

こんにちは、AI開発部の須藤です。 今日はJSAI参加レポートの第3回目ということで、いくつか技術的に気になった発表内容を紹介していきます。
| 投稿予定 | テーマ(予定) |
|---|---|
| 第1回 | さまざまな業界で応用されているAI |
| 第2回 | 工業における機械学習の最近 |
| 第3回(本記事) | 技術的観点による論文ピックアップ |
| 第4回 | これからの人工知能。これからの人工知能社会 。 |
第1回目の記事でもご紹介しましたが、全体の要素技術としてはやはり深層学習が多い傾向が見られました。個人的には、深層学習の適用例だけでなく、深層強化学習の応用の話も増えてきている、という点が印象的でした。また、機械学習系の国際会議と違う点として、日本におけるさまざまな分野での応用事例が豊富なことが挙げられます。農業、工業、建築業などの分野に限らず、面白い分野だと、コミック工学、人狼知能のセッションがありました。
第1回目, 第2回目のブログでは人工知能の応用先の話をメインに紹介しましたが、本記事では、もう少し基礎寄りの技術的な観点で、気になった発表についていくつか概要を紹介していきます。
■[1N2-03]スタイルの類似性を捉えた単語ベクトルの教師なし学習
〇赤間 怜奈1、渡邉 研斗1、横井 祥1,2、小林 颯介3、乾 健太郎1,2(. 東北大学、2. 理研AIP、3. 株式会社Preferred Networks)
自然言語処理の分野において、何を伝えるか(意味)ではなく、どう表現するか(スタイル)をモデル化する、教師なし学習を提案しています。
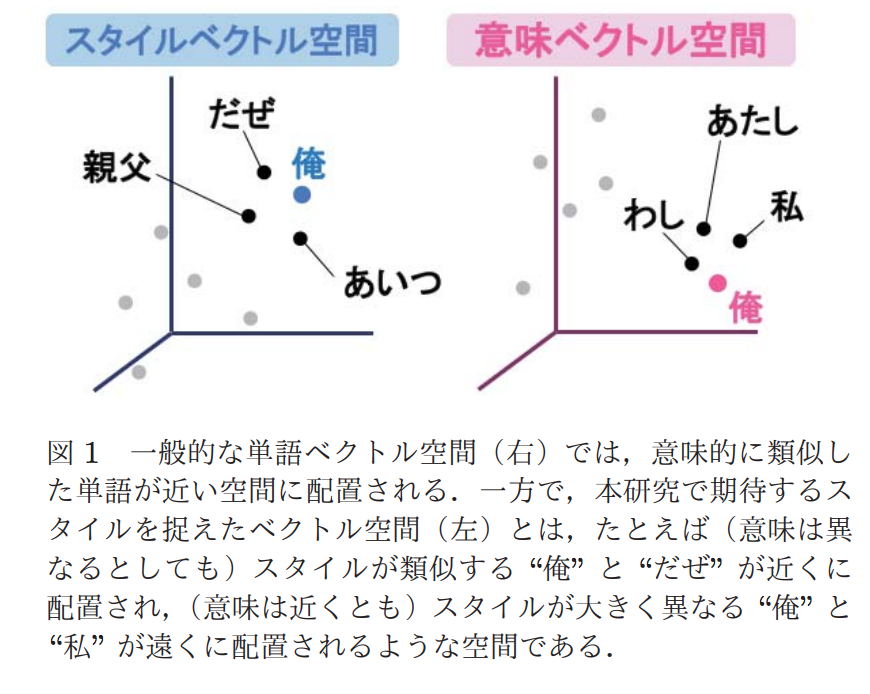
ここで言うスタイルとは、「俺」、「あいつ」、「親父」、「だぜ」などのような表現方法のことです。
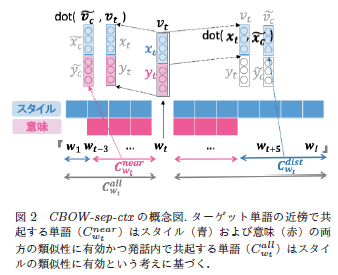
スタイルの学習も行うことができるように、CBOW(Continuous-Bag-of-Words)を拡張した手法を提案しており、スタイルの類似性を捉えた単語ベクトル空間で教師なし学習を行っています。CBOWでは、ある単語(ターゲット単語)の前後の単語数個からターゲット単語を推定するモデルを学習することで、単語間の関係性を学習し、単語の意味的表現を獲得します。 提案手法では、「属性や人物情報に関わらず、ある1つの発話内の全単語のスタイルは一貫している」という仮定の元、同じ発話内でターゲット単語から少し離れた単語群も含めて、ターゲット単語を推定するモデルを学習することで、意味的表現を除いたスタイルとしての表現を学習できる手法を提案しています。(上記、図2)
単語から意味以外の特徴も捉えることで、書き手がある程度自由に表現できるWeb文書などで有用そうですね!例えば、記事の著者推定や、スパム分類への応用といったことが考えられそうです。
■[3L2-05] 確率分布を用いた画像テキストデータの埋め込みと検索
〇濱 健太1、松原 崇1、上原 邦昭1(1. 神戸大学 大学院システム情報学研究科計算科学専攻)
こちらの発表では、マルチモーダルデータ間で適切な類似度を保つように、共通の空間に埋め込む手法を提案しています。適切な類似度に保った埋め込みを行うことで、画像とテキスト間の検索精度を向上させることに成功しています。
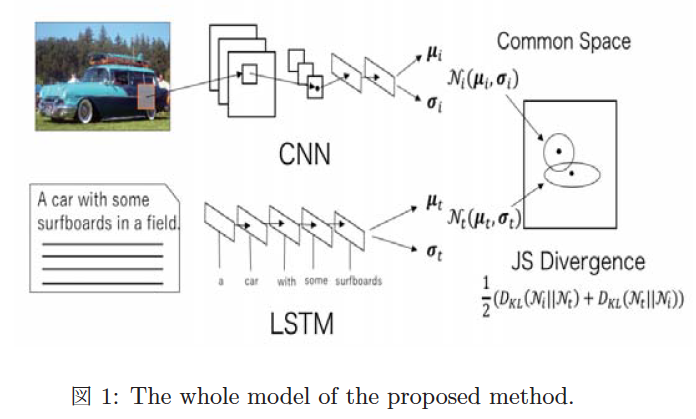
共通の空間に点として埋め込みを行うと、マルチモーダルデータ間の概念の包含関係や曖昧性の獲得が難しいとして、各データを点ではなく、確率分布として埋め込むことを提案しています。具体的には、従来手法のVSE(Visual Semantic Embeddings)を拡張し、VAE(Variational Autoencoder)のように正規分布のパラメータを出力するニューラルネットを導入しています。ただし、特徴量が確率分布になってしまうため、コサイン類似度ではなく、JSダイバージェンスを類似度指標として用いています。(上記、図1)
シンプルな手法にもかかわらず、精度が良く、発展性がありそうなので、個人的には最も興味を惹かれました。テキストと画像を活用することで、レコメンドにも用いることができるため、ビジネス面でも活かすことができそうですね! 当社でもインターンの方が画像とテキストを用いた応用事例に取り組んでいました。
■[4A1-04]深層混合モデルによるクラスタリング
〇林 楓1、岩田 具治2、谷口 忠大1(1. 立命館大学、2. NTTコミュニケーション科学基礎研究所)
VAEとGMM(Gaussian Mixture Model)を同時に学習することで、GMMのみだとうまくクラスタリングできないデータに対しても、クラスタリングが可能な手法を提案しています。 従来手法だと、クラスタ割り当ての真の分布と近似分布のKLダイバージェンスを0にしていますが、提案手法では、Jensenの不等式を用いて、GMMの下限とVAEの下限を含んだ変分下限を導出して、近似を行っています。
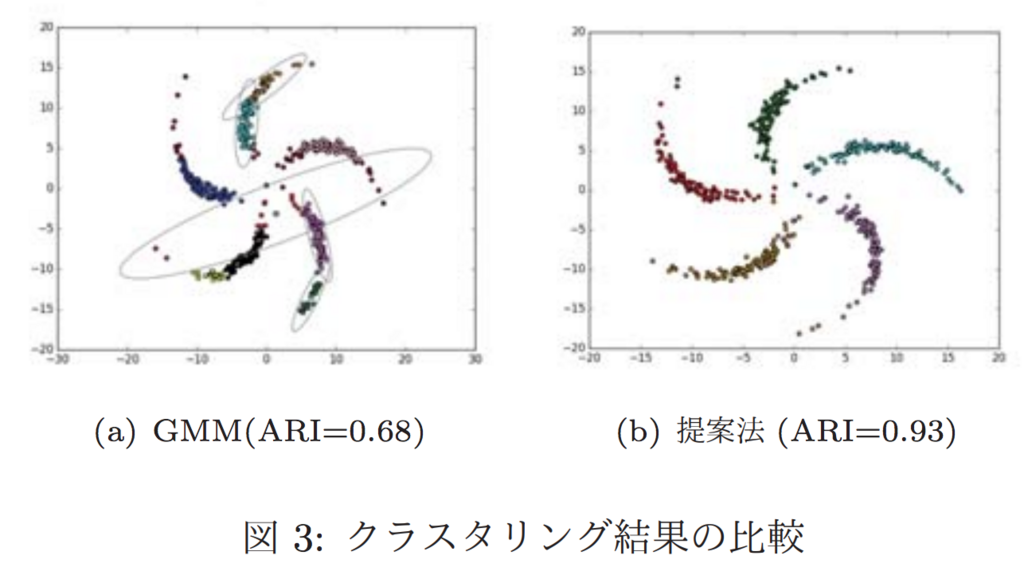
実験として、pinwheel dataに対してGMMと提案手法での比較を行っています。
■[1Z3-03]時系列データに対するdisentangleされた表現学習
〇山田 真徳1、Kim Heecheol3、三好 康祐3、山川 宏2,3(1. NTT セキュアプラットフォーム研究所、2. 全脳アーキテクチャ・イニシアティブ、3. ドワンゴ人工知能研究所)
強化学習におけるactionのDisentangleな表現の獲得を目指すために、β-VAEと呼ばれるモデルを系列データに拡張できる手法を提案しています。 beta-VAEとは、解釈が可能な潜在変数zを扱えるように制約をつけたVAEの事で、disentangleというのは、他の要素に影響を与えないように潜在変数間を分解していく(もつれをほどく)というような意味です。
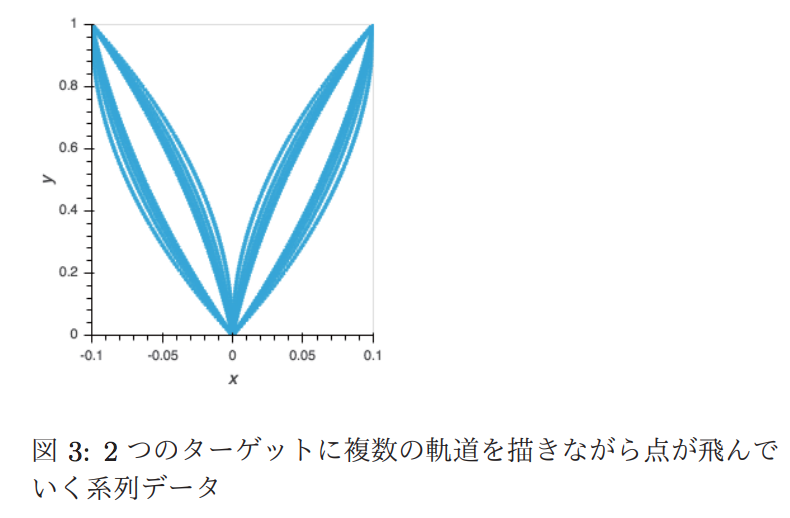
こちらの発表では上記のように、ターゲットを目指していく系列データから、 どちらのターゲットを目指しているか(右上か、左上か) 内側に膨らむか、外側に膨らむか、 という、それぞれが無関係(独立)な意味を持った潜在変数に分離することを目指した実験を行っています。

VLAE(Variational Ladder Autoencoder)にβ-VAEのロスを適用した手法と、それにseq2seqを組み合わせた手法で実験を行っています。seq2seqと組み合わせた手法では、外側の軌跡の膨らみを獲得することはできていませんが、系列の意味の分離が確認できています。
画像の分野では、Grad-Camのように深層学習の解釈を目指す技術が最近流行っていますが、系列データに対する潜在表現の解釈、というのは有用そうな技術ですね!
■最後に
まだまだご紹介しきれていない発表がたくさんありますが、今回はざっくりと要素技術が気になった発表という形でそれぞれ紹介しました。どの発表も基礎技術寄りの内容でしたが、すぐに応用に活かすことができそうです。
明日は、「これからの人工知能。これからの人工知能社会。」をテーマにお届けします。是非楽しみにしてください!
ブレインパッドは、イベントへの参加や最先端の情報収集など、さまざまな取り組みを積極的に実施しています。実際のビジネスで自分の知識・技術を活用してみたいという方、ぜひエントリーください!