
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
今回は、新しいコードサジェストツール「TabbyML/Tabby」についてご紹介します。

- 想像以上に低スペックなマシンでも動作するTabbyML/Tabby
- ベースモデルを入れ替えると何が変わる?
- TabbyML/Tabby をクラウドで動作させ、ローカルマシンからアクセスできる?
- 最後に
- 参考記事例
こんにちは、アナリティクス本部の町田、武藤、安田です。
今回は、コードサジェストに関する話題を取り上げたいと思います。なお、コードサジェストとは、プログラミング中にコードを書く際に、自動的にコードの補完や予測を行ってくれる機能のことです。
コードサジェスト分野でも他の LLM モデル同様に、さまざまなモデルや周辺ツールが日夜を問わずに発表されたり、更新されています。
私たち受託系データ活用・分析企業で働く者は大抵の場合は新しいもの好きなため、昨今の新しい技術を普段の業務でも利用したくてうずうずしています。
例えば GitHub Copilot や Amazon CodeWhispererは今やだれもが注目しているツールですが、とにかく普段の業務で使えたらなと思っています。
しかし、私たちのような受託系データ活用・分析企業は、お客様の大切なデータをお預かりして分析するという業務特性の問題でこれらの楽しそうなツールを普段の業務で利用できません。
弊社はお客様の大切なデータをお預かりしているため、外部と通信を行うサービスの利用は慎重に判断を行っています。
セキュリティの問題が解決しない限り、ほんの少しの情報であってもお客様の情報を他社に渡してしまうことは絶対に避けなければなりません。
そのようなことは十分に理解して日々の分析業務に取り組んでおりますが、それでも、やっぱり、新しいツールは使いたいんですよね。
そんな私たちのような場合でも、職業倫理に反せず、セキュリティリスクを避けることができれば、コードサジェストツールを使うことができるはずです。
ということで今回は、オープンソースソフトウェアで、ローカル環境だけで動作するコードサジェストツールである TabbyML/Tabby についてご紹介したいと思います。
TabbyML/Tabbyは2023年3月にGithubで最初のコミットが確認できる新しいコードサジェストツールです。
現在補完に対応している言語はPython, JavaScript, TypeScriptの3言語になっています。より多くの言語に対応を試みている開発ブランチも存在しているので、今後の成長が楽しみなOSSですね!
TabbyML/Tabby の紹介記事や投稿は、既に多くの企業様や個人の方が報告されているので、本記事では「データ分析者が100人以上いる部署で、全員がTabbyML/Tabbyを利用することにしたら」という観点で実施した実験結果を報告しようと思います。
本記事でご報告することは次の3点になります。
- 想像以上に低スペックなマシンでも動作するTabbyML/Tabby
- ベースモデルを入れ替えると何が変わる?
- TabbyML/Tabby をクラウドで動作させ、ローカルマシンからアクセスできる?
余談にはなりますが、広く LLM 関係の最新の情報などについては、弊社の有志で運用している OpenBP Twitter でも最新の情報をご共有させていただいておりますので、もしご興味がありましたらフォローをよろしくお願いいたします!有志のメンバーの励みになります!
想像以上に低スペックなマシンでも動作するTabbyML/Tabby
TabbyML/Tabbyをローカル環境で動作させるためのHOWTOについては、既に多くの企業や個人の方たちによって記事や話題にされております。
そのため、ローカル環境でTabbyML/Tabbyを動作させるためのスクリプトなどについては先達の記事をご参照いただければと思います。
例えばこちらの記事はSNS上で話題になってから早いうちに記事を出されており、TabbyML/Tabby が日本国内に周知されることになったきっかけかと思います。
「ローカルPCでセルフホストできてGithub Copilotのように使えるコーディング補助AI「tabby」、Dockerイメージありなので早速使ってみたレビュー - GIGAZINE (2023年04月10日 06時00分)」
(いつも楽しい記事をありがとうございます!)
さて、上記の記事をはじめとして記事執筆者が確認したかぎり日本語記事やSNS上の声では、「TabbyML/Tabbyは多くのメモリ(RAM)を使用する」ということが噂されております。
本節では、TabbyML/Tabbyは本当に多くのメモリ(RAM)を使用するのかということについて検証してみたいと思います。
もしメモリ(RAM)が30GBも必要だとすると大抵の会社貸与PCでは動作することができないでしょうし、メモリ(RAM)が32GBも積んであるノートPCで動作させることができたとしてもほとんど作業なんてできないでしょうから重要なポイントです。
結果から申し上げますと、TabbyML/Tabbyにはそこまで多いメモリ(RAM)は必要ありませんでした。
数人程度の利用であれば、おそらくメモリ(RAM)は2, 3GBもあれば動作はさせることができるかと思います。
私たちの検証時には、TabbyML/Tabbyの公式READMEに記載のあるGet started の記載されている通りにDockerイメージからTabbyML/Tabbyを起動し、正しく補完が行われることを確認したのちに、freeやvmstat コマンドでメモリ(RAM)の使用量を確認をしました。
結果としましては、記事執筆者のプライベートマシンでも、後述するサーバー上でも3G程度のメモリ(RAM)使用量となりましたので、やはりTabbyML/Tabbyはメモリ(RAM)を30GBも必要とはしないようです。
なお、記事執筆者のプライベートマシンでは.wslconfig を編集しWSLが使用できるメモリ(RAM)上限を2GBにした実験も行いましたが、free, vmstat 、タスクマネージャーのどれを見ても最大2GBのメモリ(RAM)の使用量になっておりました。(多少2GBを超えるような数値も確認しましたが誤差かと思っております。)
ここまでのまとめとして、TabbyML/Tabbyを動作させるときの最低システム要件は以下のようになるかと思います。
- 2G以上のメモリ(RAM)
- Pascal or newer NVIDIA GPU (TabbyML/Tabbyの公式READMEに記載のあるGet started より)
ストレージに関してはDockerhubにアップロードされている公式のDockerイメージが圧縮時で12.61GBあり、展開時には30GB超となるため適切に選んでいただければと思います。
またあくまで推測する最低システム要件のため、実用上は余裕を持たせてあげる必要があると思います。
この程度の要件でしたら、みなさんの手元のマシンでも十分に動作させることができるのはないでしょうか。
また、サーバーを借りてホストするときにも、そのコストも比較的抑えられるのではないでしょうか。
ベースモデルを入れ替えると何が変わる?
話題は変わって、TabbyML/Tabbyの機能紹介です。
TabbyML/Tabbyを起動するためのデフォルトスクリプトでは、モデルに TabbyML/J-350Mが指定されています。
しかしながら、Hugging FaceにアップロードされているTabbyML/Tabbyのモデルを確認すると、上記のモデル以外にTabbyML/NeoX-70M, TabbyML/NeoX-1.3B という2つのモデルが公開されています。
簡単に入れ替えて動作できるなら、比べてみたくなるのが世の常なので3つのモデルの使用感を簡単に比較してみます。
今回の結果を先に記載しますと、TabbyML/J-350Mが最も良さそうだなと感じています。
ベースモデルの変更方法
TabbyML/Tabbyのベースモデルを変更するには、docker run実行コマンドの MODEL_NAME 部分を変更するだけです。
下記ではMODEL_NAME=TabbyML/J-350Mとなっています。
docker run \ --gpus all \ -it --rm \ -v "/$(pwd)/data:/data" \ -v "/$(pwd)/data/hf_cache:/home/app/.cache/huggingface" \ -p 5000:5000 \ -e MODEL_NAME=TabbyML/J-350M \ -e MODEL_BACKEND=triton \ --name=tabby \ tabbyml/tabby
ベースモデルごとの補完内容の変化
3つのベースモデルを変化させたときの補完例と参考情報について記載しています。
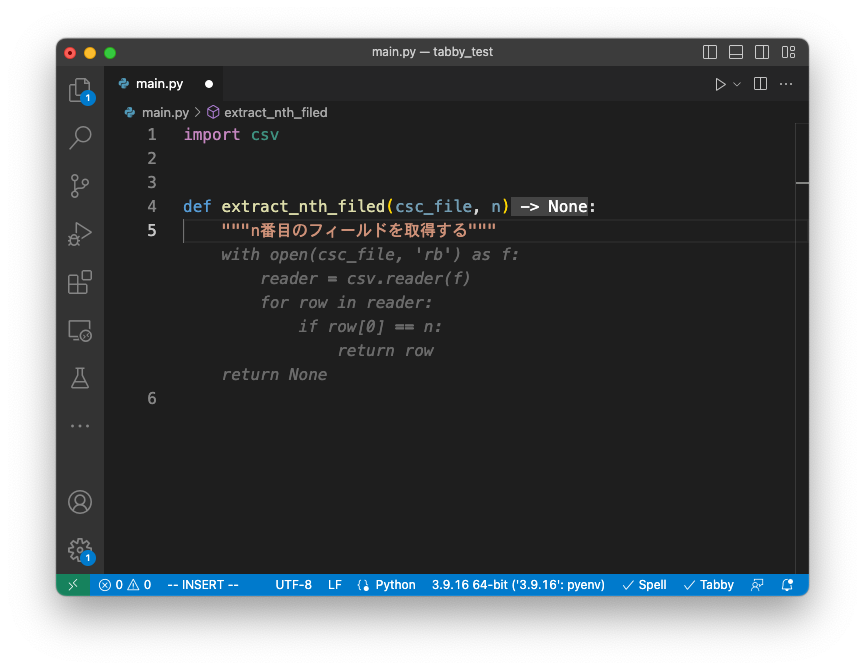
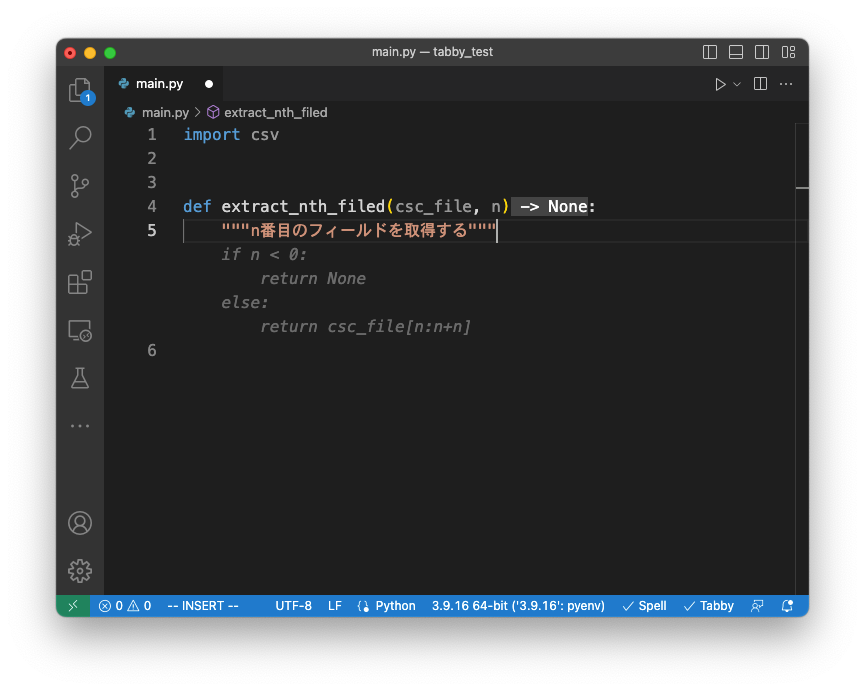
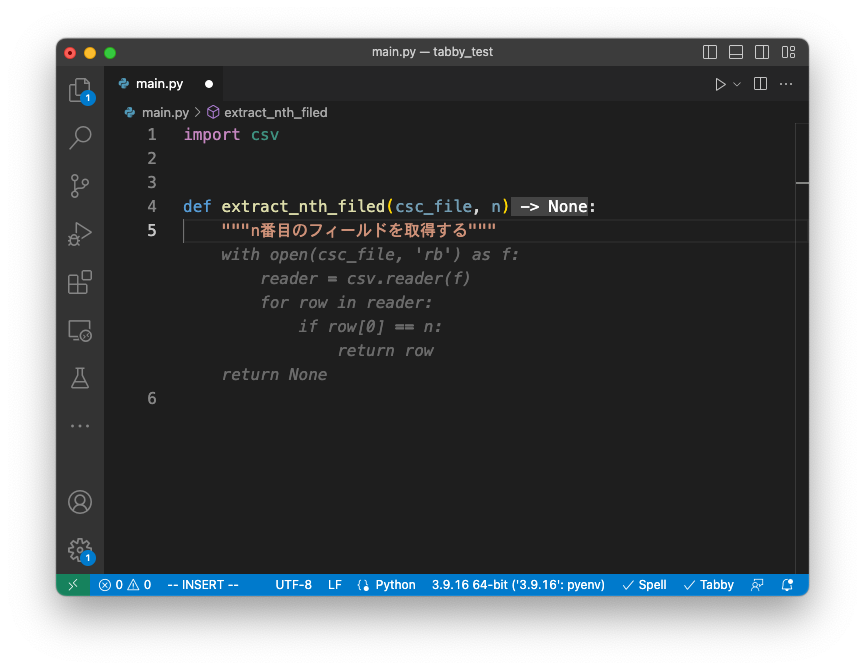
補完例に関しては、「与えたCSVファイルからN番目の列を取得する関数」を生成させてみました。
今回の例では、TabbyML/J-350M が返してきたコードが最もよさそうに見受けられます。
TabbyML/NeoX-70Mの補完例
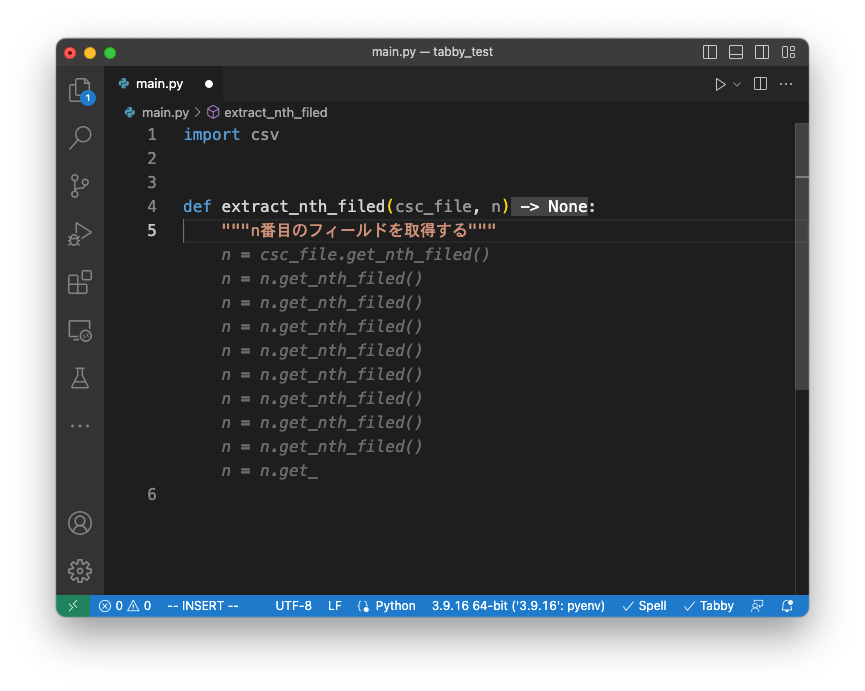
TabbyML/J-350Mの補完例
TabbyML/NeoX-1.3Bの補完例
また各モデルのサイズと実際に使用しているVRAMの使用量に関しても記載しました。
それぞれのモデルサイズに比例してVRAMの使用量も変化していますが、最も大きくても3.4G程度であり、GPUに対してもそこまでのリソースは求められていません。
表中の結果の内容は、GPUにT4を利用した結果ですが過剰だったかもしれませんね。なお記事執筆者のプライベートマシンに刺さっている2070 Superでも大きく結果は変わりませんでした。
| モデル | TabbyML/NeoX-70M | TabbyML/J-350M | TabbyML/NeoX-1.3B |
|---|---|---|---|
| Hugging Face URL | TabbyML/NeoX-70M · Hugging Face | TabbyML/J-350M · Hugging Face | TabbyML/NeoX-1.3B · Hugging Face |
| モデルサイズ*1 | 166MB | 797MB | 2.85GB |
| GPUメモリ(VRAM)使用量 | 0.83GB | 1.25GB | 3.41GB |
メモリ(RAM)だけでなく、GPUメモリ(VRAM)も高級なものも用意しなくてよいことが確認できました。
また、ベースモデルも簡単に切り替えることができることも分かったため、自社に蓄積されているコードを学習データにFine Tuningを行ったモデルを用意することさえできれば、業務内容に特化したコードサジェストの恩恵を受けることもできるかもしれません。
学習データセットを用意するコストや学習時のマシン費用は大きくかかってしまうかもしれませんが、夢が広がりますね。
TabbyML/Tabby をクラウドで動作させ、ローカルマシンからアクセスできる?
これまでで、TabbyML/Tabbyの動作には、メモリ(RAM)とGPUメモリ(VRAM)は高級なものを用意しなくてよいことが分かりました。
しかし私たちの野望は、「データ分析者が100人以上いる部署で、全員がTabbyML/Tabbyを利用することにしたら」です。
あまり高級なものを用意しなくてよいといっても、結構スペックの高いノートPCの貸与が中心の環境でも、毎回設定を行う手間だったり排熱などの問題で快適に動作するか怪しいところがあります。
そこでGithub CopilotやAmazon CodeWhispererのように処理はサーバーで行われ、補完候補のみがローカルマシンに表示されるようなことができないかを確認しました。
ここでは、GCP上でTabbyML/Tabbyを起動し、ローカルマシンのVSCodeで利用することを目指します。なお公式にVIM Extensionも用意されておりますので、お好みで選ばれるとよいかと思います。
以下の手順を踏むと、サーバーでTabbyML/Tabbyを起動し、各自のローカルマシンから接続するだけで、TabbyML/Tabbyの補完機能を使うことができるようになりました。
- GCPのインスタンスを作成
- GCPインスタンス上でDockerコンテナを起動
- VSCodeでTabbyML/Tabbyの拡張機能をインストール
- 拡張機能の設定からサーバーへ接続
1. GCPのインスタンスを作成
上述の通り、そこまでのリソースは必要ないため標準的な構成でインスタンスを作成します。
しかしながら、利用するDocker Imageが30GB程度あるため、ディスクサイズに関しては大きめに設定する必要があります。本記事では100GBに設定しています。
今回のインスタンス構成
- マシンタイプ:n1-standard-4(vCPU×4, メモリ: 15GB)
- メモリも15GBのn1-standard-4を利用しますが、もっと少なくても動きそうです
- GPU: T4×1枚
- Pascal以降で利用できるそうなので、T4でも過剰かもしれません。
- ディスク: 100GB
- NVIDIA GPUドライバがプリインストールされたDeep Learning VM Imageを利用
外部IPを固定化
URLが変更されるとVSCodeからの接続する際に毎回書き換えが必要になってしまうのでIPを固定化し、これを防ぎます。
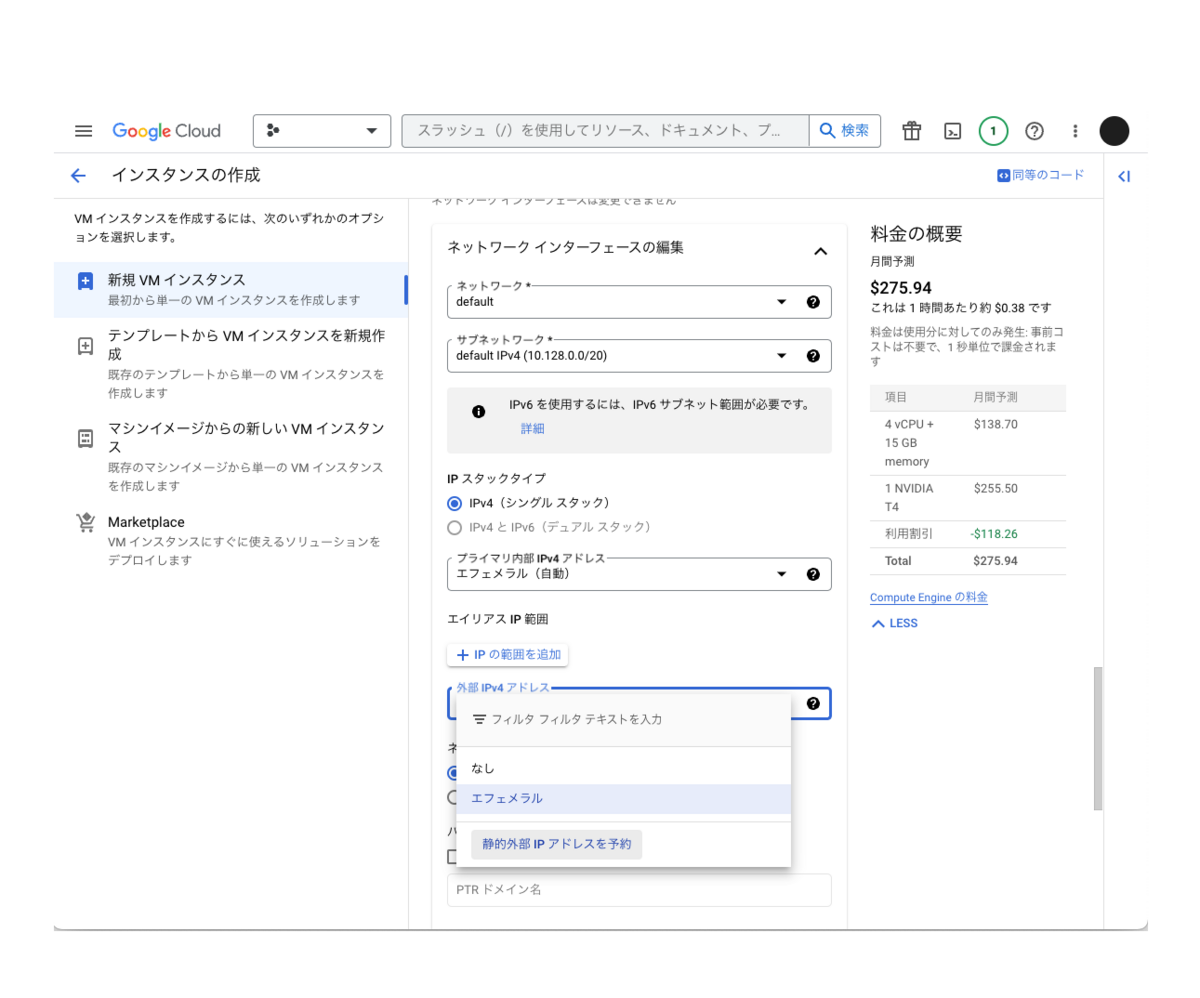
IP制限を作成
会社以外からアクセスできないようにするため、IPアドレスでアクセス制御します。
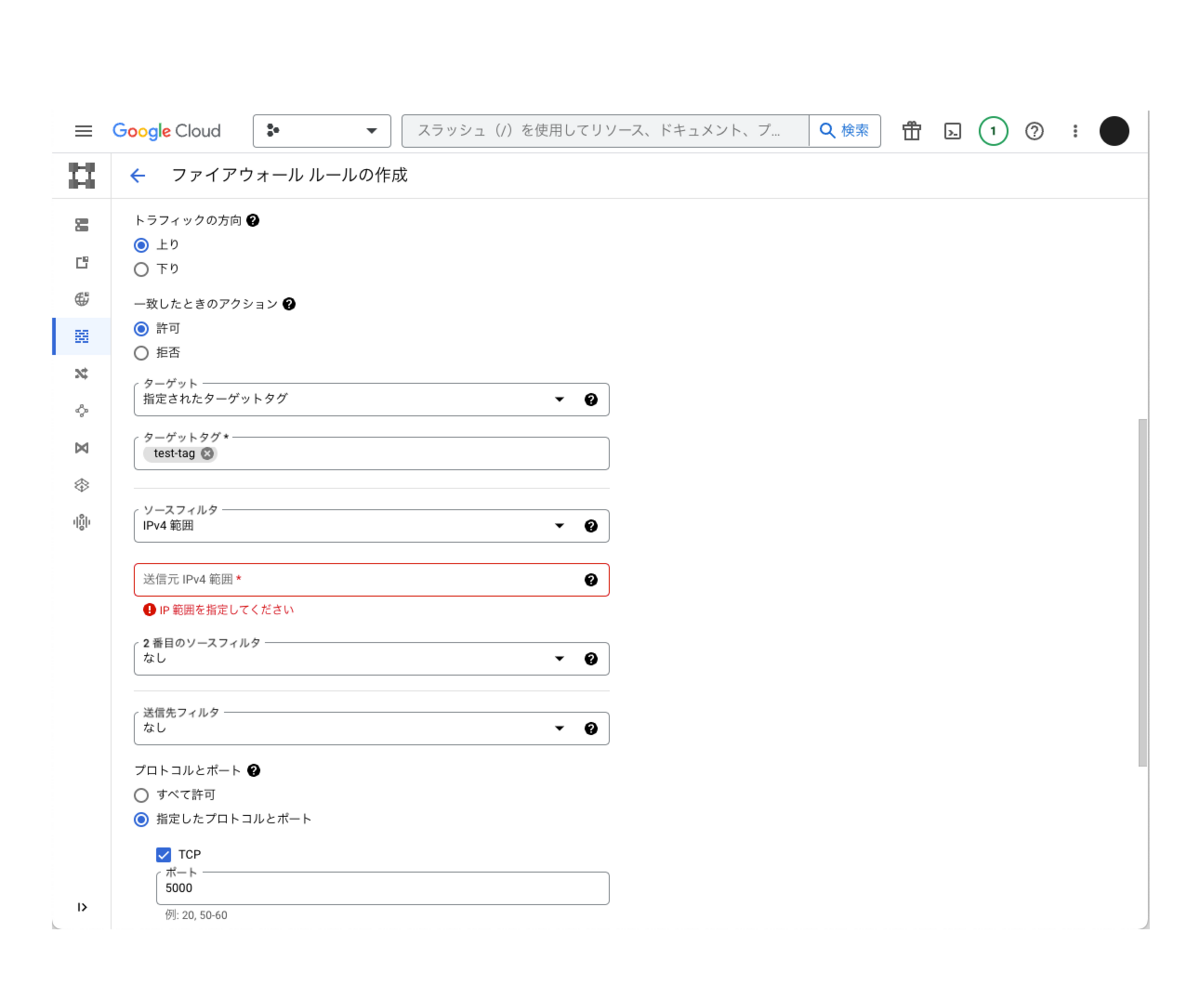
またその他にも下記の設定を実施しておきます。
- TCPの5000番ポートへの上りのトラフィックを許可する
- IPv4範囲にVPNのIPアドレスを入力(スクリーンショットの赤字部分)
- 適当な名前でターゲットタグを作成(スクリーンショットだと test-tag)し、そのタグをインスタンスに付与
2. GCPインスタンス上でdockerコンテナを起動
下記コマンドを実行し、Dockerコンテナを起動します。
コマンドは公式GithubのGet startedに記載のものをベースに以下の変更を行いました。
2回目以降もコンテナをstartするだけで使えるようにするため、 --rmオプションを削除
ベースモデルを入れ替える場合は、一度コンテナを消す必要があるかもしれません。( docker rm tabbyなどで対応)
# Create data dir and grant owner to 1000 (Tabby run as uid 1000 in container) mkdir -p data/hf_cache && sudo chown -R 1000 data docker run \ --gpus all \ -it \ -v "/$(pwd)/data:/data" \ -v "/$(pwd)/data/hf_cache:/home/app/.cache/huggingface" \ -p 5000:5000 \ -e MODEL_NAME=TabbyML/J-350M \ -e MODEL_BACKEND=triton \ --name=tabby \ tabbyml/tabby
(参考)コンテナのサイズ
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE tabbyml/tabby latest 47108b23f575 2 weeks ago 29.7GB
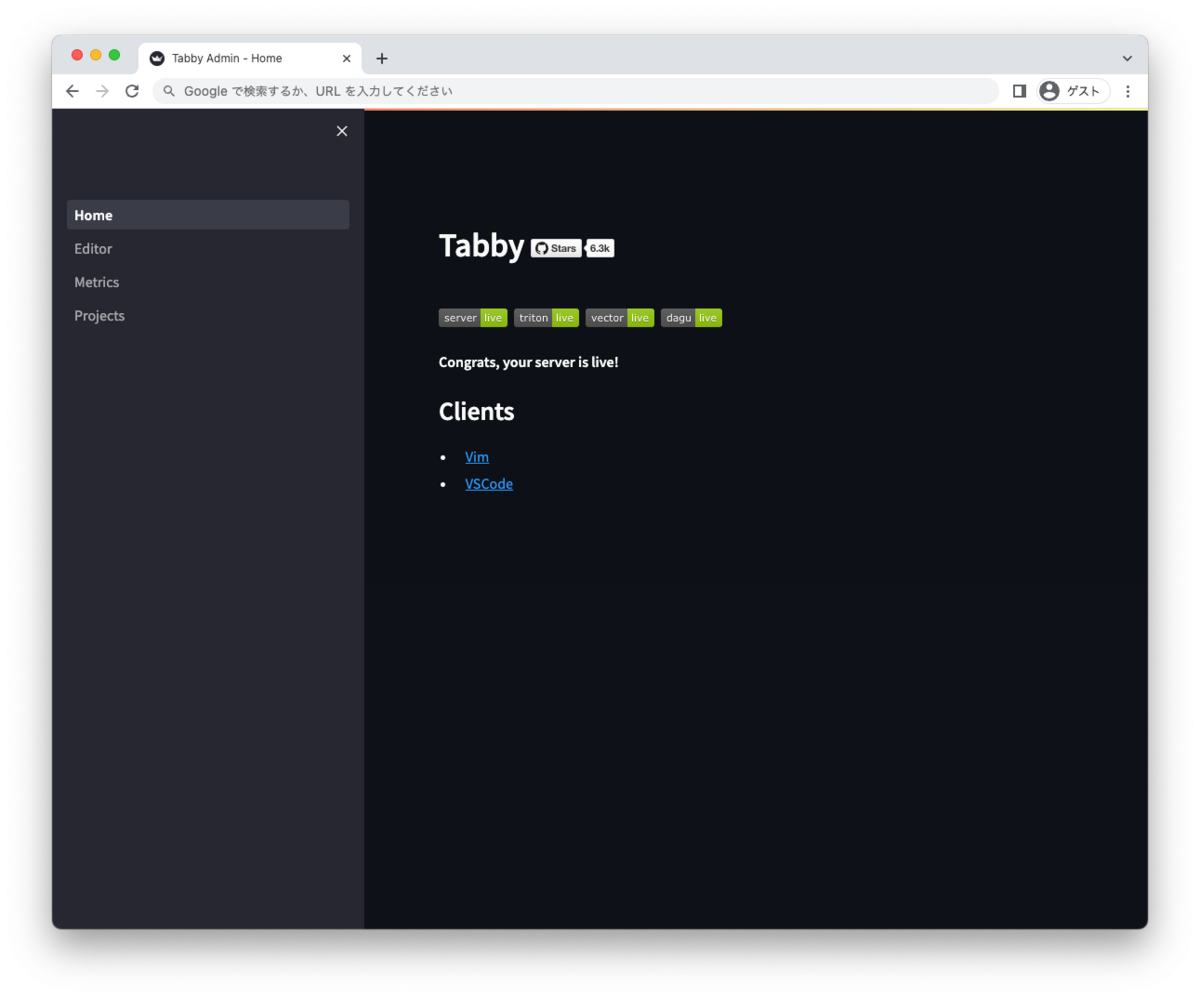
コンテナ起動後は、「http://<インスタンスの外部IPアドレス>:5000/_admin/」 にアクセスし、以下のようなページが表示できればローカルマシンからサーバーのTabbyML/Tabbyにアクセスができています。
3. VSCodeでTabbyMLの拡張機能をインストール
VSCodeでTabbyの拡張機能をインストールします。
Tabbyはトラネコを意味しますので、分かりやすいアイコンですね。
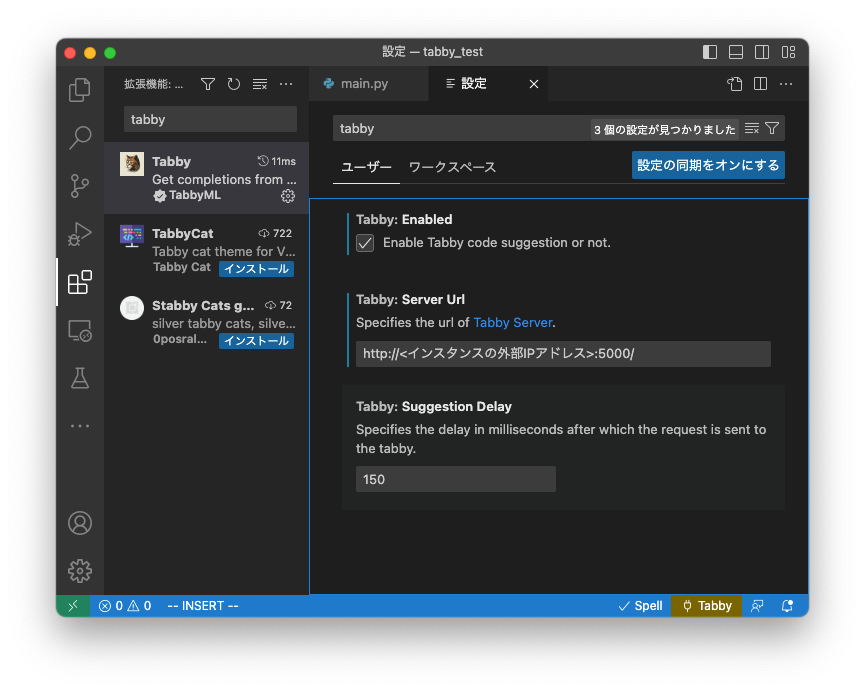
4. 拡張機能の設定からサーバーへ接続
インストール後、「拡張機能の設定」(上記画像の歯車をクリックし、選択)から、TabbyML/Tabbyが動作しているサーバーのアドレス(http://<インスタンスの外部IPアドレス>:5000/)を設定します。
これでサーバーで起動したTabbyML/Tabbyがローカルのエディタから使えるようになります。
補完が動いていることを確認してみます。
問題なく動いてそうです!
一度インスタンスを停止した後など、2回目以降に利用する際は docker start tabbyで利用が可能です。
複数人アクセス時ログ
3人で同時に補完機能を利用し、最も早かった人を基準に他の人がどれだけ遅れて補完されたかを計測しました。
検証にあたって100人同時動員は面倒だった難しかったので、有志の3人で検証を進めました。
そのためサーバーに100人同時接続したときのサーバー負荷やレスポンスなどについてはこの記事の範囲外になってしまいますことをご了承ください。
通信にかかるラグもあるので厳密なデータではありませんが、複数人での利用時も実用的なスピードで補完が可能でした。
| 補完された時間 | 最も早かった人からの差分 | |
|---|---|---|
| ユーザー1 | 05:49:10.458 | 0 |
| ユーザー2 | 05:49:10.937 | +0.479秒 |
| ユーザー3 | 05:49:11.425 | +0.488秒 |
最後に
今回はオープンソースソフトウェアで、ローカル環境だけで動作するコードサジェストツールである TabbyML/Tabbyについて、思ったよりも低スペック環境で動作すること、簡単にベースモデルを切り替えることができること、サーバーにホストしローカルマシンから複数人で利用できることを確認しました。
「データ分析者が100人以上いる部署で、全員がTabbyML/Tabbyを利用することにしたら」は、まだ実現できておりませんが、高機能なコードサジェストツールの存在は業務効率を向上する手段のひとつであるため、今後も周辺技術やサービスの調査を継続していこうと思います。
現在よりも高速に、そして高品質のコードを簡単に記述できるようになれば、弊社の掲げる「データ活用の促進を通じて持続可能な未来をつくる」こともより近い未来で実現できるようになるのだろうと思います。
再掲となりますが、広く LLM 関係の最新の情報などについては、弊社の有志で運用している OpenBP Twitter でも最新の情報をご共有させていただいておりますので、もしご興味がありましたらフォローをよろしくお願いいたします!有志のメンバーの励みになります!
参考記事例
- GitHub - TabbyML/tabby: Self-hosted AI coding assistant
- TabbyML
- ローカルPCでセルフホストできてGithub Copilotのように使えるコーディング補助AI「tabby」、Dockerイメージありなので早速使ってみたレビュー - GIGAZINE
- ローカルでGitHub Copilotのようなコード補完ができるというtabbyを試して動かなかった件 - きしだのHatena
- ローカルで動くコーディング補助ツールTabbyを試してみる #コーディング - Qiita
- さくらのクラウドのGPUサーバ(Tesla V100)でTabby(GitHub Copilotの代替)を動かす #AI - Qiita
*1:Hugging Face上でのpytorch_model.binのサイズ