
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。

目次
こんにちは、アナリティクスコンサルティングユニット所属の金です。
現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
今回は、ソフトウェアエンジニアリングにおけるLLMの適用をトピックにメイン論文と関連論文を紹介します。
今回のトピック
ソフトウェアエンジニアリングにおけるLLMの適用

ソフトウェアエンジニアリングの分野では、作業の自動化と効率化が強く求められており、特に大規模現モデル(LLM)の応用に対する期待が高まっています。これは、コーディング、テスト、デバッグなどのタスクをより迅速かつ効果的に行うための手段として見られています。
しかし、ソフトウェアエンジニアリングにおけるLLMの具体的な能力や、それに伴うリスクや制約についての知見は、まだ十分に整理されていないのが現状です。これには、LLMsの出力の信頼性や、特定の技術的課題(例えば、生成されたコードの品質や適切なテストケースの生成など)への対応が含まれます。
Metaなどの研究者たちによる「Large Language Models for Software Engineering: Survey and Open Problems」(の中で特にソフトウェア開発の内容)をまとめてみました。
メイン論文
メイン論文の構成は下図の通りです。本記事ではソフトウェア開発と関係のあるセクション3~7を解説します。

要件工学と設計
現状の要件工学と設計:
- 要件工学は、製品の目的と技術的実装をつなぐ基本的なプロセスです。しかし、この分野は従来、人の判断や手作業に大きく依存しており、エラーや不完全さ、曖昧さに対して脆弱でした。
- 現行のアプローチでは、要件の特定、ドキュメント化、維持がしばしば非効率的で、プロジェクトの遅延やコスト超過の原因となっています。
- この分野では、AIや機械学習に基づく自動化の導入が進められてきましたが、特にLLMを活用した具体的な進展は限定的です。
LLMによる貢献の可能性:
- 要件の抽出と分析: LLMは、自然言語の理解能力を活用して、テキストから自動的に要件を抽出し、分析することができます。これにより、曖昧さの解消や欠落情報の識別など、文書の品質改善に貢献する可能性があります。
- トレーサビリティの強化: 要件とその他のソフトウェアアーティファクト(コード、テストケースなど)との間の関係性を追跡することが、プロジェクト管理において重要です。LLMは、関連情報間の関係性を理解し、トレーサビリティの自動化を支援できるでしょう。
- 自動要件生成: 既存の情報から新たな要件を洗い出したり、要件のテンプレートを自動生成したりすることが、設計プロセスを加速させます。LLMは、これらのタスクの効率性と正確性を高めることが期待されます。
障壁と課題:
- 信頼性と正確性: LLMの出力の信頼性と正確性は、実際のプロジェクトでの採用において重要な考慮事項です。誤ったまたは不完全な要件は、重大な結果を招く可能性があるため、モデルの判断を盲目的に信用することはできません。
- 複雑な要件の理解: 要件はしばしば業界特有の知識や複雑なビジネスルールを含むため、LLMが正確に理解し再現することは困難です。
- 実践コミュニティとのギャップ: 現場のエンジニアやステークホルダーがLLMの能力を完全に理解し信頼するには、橋渡し役となるより具体的な事例研究や成功事例が必要です。
要約:
- LLMは要件工学と設計分野において革新的な貢献を果たす可能性を秘めています。
- 応用はまだ初期段階にあり、技術的信頼性や実践的な適用性の向上が求められています。
関連論文:
| タイトル | 概要 |
|---|---|
| [2304.12562] Empirical Evaluation of ChatGPT on Requirements Information Retrieval Under Zero-Shot Setting | - 要件の自動収集 - ChatGPTを使って、ソフトウェアが必要とする機能(要件)を見つけ出すテストを行いました。結果はまだ初期段階ですが、このAIが将来、要件収集を上手に助けられるかもしれないという希望が持てました。 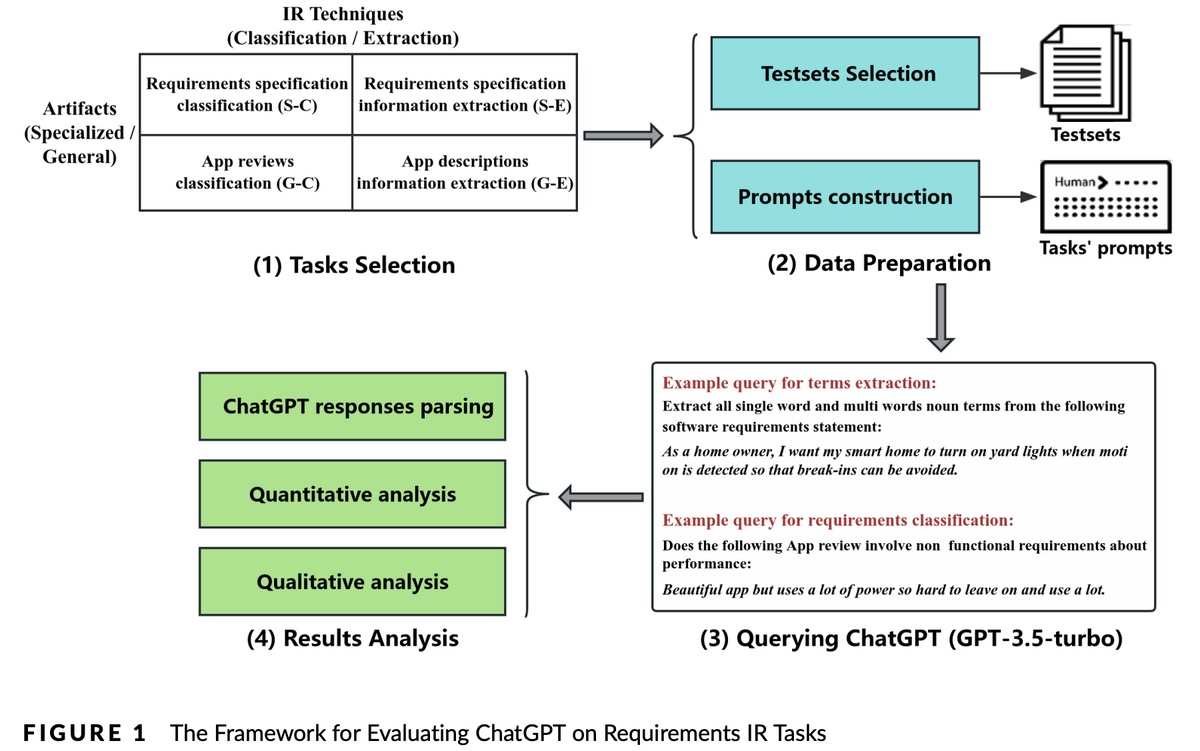 |
| PRCBERT: Prompt Learning for Requirement Classification using BERT-based Pretrained Language Models | - 要件の分類 - BERTというAIを使って、集められた要件を自動で分類する実験をしました。これにより、要件を整理しやすくなる可能性があります。 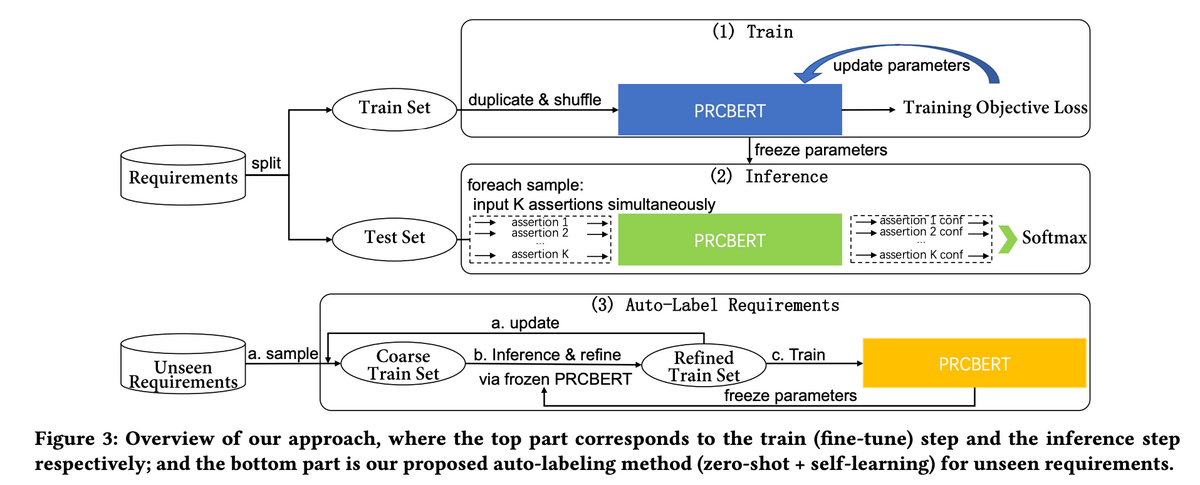 |
| [2308.03784] Improving Requirements Completeness: Automated Assistance through Large Language Models | - 情報の欠落を探る - 要件のリストから欠けている情報を見つけるために、BERTというAIを使用しました。これがうまくいけば、ソフトウェア開発で見落としがちな点を発見できるかもしれません。 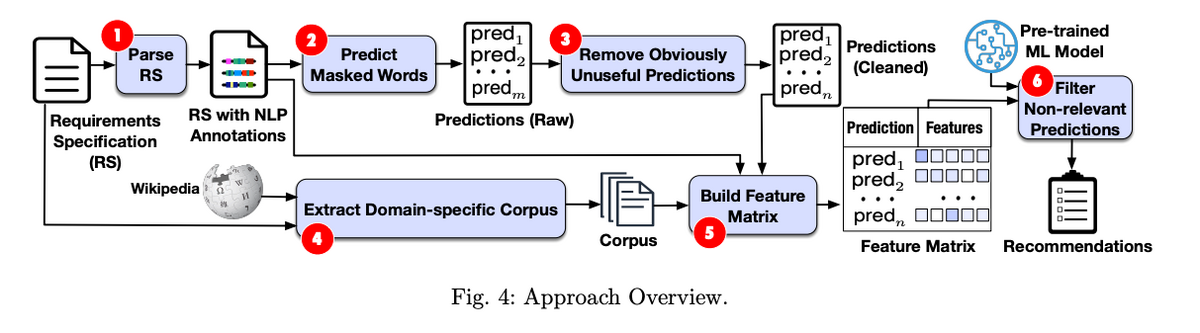 |
コード生成と補完


現状:
- コード補完は、大規模言語モデル(LLM)が最も活用されている領域の一つです。LLMは、既存のコードリポジトリから学習することで、開発者に適切なコード補完を提供します。
- コード生成においても、自動化への長い歴史があり、コードの「自然さ」や再利用可能性、予測可能性が、有効なコード生成の推奨に利用されています。
LLMの貢献:
- LLMは、大量の既存コードから予測と再利用のパターンを学習し、正確なコード補完や生成の推奨を提供できます。
- 特定のツール(例:CodeCompose、GitHub Copilot)は、開発者によるコードの書き方を劇的に高速化し、効率化します。これにより、開発者はコードの記述よりレビューに時間を費やすことが増えるでしょう。
障壁と課題:
- コード補完や生成における「ハルシネーション」(不正確な情報の生成)は、開発者が最終的な品質管理を行うことで緩和されますが、これは追加の人的労力を必要とします。
- 現行のLLMは、より複雑なコード生成タスクにおいて、まだ限界があります。正確さ、信頼性、そして特定のコンテキストにおける適切なコードの提案が必要です。
要約:
- コード補完と生成におけるLLMの使用は、ソフトウェア開発の効率を大幅に改善する潜在能力を持っています。
- その過程で発生する誤情報のリスクと、複雑な問題に対する現行モデルの限界が課題。
関連論文:
| タイトル | 概要 |
|---|---|
| [2305.12050] AI-assisted Code Authoring at Scale: Fine-tuning, deploying, and mixed methods evaluation | - CodeComposeの展開経験を報告。 - Incoder LLMに基づくコード補完ツールとして、450万件の提案が行われ、22%の受け入れ率を達成。 - 開発者からの質的フィードバックは92%が肯定的であった。 |
| [2302.06590] The Impact of AI on Developer Productivity: Evidence from GitHub Copilot | - GitHub Copilotの助けを借りて、プログラマーが非自明なタスクを56%速く完了できたことを報告。 - 対照群と比較して、HTTPサーバーの実装などのタスクの効率が大幅に向上。 |
| [2107.03374] Evaluating Large Language Models Trained on Code | - CodeX、GPT言語モデルの導入と評価。新しい評価セット「HumanEval」を通じて、ドックストリングからのプログラム合成のための機能的正確さを測定。 - CodeXがGPT-3とGPT-Jを上回るパフォーマンスを発揮したことを確認。 |
| [2306.11644] Textbooks Are All You Need | - 教科書品質のコードコーパスでのトレーニングにより、より小さいLLMでも大規模モデルに匹敵するパフォーマンスが達成可能であることを示唆。 - GPT-4モデルを使用して既存のPythonコードコーパスを分類し、学生がプログラミングを学ぶためのコードの教育的価値を評価。 |
ソフトウェアテスティング
現状:
- ソフトウェアテストは、自動テストスイートの生成に重点を置いた成熟した研究分野ですが、テストの偶然性やフレーク性を減少させる新しいアプローチが模索されています。
- LLMを用いたテスト生成や、既存のテスト生成手法とのハイブリッドアプローチが注目されています。これにより、LLMが生成するテストの予測可能性や一貫性が向上することが期待されます。
- 生成されたテストの実行可能性やコードカバレッジはまだ一貫性がありませんが、一部の研究では、従来の手法を上回る結果が報告されています。
LLMの貢献:
- 新しいテストの生成:
- LLMはテストデータの生成に使用され、コンパイル可能なコードの生成が期待されますが、すべてが実行可能なわけではありません。
- 既存のテスト生成技術とLLMの組み合わせによるハイブリッドアプローチが、コードカバレッジの向上に寄与しています。
- ユーザーインターフェーステスト:
- LLMは、アプリケーションの状態を理解し、GUIを通じて操作する能力があり、この分野でのテスト生成に新たな可能性をもたらしています。
- ユーザーレポートからのテストケース構築:
- 自然言語で書かれたユーザーレポートからテストケースを生成する能力により、LLMは従来の技術に取って代わる可能性があります。
- プロンプトエンジニアリングとテスト生成の改善:
- 精巧なプロンプト設計を通じて、テスト生成の質とカバレッジが向上しています。
障壁と課題:
- 実行可能性と一貫性の欠如:
- LLMによって生成されたテストの多くがコンパイル不可能であるか、実行時に問題が生じることがあります。
- コードカバレッジと精度:
- 高いカバレッジと精度を達成するには、既存の手法やハイブリッドアプローチの更なる改善が必要です。
- 信頼性と確信度の問題:
- LLMの出力の信頼性を測定し、予測に自信を持つための効果的な方法が必要です。
- プロンプトエンジニアリングの限界:
- より洗練されたプロンプトは改善をもたらしますが、その設計と最適化は煩雑で、一貫した結果を得ることが困難です。
要約:
- LLMの潜在能力を最大限に引き出し、より効果的なソフトウェアテストの実現に向けた研究と開発が求められています。
- 実行可能なテストの生成、高いカバレッジの達成、そして出力の信頼性と予測の確信度を向上させることが、今後の課題。
関連論文:
| タイトル | 概要 |
|---|---|
| [2306.05152] Towards Autonomous Testing Agents via Conversational Large Language Models | - LLMはソフトウェアテストの自動化を助けるが、ハルシネーションや限られた自動評価能力が課題。 - プロンプトエンジニアリング、テストの自己評価、科学的基盤の改善が今後の重要な研究方向。 |
| CodaMosa: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language Models | - 従来の検索ベースのソフトウェアテスト(SBST)と大規模言語モデル(LLM)を組み合わせて、テストのカバレッジを改善する。 - 進捗が停滞するまでSBSTを適用し、その後カバレッジが不十分なコードに対して例となるテストケースをCodexのようなLLMに要求して、テストケース生成を強化する。 - 486のベンチマークにおけるテストでは、標準のSBSTやLLMのみの方法と比較して、CodaMosaは統計的に有意なカバレッジの改善を示した。 |
ソフトウェアのメンテナンス
現状:
- ソフトウェアのデバッグ、修理、リファクタリングは言語モデルの技術が大きく貢献している分野です。
- デバッグでは、GPT-3.5やGPT-4が欠陥の位置を特定するのに役立つが、コードのコンテキストが長くなるにつれてその性能が低下する傾向があります。
- プログラム修復では、LLMがバグの特定や修復案を提供する新しい方法を提示していますが、生成される解決策が常に正確とは限らず、不適切な情報を生成するハルシネーションの問題があります。
LLMの貢献:
- コード品質の向上: LLMはリファクタリングを通じてコードの構造的複雑さを減少させ、読みやすさ、保守性、拡張性を改善することで、全体のコード品質を高めます。
- パフォーマンス改善: 実行時間、メモリ使用量、電力消費の最適化など、LLMによるコードの効率性の提案により、パフォーマンスが向上します。
- 自動化と効率性の向上: LLMのフューショット学習により、プロジェクト特有のリファクタリング要件への自動対応が可能となり、開発者はルーチンから解放され、創造的な作業に集中できるようになります。
障壁と課題:
- スケーラビリティと実行可能性: LLMによって生成されるコードの検証が大規模プロジェクトで継続的に行われるためには、適切なリソースが必要です。このスケーラビリティの問題は、リソースの制約がある場合に特に顕著です。
- ハルシネーションの問題: LLMが不適切なコード修正を提案するリスクを適切に管理する必要があります。
- 評価と信頼性: 提案された修正が正確かつ効果的であることを保証する評価基準が不足しており、信頼性の確保が課題となっています。
要約:
- LLM技術はソフトウェアのデバッグ、修正、リファクタリングを改善しているが、長いコードでは性能が低下し、常に正確な修正案を提供するわけではない。
- コード品質とパフォーマンスを向上させるが、スケーラビリティ、ハルシネーションの問題、評価基準の欠如といった課題に直面している。
関連論文:
| タイトル | 概要 |
|---|---|
| [2304.13187] AI-assisted coding: Experiments with GPT-4 | - GPT-4のリファクタリング能力の実験と評価。 - 研究ではGPT-4が提供したリファクタリングの例を用いて、コード品質がHalstead複雑性やMcCabe複雑性といった既存の構造的メトリクスに従ってどのように改善されるかを分析している。 - GPT-4はリファクタリングを通じてコード品質を有意に改善することが可能であることを示している。 |
| [2301.03373] Chatbots As Fluent Polyglots: Revisiting Breakthrough Code Snippets | - コードアシスタントとしてのAI、特にチャットボットの潜在能力に注目。 - レガシーコードのリファクタリングと、複雑なコードリポジトリの説明や機能をよりアクセスしやすく、簡単にするプロセスにおけるAIの役割に光を当てている。 - AIコードアシスタントがレガシーコードの理解とリファクタリングを支援し、高価値リポジトリの機能を簡潔に説明することの有益性を強調。 |
ドキュメント生成とコード要約
現状:
- LLMベースのアプローチは、コードの自動要約やドキュメント生成において、伝統的な方法に比べて前進を遂げていますが、いくつかのモデルは標準的な評価指標で予想外の結果を示しています(例:ChatGPTのパフォーマンスの問題)。
- コード要約のためのプロンプトエンジニアリングや異なる技術的観点からのサマリー生成など、さまざまな応用分野での研究が進められています。
- 要約技術は現在、主に既存のコーパスに基づく検索ベースのアプローチに依存しています。
LLMの貢献:
- LLMは、コーパスに制約されない、文脈に即した要約の生成を促進し、ドキュメントのセマンティックな豊かさを改善することが期待されています。
- 特定の技術的視点からのカスタマイズされたドキュメント生成に対応する能力があります。
- トレーニングコーパスに存在する既存の例に制約されない、新しい要約やコメントの生成が可能です。
障壁と課題:
- 既存の評価指標は、LLMによって生成されたドキュメントの内容や質を完全には捉えることができず、これが性能評価の大きな障害となっています。
- コード要約やドキュメント生成におけるコーパスの限界は、新しい文脈やセマンティクスの理解に対するLLMの能力を制約する可能性があります。
- 生成されたドキュメントの正確性や信頼性を確保するための包括的な方法論やシステムが不足しているため、実際のアプリケーションでの採用が困難である可能性があります。
要約:
- LLMはドキュメント生成とコード要約の領域で進展しています。
- 評価の障壁、データ制約、および出力の信頼性確保が解決すべき課題。
関連論文:
| タイトル | 概要 |
|---|---|
| [2305.12865] Automatic Code Summarization via ChatGPT: How Far Are We? | ChatGPTを使ってPythonコードの要約能力をテストしましたが、他のモデルよりも性能が低かった。 |
| [2304.06815] Automatic Semantic Augmentation of Language Model Prompts (for Code Summarization) | GPT-3.5でコード要約の精度を高めるために、特別な指示を与える方法(プロンプトエンジニアリング)を用いました。 |
| [2304.11384] Large Language Models are Few-Shot Summarizers: Multi-Intent Comment Generation via In-Context Learning | 既存の言語モデルがコードの異なる技術的側面からの要約を生成できる能力を持っていることを確認しました。 |
全体要約&結論
1. LLMの現状:
- 研究の進行中: LLMは、コード補助、レビュー、バグ修正、リファクタリングなど、ソフトウェア開発のさまざまな側面に適用され始めています。しかしながら、その効果を最大限に引き出す技術やフレームワークの開発はまだ進行中の段階です。
- 増加する採用事例: 企業や開発プロジェクトにおいて、コード生成や最適化を助けるためのLLMの採用が増えています。特に時間とリソースを節約するためのツールとしての関心が高まっています。
2. LLMのできること:
- コード生成と補助: LLMは、特定の入力パラメータや要求に基づいて、効率的なコードスニペットの生成を行うことができます。これにより、開発者はより複雑な問題に集中することができるようになります。
- リファクタリングと最適化: コードの構造を改善し、パフォーマンスを向上させるためのリファクタリングや最適化の提案を行う能力を持っています。これには、既存のコードの問題点を特定し、それを解決するための解決策を提供することも含まれます。
- バグ検出と修正: コード内の潜在的なバグを特定し、それらを修正するための提案を行うことができます。これは、コードの品質を保証し、将来的な問題を防ぐのに役立ちます。
3. リスクと制約:
- 正確性と信頼性の問題: LLMが生成するコードや提案は常に正しいとは限らないため、開発者はこれらの出力を盲目的に信頼せず、徹底的にレビューとテストを行う必要があります。
- コンテキストの理解: 現状のLLMは、プロジェクトの特定の文脈やニュアンスを完全に理解することはできません。そのため、一般的なソリューションは適切かもしれませんが、特定の問題に対する最適なソリューションを提供することはできない場合があります。
- セキュリティと倫理的な懸念: 自動生成されたコードは未検証であることが多く、セキュリティリスクを抱える可能性があります。また、LLMの判断基準が倫理的観点で常に適切であるとは限らないため、使用の際には慎重な判断が必要です。