
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
今回は、LLMのビジネス利用に関して注意すべき点の中でも「個人情報や営業秘密等の保護」についてまとめました。

本ブログに掲載されている情報については、可能な限り正確な情報を提供するよう努めていますが、誤情報が混入する場合や、情報の最新性が損なわれる場合もあります。また、情報の正確性を鑑みた際に、予告なしでの情報の変更・削除をすることもありますので、ご了承ください。
また、本ブログの掲載情報をご利用頂く場合には、読者の方のご判断と責任においてご利用頂きますようお願いします。本ブログの情報を利用した結果発生した、何らかのトラブルや損害、損失等につきましては、筆者や関係者は一切の責任を負いかねます事ご了承願います。
こんにちは。アナリティクスサービス部の安藤です。大規模言語モデル(LLM)のビジネス利用に関して注意すべき点について、連載記事の2回目になります。
前回の記事では、LLMをビジネスに活用するにあたり注意すべき点として、サービスの商用利用の可否や制限事項、モデルのライセンス条件といった、サービスの使用許諾条件について紹介しました。
サービスの使用条件に従ってLLMサービスを活用するにあたっても、個人情報や営業秘密、知的財産権など、他者の権利を侵害しないよう、公的なルールに則って適正に運用する必要があります。今後数回に分けて、LLMサービスをビジネスで活用する際の法的リスクと注意しなければならない点について紹介します。
LLMサービスを活用する際の法的リスクの代表的なものとして、個人情報保護や企業機密(営業秘密)の漏えいに関するリスクがあります。今回は、日本国内の法規制との関係で、LLMサービスを利用する場合の個人情報や営業秘密の扱いに関して注意すべき点について解説します。
本記事が想定する主な対象
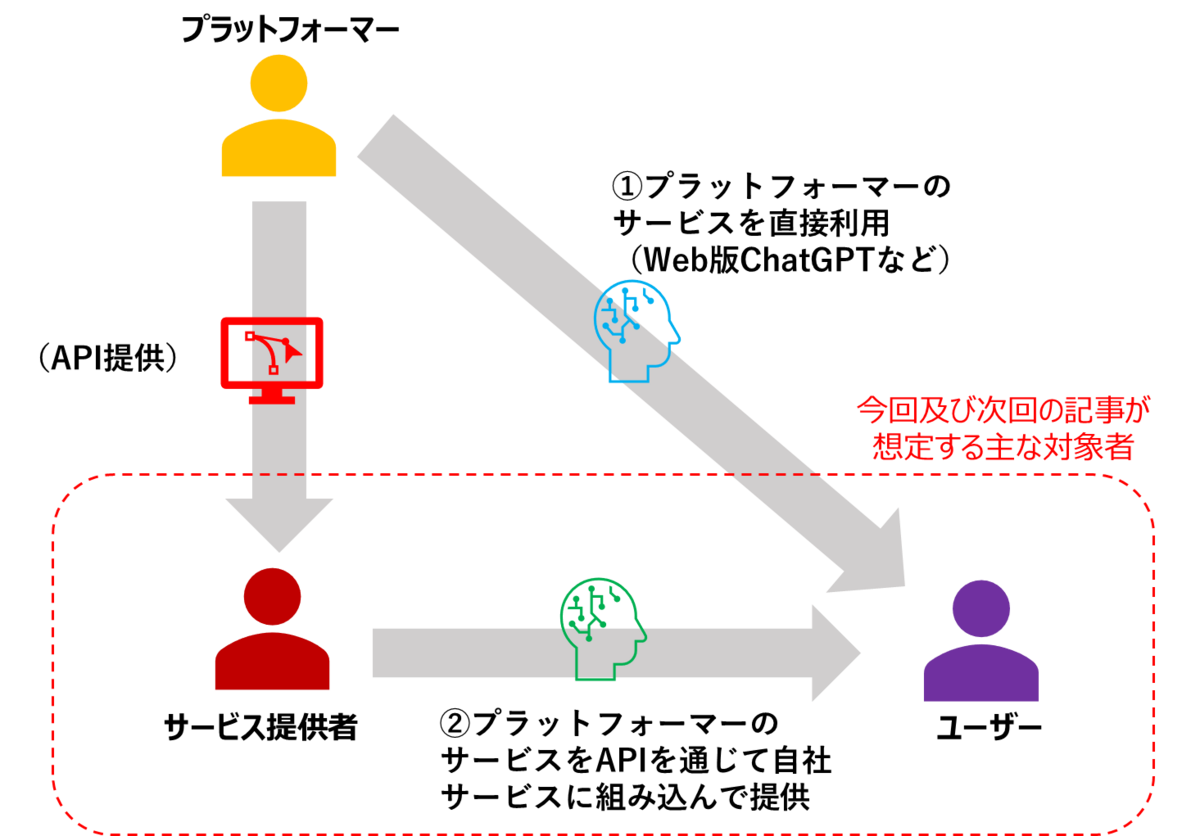
まず、本記事が想定する主な対象者の方について、前回の記事で扱ったLLMサービスのイメージ(下図)を用いて説明します。
前回ご説明したとおり、本連載では自らモデルを開発しサービスを提供する者を「プラットフォーマー」、プラットフォーマーの提供するサービスをAPI等を通じて利用し、自社のサービスを提供する者を「サービス提供者」、プラットフォーマーやサービス提供者が提供するサービスを利用する者を「ユーザー」と呼んでいます。
現状、日本国内においてLLMを用いたサービスを提供・利用する者は、自らモデルを開発するのではなく、海外のプラットフォーマー(OpenAI社やMicrosoft、Google など)が開発したサービスをAPI経由で利用している場合が大半と思われます。
したがって、本記事では主な対象として、「サービス提供者」と「ユーザー」がLLMサービスをビジネス利用する際に気を付けるべき点にフォーカスして解説していきます。
また、以降ではプラットフォーマーが開発したモデルを用いるサービス(図の①又は②)を指して「LLMサービス」と呼びます。
LLMサービスによる情報漏えいリスク
入力したデータがモデルの学習に利用されるサービスは情報漏えいのリスクが大きい。入力したデータがモデルの学習に利用されない場合、リスクは比較的小さいが情報漏えいのリスクはゼロではない
まず、LLMサービスの利用における情報漏えいリスクとは何かについて述べます。LLMサービスによる情報漏えいリスクは、主に①入力した情報がモデルの学習に使われること②入力した情報がプラットフォーマーによって保持されることが原因で発生します。
①入力した個人情報や営業秘密情報がモデルの学習に使われる場合(Web版chatGPTなど)
LLMサービスに入力した情報がプラットフォーマーによってLLMの学習に使用される場合があります。このとき、生成AIの性質上、他のユーザーの質問への回答としてサービスが当該情報を回答してしまうことがあります。
例えば、Web版のChatGPTがこれにあたります。OpenAI社のサービス利用規約(Terms of Use)*1によれば、APIを通じてユーザーが提供した情報(Content)はサービスの向上(モデルの学習含む)には使用されませんが、API以外の方法(Web版ChatGPTを含む)で提供された情報については、サービス向上に利用されることがあるとしています(OpenAI利用規約3.(c))*2。
したがって、こうしたサービスに個人情報や営業秘密を入力することは比較的高い情報漏えいのリスクを伴います。
2023年4月25日、OpenAIはWeb版ChatGPTについて、会話履歴の記録機能をオフにする機能を付加したと発表しました。記録をオフにした場合、会話記録はモデルの学習には利用されません。また、ユーザーの画面にも会話記録が表示されなくなります。
https://openai.com/blog/new-ways-to-manage-your-data-in-chatgpt
もともとWeb版ChatGPTでは、ユーザーがフォームから申請することで会話記録をモデルの学習に利用されないようにする(オプトアウト)ことは可能でした。今回付加された機能はオプトアウトを簡単にできるようにしたものであり、個々のユーザーによるリスク管理はしやすくなったように思えます。他方で、手元で手軽にオンオフを切り替えられることで、意図せず機密情報を入力してしまうケース(記録をオフにしたつもりで機密情報を入力したが実際にはオンになっていた、など)が出てくる可能性もあると思われ、Web版ChatGPTによる情報漏えいリスクが本質的に低下したといえるかはやや疑問が残ります。
また、記録機能をオフにした場合でも、会話記録はOpenAI社によって30日間、不正利用の監視のために保持されます。したがって、これにより生じる情報漏えいのリスクは後述するAPI利用の場合と同様に残ります。
②入力した個人情報がプラットフォーマーのサーバーに保持される場合
①のように入力した情報がモデルの学習に利用される場合でなくとも、入力された情報自体はプラットフォーマーが一定期間保持する場合があります。OpenAI社が提供するAPI版のChatGPTがこれにあたり、APIを通じて送信された情報は、不正利用の監視のためにOpenAI社が30日間保存した後削除することとなっています(OpenAI APIデータ使用方針*3)*4。保持したデータについては、OpenAIの限定された従業員や守秘義務を課されたサードパーティの契約者がアクセスできるとしています。
この場合、データがモデルの学習に利用される場合ほど直接的な漏えいリスクはありませんが、プラットフォーマーの従業員自身が悪意を持って情報を不正に取得・利用するリスクや、第三者がプラットフォーマーのサーバに侵入して情報を取得してしまうリスクは残ります。
LLMサービスのビジネス利用において個人情報や営業秘密等の観点から注意すべき点
LLMサービスのビジネス利用において、個人情報や営業秘密等について、ユーザー・サービス提供者それぞれの立場から注意すべきポイントを最初にまとめておきます。
個人情報の保護(ユーザー・サービス提供者)
- LLMサービスで個人情報を使用する場合、予め個人情報の利用目的を特定して公表しておくことが必要
- LLMサービスに個人データを入力することは第三者提供にあたる可能性が高く、原則として本人の同意が必要。本人同意を不要とするには、プラットフォーマーが法律上必要な措置を講じていることを担保すること(外国企業の場合)や「委託にともなう提供」にあたることの確認が必要
- 入力情報がモデルの学習に利用されるサービスの場合、個人データの漏えいリスクが大きいため、個人データの入力は避けるべき
営業秘密等の保護(主にユーザー)
- 営業秘密や限定提供データを契約の内容等から許されないことを認識しながらLLMサービスに入力して流出させてしまうと契約違反や不正競争防止法違反になる可能性
以下で個人情報(個人情報保護法)と営業秘密等(不正競争防止法)についてそれぞれ詳細に述べます。
個人情報(個人情報保護法)
まず、個人情報の保護に関する法律(以下「個人情報保護法」といいます。)における個人情報とは何かについて述べた上で、LLMサービスを利用する場合に注意すべき点や、個人情報保護法に違反した場合に生ずる責任について述べます。
個人情報とは
- 個人情報は生存する個人に関する全ての情報が該当し、公刊物等によって公にされている情報や暗号化されているものも含まれる
- 容易に検索できるようデータベースとして体系的にまとめられている個人情報を「個人データ」といい、LLMサービスに使用する上では特に注意が必要
個人情報保護法において個人情報とは、生存する「個人に関する情報」と定義されています(個人情報保護法第2条第1項)。「個人に関する情報」とは、個人情報保護法ガイドラインによれば、ある個人の属性を表す全ての情報が該当し、公刊物等によって公にされている情報や暗号化によって秘匿化されているものも含みます。
「個人情報」とは、生存する「個人に関する情報」であって、「当該情報に含まれる氏名、生年月日その他の記述等により特定の個人を識別することができるもの(他の情報と容易に照合することができ、それにより特定の個人を識別することができるものを含む。)」、又は「個人識別符号が含まれるもの」をいう。
「個人に関する情報」とは、氏名、住所、性別、生年月日、顔画像等個人を識別する情報に限られず、ある個人の身体、財産、職種、肩書等の属性に関して、事実、判断、評価を表す全ての情報であり、評価情報、公刊物等によって公にされている情報や、映像、音声による情報も含まれ、暗号化等によって秘匿化されているかどうかを問わない。
個人情報にはいくつかの種類があり、個人情報保護法上それぞれ異なる義務が課されます。特に重要なものとして、容易に検索できるよう、データベースのかたちで体系的に整備されているものを個人データといいます。個人データは第三者提供の制限(後述)がされているため、LLMサービスとの関係では特に重要な個人情報となります。
※「個人情報」と「個人データ」の違いについては、個人情報保護委員会のHPの情報が参考になります。
LLMサービスの利用において個人情報保護法上注意すべき点
- LLMサービスの提供者・利用者ともに、サービスにおいて個人情報を入力することが想定される場合は、予めプライバシーポリシーや利用規約などで個人情報の最終的な利用目的を特定し、公表することが必要
- LLMサービスに個人情報を入力する場合、原則として本人の同意が必要。本人の同意を得ずに個人情報の第三者提供を行うためには、第三者が個人情報保護法上必要な措置を講じる基準を満たしていることの担保(外国企業の場合)や、「委託」にあたることの確認が必要
- 入力したデータがモデルの学習に利用されるサービスの場合は個人データの漏えいのリスクが大きいため、個人データの入力は避けるべき
個人情報の利用目的の特定
個人情報を取り扱う事業者(個人情報取扱事業者)*5は、個人情報を取り扱うにあたって、その利用目的をできる限り特定しなければならないとされています(個人情報保護法第17条)。利用目的の特定にあたっては、利用目的を単に抽象的、一般的に特定するのではなく、個人情報が「最終的にどのような事業の用に供され、どのような目的で個人情報を利用されるのかが、本人にとって一般的かつ合理的に想定できる程度に具体的に特定することが望ましい」とされています。
実際上どの程度具体的に利用目的を特定していればよいかについて、個人情報保護法ガイドラインにおいては以下のような事例が挙げられています。
【具体的に利用目的を特定している事例】
「〇〇事業における商品の発送、関連するアフターサービス、新商品・サービスに関する情報のお知らせのために利用いたします。」
【具体的に利用目的を特定していない事例】
・事業活動に用いるため
・マーケティング活動に用いるため
(「個人情報の保護に関する法律についてのガイドライン(通則編)」P32より )
特定した利用目的の公表
上記の利用目的を特定した上で、個人情報取扱事業者はその特定した目的を公表しておかなければなりません。個人情報取扱事業者は、個人情報を取得する場合は、あらかじめその利用目的を公表するか、公表していない場合は、取得後速やかに本人に利用目的を通知するか、公表しなければならないとされています(個人情報保護法第21条)。
LLMサービスを提供する事業者・利用者ともに、個人情報をLLMサービスで使用することが想定される場合、予めプライバシーポリシーやサービスの利用規約などにおいて、特定した利用目的を公表しておく必要があります。
第三者提供の制限
個人データの第三者提供の制限
既に述べたように、個人情報がデータベースとして整備されている場合は「個人データ」に該当します。個人情報取扱事業者は、原則として、あらかじめ本人の同意を得ないで個人データを国内や外国の第三者に提供してはならないとされています(個人情報保護法第27条、第28条)。
例えばChatGPTの場合、Web版サービスの場合はモデルの学習に利用されます。また、API利用の場合でも、不正利用の監視のために30日間はOpenAI社によってデータが保持されることから、これらが第三者提供にあたると解釈される可能性があります*6。
第三者提供にあたって本人同意が不要な場合
個人データの第三者提供を行う場合は、原則として予め本人の同意が必要になります。第三者提供のための本人同意を得るのは大変な場合がある(特に外国の第三者)ので、以下では、例外的に本人同意を得ずとも第三者提供を行うことができる場合について説明します。
a.「外国にある第三者」への提供の制限
まず、OpenAI社など外国に存在する事業者への個人データの提供を行う場合、「外国にある第三者」への提供に関する制限が適用され、原則として本人同意が必要です(個人情報保護法第28条)。
この制限をクリアするためには、当該事業者が「個人情報取扱事業者が講ずべき措置に相当する措置を継続的に講ずるために必要な体制の基準」を満たしていることが必要です。これは、別途当該事業者と、上記の措置を継続的に講ずることを担保する契約(データ処理契約)を結ぶことで対応することができます。OpenAI社であれば、利用規約上、データ処理契約(Data Processing Addendum:DPA)を締結できる旨が記載されています(利用規約5.a)。
この「個人情報取扱事業者が講ずべき措置」としては、利用目的の特定や安全管理措置、漏えい等の報告等などがありますが、詳細は個人情報保護法ガイドライン(外国にある第三者への提供編)p.10の記載を参照してください。
b.「委託」に伴う提供の例外
上記のような措置により、「外国にある第三者」への提供の制限はクリアできますが、なお「第三者への提供」の制限は残ります(個人情報保護法第27条)。これについては、当該事業者に個人データの扱いを「委託」していると扱うことができれば、本人同意を得ずとも個人データの提供を行うことができます(個人情報保護法第27条第5項第1号)。
「委託」と扱われるためには、提供元である個人情報取扱事業者の「利用目的の達成に必要な範囲内において」個人データの提供がされることが必要です。この「利用目的の達成」に必要な範囲内といえるかについては、委託元の事業者の利用目的の範囲内での利用に限定されているのか、委託先の事業者(例えばOpenAI社)の事業目的での利用も含まれるのかによって変わってくるので、委託先のサービスの利用規約等を確認することが必要です*7。
注意すべき点として、個人情報保護法上、「第三者提供」と「漏えい」は区別されて扱われています。個人情報取扱事業者が自らの意図に基づき第三者に個人データを提供した場合は第三者提供になりますが、意図せず第三者に個人データを提供してしまった場合は「漏えい」にあたります。
例えば、API利用か否かに関わらず、ChatGPTに情報を入力してOpenAI社に個人データを提供する行為は、OpenAI社に情報を提供することが意図されているため、第三者提供になります。一方、Web版ChatGPT(オプトアウトしていない場合)に個人データを入力して結果として他のユーザーにその個人データが流出してしまった場合、他のユーザーへのデータ提供は自らの意図で行ったものではないため、漏えいにあたります。漏えいの該当について、第三者提供に関して本人同意を得ているか否かは関係ありません。
個人データの漏えいが発生した場合、個人情報保護委員会への報告等の義務が生じるとともに、損害賠償など民事上の責任が発生する可能性もあります。
したがって、第三者提供への本人同意の有無に関わらず、情報が流出するリスクが大きいサービスに個人データを入力することは避けた方がよいでしょう。
個人データ以外の個人情報について
なお、個人データにあたらない個人情報の場合、第三者提供の制限の規定は適用されないため、本人同意がなくともLLMサービスに入力することは第三者提供の禁止規定との関係では問題になりません。ただし、既に述べたような個人情報の利用目的の特定や、その利用目的の範囲内での使用といった事項は遵守する必要があります。
個人情報保護法に違反した場合の法的責任
個人情報保護法の規定に違反した場合、刑事・民事上の法的責任が発生する可能性があります。刑事上の責任としては、情報漏えいなど一定の法違反があった場合、個人情報保護委員会は、当該個人情報取扱事業者等に対し、当該違反行為の中止や違反を是正するために必要な措置をとるべき旨を勧告したり、命令することができます。これらの勧告・命令に従わなかった場合、刑事罰として一年以下の懲役又は百万円以下の罰金に処せられます(個人情報保護法第178条)。
民事上の責任については、個人情報保護法においては、個人情報の漏えいにより個人に損害が生じた場合の損害の賠償責任に関する規定は置かれていませんが、民法の債務不履行(民法第415条)や不法行為(民法第709条)に基づく損害賠償責任が生ずる可能性があります。
営業秘密等
「営業秘密」や「限定提供データ」にあたる情報を、契約の内容等から許されないことを認識しながらLLMサービスに入力して流出させてしまった場合、契約違反となる可能性や不正競争防止法違反になる可能性がある
取引先との契約違反の可能性
営業秘密等の場合、LLMサービスの利用にあたって、まずは取引先に対する契約違反(秘密保持義務の違反)が起きる可能性があります。入力する情報が秘密保持契約(NDA)の対象となっている場合、LLMサービスに情報を入力する行為が秘密保持契約における目的外利用の禁止や第三者開示の禁止などに抵触する可能性があります(※)。
特に入力情報がモデルの学習に利用される場合はこれらの条項に抵触するリスクが大きいと思われますが、はっきりした見解はありません。
LLMサービスに取引先から入手した情報を入力する場合は、まず契約上問題が無いかを確認するとともに、必要に応じて相手方の承諾を得る手続を踏むなどして慎重に対応することが必要です。
※目的外利用の禁止や第三者開示の禁止は、経済産業省が示している秘密保持契約の参考例において列挙されているものです。
不正競争防止法違反の可能性
さらに、取引先から営業秘密を開示されたり、提供先を限定してデータの提供を受けた場合にそれらの営業秘密や限定提供データを不正に使用・開示してしまうと、不正競争防止法(以下「不競法」といいます。)上の違反が生じる可能性があります。以下、LLMサービスの利用において違反が生じうる類型として考えられるものについて述べます。
LLMサービスの利用において発生しうる不正競争の類型
a.営業秘密の侵害
営業秘密を保有する事業者からその営業秘密を示された場合に、その営業秘密を不正に使用・開示する行為は不正競争に該当します(不競法第2条第1項第7号)
営業秘密(企業機密)とは、不競法において「秘密として管理されている生産方法、販売方法その他事業活動に有用な技術上又は営業上の情報で合って、公然と知られていないもの」とされています。
技術やノウハウ等の情報が「営業秘密」に該当するのは、以下の3要件を満たす場合です*8。
- 秘密管理性(秘密として管理されていること)
- 有用性(有用な営業上又は技術上の情報であること)
- 非公知性(公然と知られていないこと)
このうち、秘密管理性があると認められる典型的な例としては、他社との間で既に述べた秘密保持契約(NDA)を結ぶ場合が該当します。
b.限定提供データの不正使用
営業秘密と似ていますが、「限定提供データ」を保有する事業者から提供された限定提供データを不正に使用・開示する行為も不正競争に該当します(不競法第二条第一項第十四号)。
限定提供データとは、企業間で複数者に提供・共有されることで、新たな事業の創出につながったり、サービス製品の付加価値を高めるなどその利活用が期待されるデータであり、以下の3要件を満たす場合、限定提供データに該当します。
- 限定提供性(業として特定の者に提供する)
- 相当蓄積性(電磁的方法により相当量蓄積されている)
- 電磁的管理性(電磁的方法により管理されている)
LLMサービスの利用で不正競争が発生する可能性
営業秘密及び限定提供データの不正使用・開示のいずれの場合も「不正の利益を得る目的で、又はその営業秘密保有者に損害を加える目的」があることが要件となっています。この目的を「図利加害目的」といいます。
どのような場合にこの「図利加害目的」があるといえるかですが、限定提供データについて、経済産業省のガイドラインが示している要件によると、以下の2つの要件を満たす場合が該当するようです。
①契約の内容等からデータの使用の態様や第三者開示が禁止されていることが明らかであり、当事者もそれを認識している
②自己や第三者の利益を得る目的をもってデータを使用・開示
実際にこの図利加害目的があると認められるかは個別のケースによると思われますが、例えば秘密保持契約の元で開示されている営業秘密情報やデータについて、提供元の同意なしにLLMサービス(Web版のChatGPTなど)に入力して流出が発生してしまった場合などは、この図利加害目的があると判断される可能性もあるのではないかと思われます。
守秘義務を伴って開示された情報についてその扱いに注意することは当然ですが、少なくとも情報流出リスクの高いサービスへの入力は避けた方がよいでしょう。

不正競争防止法違反により生じる法的責任
上記で述べた不競法第二条第一項第七号・第十四号の規定に違反した場合、民事上の責任として、被害を受けた相手方に侵害行為の差し止め請求権が発生します(不競法第3条第2項)。また、相手方に生じた損害の賠償責任が発生します(不競法第4条)。
加えて、営業秘密の侵害については、刑事罰も設定されています。営業秘密を図利加害目的で使用・開示した場合、十年以下の懲役若しくは二千万円以下の罰金に処せられます(不競法第21条第3号・第4号)。
まとめ
今回はLLMサービスのビジネス利用にあたって注意すべき点として、個人情報や営業秘密等の保護に関して解説しました。LLMサービスの利用におけるこれらの法的な問題については、現在進行形で議論が進んでおり見解が定まっていないものも多いですが、情報漏洩リスクの大きいサービス(Web版ChatGPTなど)をはじめとして、個人情報や営業秘密等の入力については十分注意して取り扱う必要があります。
次回はLLMサービスのビジネス利用に伴う別の主要な論点として、著作権の問題を取り上げます。
最後までお読みいただき、有難うございました。
【関連記事】
参考情報
*1:2023年3月14日改訂版
*2:OpenAI社は入力された情報に個人情報が含まれている場合、当該個人情報をモデルの学習に使用するデータからは削除するとしていますが、確実に削除されるという保証はありません。
*3:2023年3月1日改訂版
*4:Microsoftが提供するAzure OpenAIのChatGPTにおいても、同様に不正利用の監視のため、Microsoft側で情報を30日間保持するとしています。
*5:個人情報データベース等を事業の用に供している者で、国や地方公共団体等を除いた者をいいます。個人情報データベース等を事業の用に供している者であれば、当該個人情報データベース等を構成する個人情報によって識別される特定の個人の数の多寡にかかわらず、個人情報取扱事業者に該当します。
*6:ChatGPTへの入力が第三者提供にあたるか否かについては明確な結論が出ていないようですが、こちらの記事が参考になります。
*7:例えばAPI利用のChatGPTの場合、入力したデータはモデルの学習には利用されないため、OpenAI社の事業目的の利用にはあたらないと考えられますが、Web版のchatGPT(オプトアウトしない場合)には、入力データがモデルの学習に用いられる場合があるため、これはOpenAI社の事業目的での利用にあたり、第三者提供となる可能性があります。
*8:後述する限定提供データの3要件と併せて、これらの要件の詳細については経済産業省「営業秘密の保護・活用について」が参考になります。