fc_input = decoder_output if self.fc is not None: fc_output = self.fc(fc_input) else: fc_output = fc_input output = self.output(fc_output) return output class PositionalEncoding(nn.Module): """Positional Encoding.""" def __init__(self, d_model, dropout=0.1, max_len=5000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) div_term = torch.exp( torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model) ) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0).transpose(0, 1) self.register_buffer("pe", pe) def forward(self, x): """PositionalEncodingを適用.""" x = x + self.pe[: x.size(0), :] return self.dropout(x)
予測・評価結果
作成したデータセットの学習データを実装したTransformerモデルに学習させ、評価用データに対して購入数を予測しました。評価用データに対する予測値と実測値は以下のようになりました。
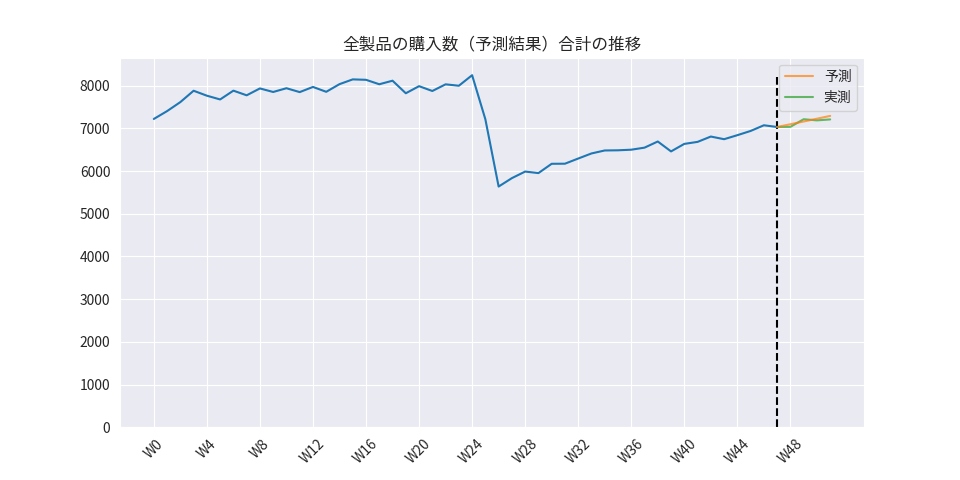
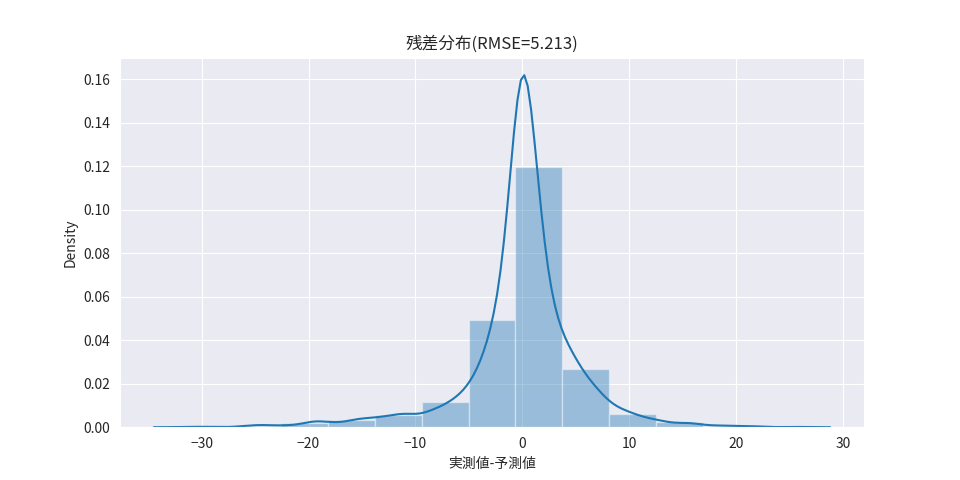
定量評価結果としてはRMSE=5.213でした。
予測期間の直近の上昇傾向が予測結果でも反映されていることが確認できます。一方で、週毎の購入数の変動を上手く学習出来ておらず、直近の購入数から単調増加していくという予測がされていることが確認できます。
これは、製品ごとの学習期間が48週間分と少ないデータ量であったことや購入数以外の特徴量(カレンダー情報、価格、イベント情報など)が不十分であったことが原因だと考えられるため、上記を追加することでモデルがより妥当な予測を出来るようになるかもしれません。
最後に
この記事では、Transformerを時系列データに適用する方法についてご紹介しました。
また、この記事では紹介していませんでしたが、Transformerをベースとした深層学習モデルでは以下のようなことも可能です。
- 学習済みモデルをベースとして別ドメインに対してチューニングを実施する
例えば、ある店舗を対象として製品ごとの売上を学習したモデルをベースとして、学習では使用していない別店舗や別商品に対して適用可能なモデルとしてファインチューニングすることも可能です。別ドメインのデータ数が少ない場合でも、学習済みの情報を参考に効率的に学習することが可能となるため、新たにモデルを作成するよりも高精度なモデルを期待することが出来ます。
- self-attentionを可視化することで、時点間の相互作用を確認することができる
- モデルが学習したEmbeddingベクトルをもとに、あるカテゴリ群をクラスタリングすることができる
ブレインパッドでは、Transformerを含む深層学習モデルなどの技術をビジネスに活用するべく、調査・検証を積極的に実施しています。
本記事を通じて、ブレインパッドの取り組みについてご興味を持っていただければ幸いです!