
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
最近、オープンソースかつ商用利用可能なLLMを日本語に対応させるファインチューニングが注目を集めている中、商用利用可能な日本語データセットを用いてMPT-7Bをファインチューニングしてみました。

はじめに
こんにちは、アナリティクスサービス部の内田です。
最近、オープンソースかつ商用利用可能なLLMを日本語に対応させるファインチューニングが注目を集めています。上記のようなLLMを使用すれば、ChatGPTやそのAPIとは異なり、オンプレ環境やクラウド環境で実行する場合だと機密情報が外部に送信されることはありません。そのため、日本語対応しているLLMが必要にも関わらず、ChatGPTやAPIが導入できない状況においては非常に有用です。
特に、MosaicMLが開発したMPT-7B(MosaicML Pretrained Transformer 7B)は、テキストとコードの1Tトークンでゼロから学習されたLLMとして注目されています。このモデルはオープンソースかつ商用利用可能であり、LLAMA-7Bに匹敵する性能を誇っています。さらに、FlashAttentionおよびFasterTransformerの活用により、学習と推論の高速化が最適化されており、オープンソースのトレーニングコードも公開されています。
本稿では、商用利用可能な日本語データセットを用いてMPT-7Bをファインチューニングしました。
これにより日本語処理可能なモデルを構築し、性能評価と簡単なチャットボットの構築を行いました。
またファインチューニングには、LLM Foundry(Apach 2.0)というMosaicMLが公開しているリポジトリを利用しています。
今回作成したモデルについては以下をご参照ください。
| 作成したモデル | ベースにしたモデル |
|---|---|
| https://huggingface.co/Jumtra/mpt-7b-base | mosaicml/mpt-7b(Apach 2.0) |
| https://huggingface.co/Jumtra/mpt-7b-inst | mosaicml/mpt-7b-instruct (CC BY SA 3.0) |
環境構築
実行環境は以下の通りです。
| クラウド環境 | GCP |
| マシンタイプ | a2-highgpu-4g |
| GPU | A100(40GB) × 4 |
| python | 3.10.11 |
| cuda | 11.4 |
| torch | 1.13.1 |
※GCPにpreinstallされているcudaだとversionが合わないため、cuda11.4を使用
仮想環境はpyenvを使い必要なパッケージをインストールしました。
# pyenvを使用 pyenv install 3.10.11 pyenv global 3.10.11 # pipの準備 python -m pip install --upgrade pip python -m pip install wheel setuptools # torch=1.13.1をインストール python -m pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 # llm-foundryをインストール git clone https://github.com/mosaicml/llm-foundry.git cd llm-foundry python -m pip install -e ".[gpu]"
データセットの作成
以下の日本語データセットを結合して学習しました。
GitHub - kunishou/oasst1-89k-ja
OpenAssistant のオープンソースデータ OASST1 を日本語に翻訳したデータセットであり、ライセンスは「Apach 2.0」であるため商用利用可能です。
GitHub - kunishou/databricks-dolly-15k-ja
databricks/dolly-v2-12b の学習データに使用されたdatabricks-dolly-15k.jsonl を日本語に翻訳したデータセットであり、ライセンスは「CC BY SA 3.0」であるため商用利用可能です。
GitHub - yahoojapan/JGLUE: JGLUE: Japanese General Language Understanding Evaluation
JSQuAD*1は、JGLUEプロジェクトの一部として作成された日本語版GLUEの一つです。このデータセットを使用して、日本語の知識ベースに基づいた自然な回答の生成を期待して学習を行いました。商用利用可能であり、ライセンスは「CC BY SA 4.0」でndryを用いた学習をする場合、以下の形式に変換する必要があるので、結合後のデータセットに対して変換を行いました。
| prompt | response |
|---|---|
| "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: ベクターデータは、ポイント (点)、ライン (線)、何(面)の3要素で表現したベクター形式のデータである。以下の文を参考に答えてください。 ベクターデータは、ポイント (点)、ライン (線)、ポリゴン (面)の3要素で表現したベクター形式のデータである。測量や地図のトレース、CADデータなどからの変換によって得られる。 ### Response: " | "ポリゴン" |
学習
次の2つのモデルを対象にllm-foundryリポジトリに従ってfinetuneを行いました。
- https://huggingface.co/mosaicml/mpt-7b
- mpt-7bのベースモデル
- https://huggingface.co/mosaicml/mpt-7b-instruct
- mpt-7bをinstruct-tuneしたモデル
また、学習の設定ファイルはリポジトリ内のllm-foundry/train/yamls/mpt/finetune/7b_dolly_sft.yamlを使用しました。
パラメータはepoch数とバッチサイズのみを変更し、データセットは作成したデータセットを用いて学習しました。
| パラメータ名 | 値 |
|---|---|
| max_duration | 5ep |
| batch_size | 32 |
CLIで以下を実行して学習をする。
composer scripts/train/train.py \ train/yamls/mpt/finetune/custom_data.yaml # 学習設定が書かれたyaml
学習後のモデルをhuggingfaceで使えるように変換する。
python scripts/inference/convert_composer_to_hf.py \ --composer_path ./result/model.pt \ # 変換対象のモデルのpath --hf_output_path ../scratch/output \ # 変換後のhf_modelを保存するpath --output_precision bf16
性能評価
モデルの生成結果に対して、日本語の問題に正しい知識を解答できているかどうかの定量的評価と、人間の指示に対して不自然な解答を行っていないかどうかを確認する定性的評価を行いました。
- 定量的評価では、JGLUEのJCommonsenseQA*2というデータセットの100問を使用し、各モデルにおける正答率を算出しました。
- 定性的評価では、オープンクエスション、テキストに関する質問、要約タスクにおいてモデルの生成結果について比較を行いました。
モデルは以下の4つのモデルを使用して生成結果の比較を行いました。
| モデル名 | 概要 |
|---|---|
| mosaicml/mpt-7b | MosaicMLが公開したベースモデル(Apach 2.0) |
| mosaicml/mpt-7b-instruct | mpt-7bをMosaicMLがfinetuneしたモデル(CC BY SA 3.0) |
| Jumtra/mpt-7b-base | mpt-7bを日本語データセットでfinetuneしたモデル |
| Jumtra/mpt-7b-inst | mpt-7b-instructを日本語データセットでfinetuneしたモデル |
生成時のパラメータは全てのモデルで以下のものを使用しました。
| パラメータ名 | 値 |
|---|---|
| max_new_tokens | 1024 |
| do_sample | True |
| temperature | 0.01 |
| top_p | 0.01 |
| repetition_penalty | 1.1 |
| return_dict_in_generate | True |
※表以外のパラメータはデフォルト値を使用
定量的評価
以下の表にそれぞれのモデルにおける正答率を示す。
| model name | 正答率 |
|---|---|
| mosaicml/mpt-7b | 16/100 |
| mosaicml/mpt-7b-instruct | 28/100 |
| Jumtra/mpt-7b-base | 47/100 |
| Jumtra/mpt-7b-inst | 46/100 |
mpt-7bとmpt-7b-instructの両モデルについて、ファインチューニング後のモデルの方が正答率が高くなっていることが分かります。
ファインチューニング前のモデルでは、事前学習による知識は得られているはずなので、日本語に関する学習量が不足しているため、正答率が著しく低くなっていると考えられます。
解答内容について参考として、以下にそれぞれのモデルにおける解答の例を載せます。
| 質問 | 主に子ども向けのもので、イラストのついた物語が書かれているものはどれ?以下の選択肢から答えてください。選択肢 0.世界1.写真集2.絵本3.論文4.図鑑 |
|---|---|
| 正解 | 2.絵本 |
| mosaicml/mpt-7b | この問題では、「子ども向けのもの」ということを意味するので、第2選択肢(絵本)が正解です。<|endoftext|> |
| mosaicml/mpt-7b-instruct | 4.図鑑<|endoftext|> |
| Jumtra/mpt-7b-base | 絵本<|endoftext|> |
| Jumtra/mpt-7b-inst | 絵本<|endoftext|> |
定性的評価
Q1. オープンクエスション
prompt
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: ニューラルネットワークとは何ですか?
| model name | output |
|---|---|
| mosaicml/mpt-7b | ニューラルネットワークとは、人間の知覚を模倣する機械学習モデルです。ニューラルネットワークは、多くのニューラルノード(ニューラルノードは、入力データに対して特定の関数を適用し、出力データを生成します)からなる構造であり、各ニューラルノードは、前のニューラルノードから受け取った入力データを使用して、次のニューラルノードへの出力データを生成します。このような構造により、ニューラルネットワークは、入力データに対して複雑な処理を行うことができます。<|endoftext|> |
| mosaicml/mpt-7b-instruct | ニューラルネットワーク(NN)とは、人間の知覚力を模倣する機械学習モデルである。人間の知覚力では、単語や文章などの意味を抽出することもできるが、ニューラルネットワークにはその能力がないため、意味を抽出するために特殊なアルゴリズムを用いている。<|endoftext|> |
| Jumtra/mpt-7b-base | ニューラルネットワーク(NN)は、人工知能の分野で最も重要なアプローチの1つです。これらのモデルは、自動学習を使用して、大量のデータから学習されたパターンや関係を特定することができます。ニューラルネットワークは、人間の脳に似たように機能します。<|endoftext|> |
| Jumtra/mpt-7b-inst | ニューラルネットワーク(NN)は、人工知能の分野で使用される深い学習アルゴリズムの一種です。これらのアルゴリズムは、データを使って自動的に学習し、特定の目的を達成するために予測や決定を行うことができます。ニューラルネットワークは、多くの異なるアプリケーションで使用されており、自動車の運転システム、検索エンジン、画像認識などです。<|endoftext|> |
どのモデルもそれらしいことを出力していることが分かります。
Q2. オープンクエスション(計算能力を問う問題)
prompt
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: 1個100円のリンゴを5個買うためには何円必要ですか?
| model name | output |
|---|---|
| mosaicml/mpt-7b | 1個100円のリンゴを5個買うためには500円必要です。<|endoftext|> |
| mosaicml/mpt-7b-instruct | 500円<|endoftext|> |
| Jumtra/mpt-7b-base | 105円<|endoftext|> |
| Jumtra/mpt-7b-inst | 500円<|endoftext|> |
苦手とされる計算問題も Jumtra/mpt-7b-base 以外は解けています。ファインチューニング前のモデルでも解けているので、mpt-7b は優秀ですね。
Q3. テキストに関する質問
prompt
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: ブレインパッドはいつ創業しましたか?以下の文を参考に答えてください。 ブレインパッドは、2004年に「データ活用の促進を通じて持続可能な未来をつくる」をミッションに掲げて創業しました。以来、現在まで変わらずに本ミッションを掲げ続けています。ブレインパッドは、今後もクライアント企業のよき変革パートナーとして、ともに日本のみならず世界に誇れる先進事例を生み出し、世界を持続可能なものとするべく、次代に繋いでいきます。
| model name | output |
|---|---|
| mosaicml/mpt-7b | ブレインパッドは2004年にデータ活用の促進を通じて持続可能な未来をつくるというミッションに創業しました。<|endoftext|> |
| mosaicml/mpt-7b-instruct | ブレインパッド was founded in 2004 with "promoting data utilization to create sustainable futures." Since then, it has continued to uphold this mission. Breinpad will continue to be a partner for clients and pioneer advanced examples of Japan as well as the world towards creating sustainable things into future generations.<|endoftext|> |
| Jumtra/mpt-7b-base | 2004年<|endoftext|> |
| Jumtra/mpt-7b-inst | 2004年<|endoftext|> |
ファインチューニング前のモデルでは英語で答えたり、冗長に答えたりしてますが、ファインチューニング後だと端的に解答しています。
Q4. テキストに関する質問
prompt
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: ブレインパッドのミッションはなんですか?以下の文を参考に答えてください。 ブレインパッドは、2004年に「データ活用の促進を通じて持続可能な未来をつくる」を ミッションに掲げて創業しました。以来、現在まで変わらずに本ミッションを掲げ続けています。 ブレインパッドは、今後もクライアント企業のよき変革パートナーとして、 ともに日本のみならず世界に誇れる先進事例を生み出し、世界を持続可能なものとするべく、 次代に繋いでいきます。
| model name | output |
|---|---|
| mosaicml/mpt-7b | ブレインパッドのミッションは、データ活用の促進を通じて持続可能な未来をつくることです。<|endoftext|> |
| mosaicml/mpt-7b-instruct | The mission of Breinpad was to "promote data utilization for sustainable future" when it started in 2004 and has been continuing this mission ever since then. It will continue doing so even after now, as they have not changed their original vision yet.<|endoftext|> |
| Jumtra/mpt-7b-base | データ活用の促進を通じて持続可能な未来をつくる<|endoftext|> |
| Jumtra/mpt-7b-inst | データ活用の促進を通じて持続可能な未来をつくる<|endoftext|> |
ファインチューニング前のmpt-7b-instructでは英語で答えていますがmpt-7bでは自然な解答を生成できています。Q3と同じくファインチューニング後だと端的に解答しています。
Q5. 要約タスク
prompt
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: 以下の文章を要約してください。 ブレインパッドグループは、数理統計学などの知識と機械学習・深層学習といった先進技術を活用した アナリティクス技術と、アナリティクス技術を取り入れた自社製品やシステム構築を行う エンジニアリング技術を駆使し、データを活用した経営改善の手伝いをクライアント企業向けに行う。 【事業内容】同社は3つの事業を運営する。アナリティクス事業は顧客企業の有する大量データに関する コンサルティングおよびデータマイニング(企業と社会に大量に蓄積されるデータを解析し、 その中に潜む重要パターンや法則性を抽出すること)の実行、ならびにデータに基づく企業行動の最適化支援を行う。 ソリューション事業は顧客企業に対して、データ蓄積、分析および分析結果に基づく 施策実行に必要なソフトウェアの選定および提供ならびにシステム開発および運用を行う。 マーケティングプラットフォーム事業は主にデジタルマーケティング領域において、 同社が着目したデータ分析系のアルゴリズムから独自性の強いソフトウェアを自社開発し、 サース(SaaS)型サービスを中心とした顧客企業への提供と、その保守業務等を行う。
| model name | output |
|---|---|
| mosaicml/mpt-7b | ブレインパッドグループは、数理統計学などの知識と機械学習・深層学習といった先進技術を活用したアナリティクス技術と、アナリティクス技術を取り入れた自社製品やシステム構築を行うエンジニアリング技術を駆使し、データを活用した経営改善の手伝いをクライアント企業に行う。 事業内容 アナリティクス事業は顧客企業の有する大量データに関するコンサルティングおよびデータマイニング(企業と社会に大量に蓄積されるデータを解析し、その中に潜む重要パターンや法則性を抽出すること)の実行、ならびにデータに基づく企業の最適化支援を行う。 ソリューション事業は顧客企業に対して、データ蓄積、分析および分析結果に基づく戦略実行に必要なソフトウェアの選定および提供、またシステム開発および運用を行う。 マーケティングプラットフォーム事業は主にデジタルマーケティング領域において、同社が注目しているデータ分析系アルゴリズムから独自性の高いソフトウェアを自社開発し、サース型サービスを顧客企業へ提供し、その保守業務等を行う。<|endoftext|> |
| mosaicml/mpt-7b-instruct | The Brein Pad Group provides advanced analytics technologies and artificial intelligence (AI), such as machine learning, deep learning techniques to utilize knowledge of statistics etc., in addition to engineering expertise for developing products and systems utilizing these cutting-edge technologies, with the aim of providing data analysis services to client enterprises while conducting business improvement initiatives based on utilization of customer's large amount of data. [Business Description] The Company operates three businesses. Its Analytics Business performs consulting regarding big amounts of data owned by customers' enterprise clients along with performing Data Mining (extracting important patterns or laws from massive accumulated data which are hidden within them). In addition it also offers support for optimizing corporate operations based on analyses derived using this data. Solution Business develops software required necessary for implementing strategies determined through analyzing data collected via customer companies’ accumulation of data including system development & maintenance work related thereto. Marketing Platform Business mainly engages in digital marketing activities targeting at offering proprietary softwares developed upon algorithms focused on data mining capabilities unique to our company together with SaaS type service provisioning towards customer corporations engaged into various fields ranging from IT solution providers to financial institutions; furthermore engaging in operation management relating therewith.<|endoftext|> |
| Jumtra/mpt-7b-base | ブレインパッドグループ<|endoftext|> |
| Jumtra/mpt-7b-inst | ブレインパッドグループは、データ分析を活用した経営改善の手伝いをクライアント企業向けに行っている。<|endoftext|> |
ファインチューニング前のモデルでは、英語で回答したり、入力文をそのまま回答したりしています。一方、ファインチューニング後のモデルでは、まとめすぎている傾向はあるものの、Jumtra/mpt-7b-instを用いることでそれらしい回答が得られています。
生成パラメータを調整することで、このあたりは改善される可能性があります。
チャットボットの構築
定量的評価で正解率が最も高かった「Jumtra/mpt-7b-base」を用いてチャットボットを作成しました。
今回は、ドキュメントを参考にGradioで構築しました。
以下がチャットボット上での応答の様子です。
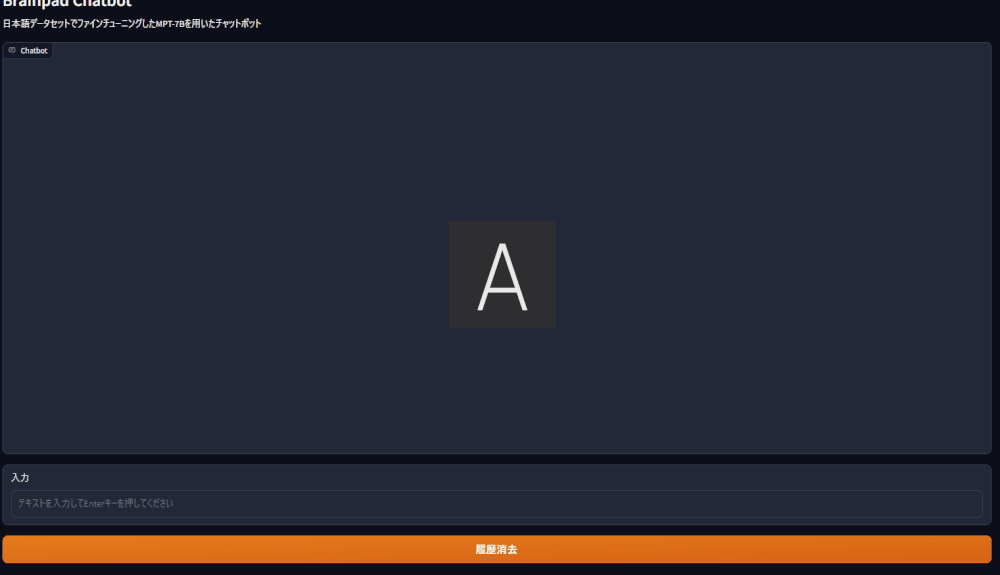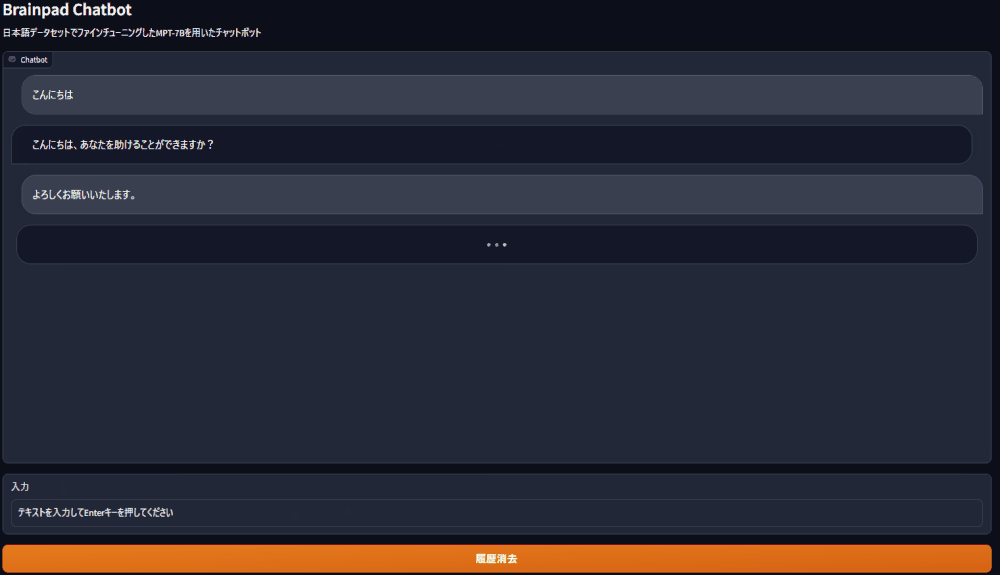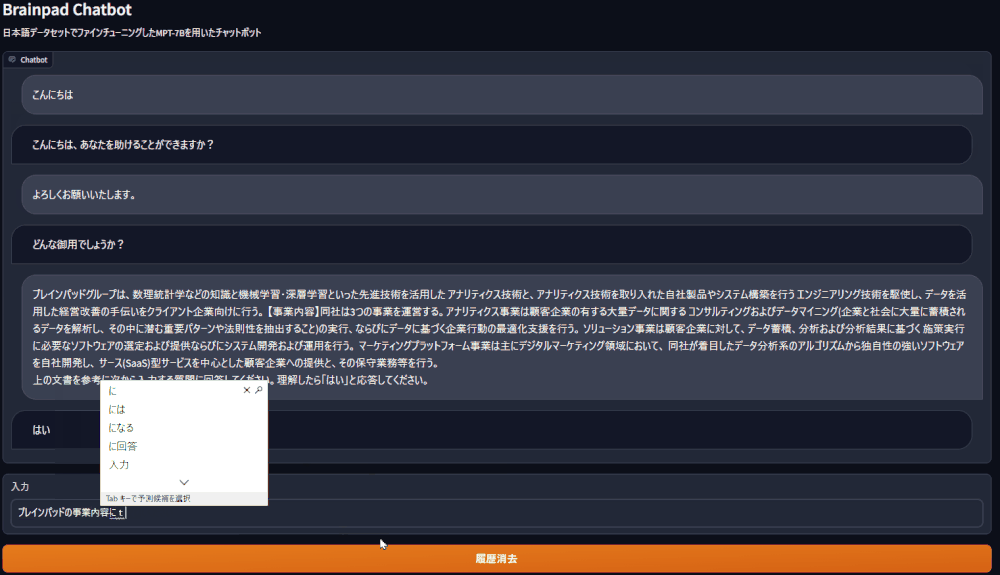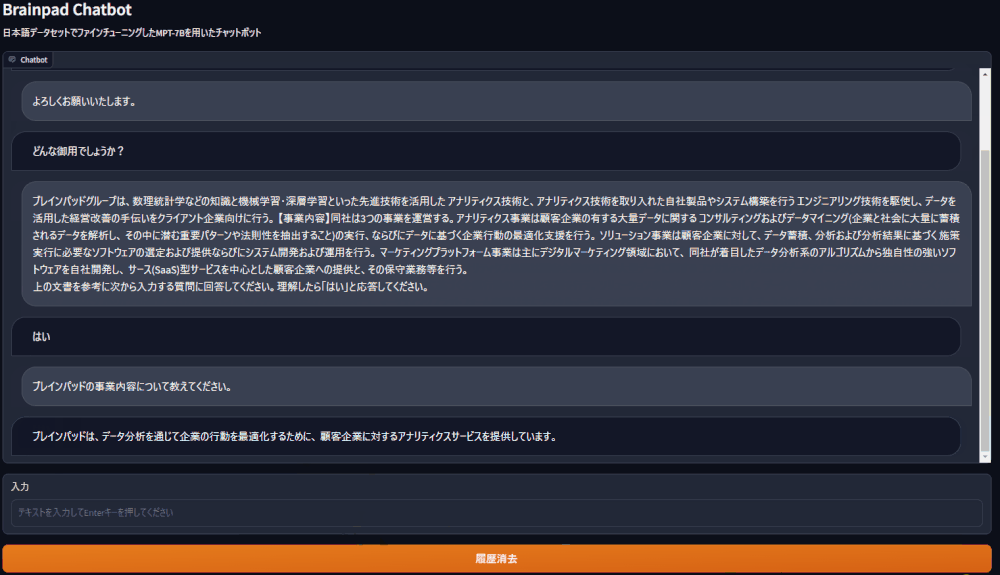
内部的には、チャットの履歴を全て保持してモデルに入力しています。
例えば、最後の質問「ブレインパッドの事業内容について教えてください。」では以下のような入力を与えています。
user:こんにちは
system:こんにちは、あなたを助けることができますか?
user:よろしくお願いいたします
system:どんな御用でしょうか?
user: ブレインパッドグループは、数理統計学などの知識と機械学習・深層学習といった先進技術を活用した
アナリティクス技術と、アナリティクス技術を取り入れた自社製品やシステム構築を行う
エンジニアリング技術を駆使し、データを活用した経営改善の手伝いをクライアント企業向けに行う。
【事業内容】同社は3つの事業を運営する。アナリティクス事業は顧客企業の有する大量データに関する
コンサルティングおよびデータマイニング(企業と社会に大量に蓄積されるデータを解析し、
その中に潜む重要パターンや法則性を抽出すること)の実行、ならびにデータに基づく企業行動の最適化支援を行う。
ソリューション事業は顧客企業に対して、データ蓄積、分析および分析結果に基づく
施策実行に必要なソフトウェアの選定および提供ならびにシステム開発および運用を行う。
マーケティングプラットフォーム事業は主にデジタルマーケティング領域において、
同社が着目したデータ分析系のアルゴリズムから独自性の強いソフトウェアを自社開発し、
サース(SaaS)型サービスを中心とした顧客企業への提供と、その保守業務等を行う。
上の文書を参考に次から入力された質問に回答してください。理解したら「はい」と応答してください。
system: はい
user: ブレインパッドの事業内容について教えてください。
system:
チャットボットの応答から、日本語を理解して応答出来ていることが分かります。
また、応答速度も良いことがGIFから分かります。(GIF上の応答時間は実際の応答時間に相当)簡単に日本語でファインチューニングしたモデルでしたが、ちょっとしたチャットボット等としては活用できるのではないかと思います。
まとめ
本稿では、MPT-7B商用利用可能な日本語データセットを用いてをファインチューニングすることで、日本語処理可能なモデルを構築し、性能評価と簡単なチャットボットの構築を行いました。
定量的評価ではJGLUEのJCommonsenseQAデータセットを使用し、正答率を算出しました。その結果、ファインチューニング後のモデルの方が正答率が高くなっており、日本語に関する学習量が不足していたファインチューニング前のモデルと比較して、性能向上が見られました。
また、ファインチューニング後のモデルは、計算問題やオープンクエスション、テキストに関する質問、要約タスクにおいても優れた結果を示しました。ファインチューニング前のモデルでは、英語で回答したり冗長な回答をしたりする傾向が見られましたが、ファインチューニング後のモデルでは、日本語で解答を生成するようになりました。応答速度も良く、簡単なチャットボット等として活用できる可能性があります。
参考文献
- Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs | Databricks Blog
- GitHub - kunishou/databricks-dolly-15k-ja
- GitHub - kunishou/oasst1-89k-ja
- GitHub - yahoojapan/JGLUE: JGLUE: Japanese General Language Understanding Evaluation
- ブレインパッドの企業情報 | type就活
- https://chat.openai.com/
- Gradio Interface Docs