
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。

こんにちは。アナリティクスサービス本部の小田です。レコメンドについて考察していく連載の第3回です。
第2回では、協調フィルタリングの実装を行いました。本連載では今後各種手法を実装しながら比較していく予定ですが、その前にレコメンドの評価について確認したいと思います。といっても、レコメンド全体の評価となるとシステムやユーザビリティの評価など広範にわたりますので、今回はアルゴリズムの評価に絞って話を進めます。代表的な評価方法・指標をピックアップして紹介したいと思います。
目次
- 目次
- 1.レコメンドの評価とは
- 2.評価方法
- 3.評価指標
- 4.オンライン評価
- 5.参考文献
1.レコメンドの評価とは
レコメンドの評価とは、与えられたケースにおける良いレコメンドとは何かを決定する枠組みです。これには、何が正解かという明確な答えはありません。状況や目的に応じた様々な評価方法や指標があり、指標も日々新たに考案されアップデートされている感じです。評価指標が多く存在するため、どれを優先させて見るかというのは、最終的にレコメンドに求めるビジネス面のゴールやKPIによって決定されると思います。言うのは簡単ですが、比較するアルゴリズムにはそれぞれ異なる軸での長所・短所があり、最終的にそれをシステム実装などを含めた総合的な条件で検討する訳なので、非常に悩ましいところです。というわけで、今回は一旦難しいことを考えず、オフライン評価での精度評価を中心に紹介します。

2.評価方法
レコメンドの評価方法には、大きく分けてオフライン評価とオンライン評価の2つがあります。
2-1.オフライン評価
オフライン評価は、ユーザの商品に対するレーティング(評価値)や購買など、利用履歴を用いた評価を指します。まず、利用履歴を学習データとテストデータに分割し、学習データのみでレコメンドモデルを構築します。次に構築したモデルをテストデータに適用して、ユーザのレーティングや購買を予測し、どの程度正確に言い当てられるかを評価します。学習時にテストデータを隠しておく(リーブアウトする)ことで、ユーザの未知の行動を予測できるかシミュレートしている感じです。データを分割してモデルを評価するのは一般的な機械学習での評価方法と同じです。分割は、ホールドアウトやK-fold交差検証を用いて行うのが一般的です。

オフライン評価は現行システムにロジックを実装する必要もなく、ユーザの利用履歴さえあればモデルを評価することが可能なため手軽に行えます。実務でも、実サービスで実験する前にオフライン評価でアルゴリズムの有効性を検証した上でサービス実装することが一般的です。またユーザとインタラクションする必要がないため制約も少なく、論文でのモデルの精度評価やコンペティションの精度比較はオフラインがメインとなります。一方で実サービスにてレコメンドを行う場合は、オフラインとは異なる状況となります。例えば、実際におすすめを提示することで購入されるアイテムは、オフラインでは評価ができません。言い換えると、そもそもオフラインの利用履歴に基づいた評価は、私達がおすすめしようとするまいとユーザが購入したものを予測しているので、それを正確に予測できることにどれだけ意味があるかは議論の余地があります。このようにオフライン評価と実サービスでの評価が必ずしも一致しないところも、悩ましい点です。
2-2.オンライン評価
オンライン評価では、実サービスにレコメンドを実装してモデルを評価します。一部のユーザに予測結果に基づいたレコメンド内容を提示し、いい評価を受けるかを確認します。A/Bテストと呼ばれる評価方法はこのオンライン評価です。対象ユーザをランダムに振り分け、一方のユーザには既存のロジックのレコメンドを提示(コントロール)、もう一方は比較したい新しいロジックを提示して(トリートメント)、両群の結果を比較して評価します。実際のサービスでの最終的なレコメンドの評価となりうるので、オンライン評価は重要視されます。ただしユーザに実験内容を提示するため、手間やリスクも大きくオフラインほど手軽ではありません。


3.評価指標
では、どのような指標でレコメンドの性能を評価するのか。実際にはオンラインとオフラインで利用される評価指標は異なります。レコメンドの評価指標が話題になる場合は、概ねオフライン評価のことと考えてもらって差し支えないと思います。オフライン評価では沢山の指標が試されているので話題に上がりやすいですが、オンライン評価指標は利用する種類が少ないためあまり議論の余地がないともいえます(評価計画などは様々あると思いますが)。例えば、よく目にするMovieLensのように、ユーザの5段階のレーティングを予測するような問題などは基本的にはオフライン評価に関する内容です。オンライン評価ではユーザに対して実際におすすめ作品を提示した上で、推薦した作品がクリックされたか、購買されたか、というようなアクション有無の割合(CTR、CVR)を評価することが多いです。
まずは指標を大きく分類してみましょう。

沢山の指標がありますが、レコメンドが情報検索(Information Retrieval、IR)の分野と強く関係する(というか一部)ということもあり、IRの分野で広く利用される指標ばかりです。同時にどれも機械学習でもポピュラーな指標なので、みなさんも馴染みのあるものが多いと思います。試しに上の指標をチートシート風に整理してみましたので、以降の内容と併せて参考にしてください。以降ではこれら指標の意味合いをレコメンドでの利用にフォーカスした形で確認します。

では今回のメインであるオフラインでの評価指標についてまとめていきたいと思います。
3-1.予測の評価指標
レビューや口コミのようにユーザの嗜好が数段回(1から5など)のレーティングで表されるケースでの評価指標を紹介します。ユーザのレーティングをレコメンドシステムがいかに正確に予測できるかを評価します。
MAE(Mean Abusolute Error)
MAEは、予測値と実測値の差の絶対値を算出し、平均したものです。論文やコンペの精度指標でよく見かけるポピュラーな指標となります。直感的で分かりやすい指標ですが、実務ではあまり使うことがないかもしれません。論文やコンペのベースラインと比較する際には必要になるかなという印象です。
算出時は、予測値、実測値の両方の値が存在するユーザ-アイテムのペアのみを対象として次のように計算します。
:レーティングの実測値
:レーティングの予測値
:予測値、実測値の両方の値が存在するユーザ-アイテムペアの数
MAEの計算例
次のような予実のレーティングが存在したケースでのMAEを計算してみます。

RMSE(Root Mean Squared Error)
次はRMSEですが、その前にMSE(Mean Squared Error)の説明をします。MSEは予測値と実測値の差を二乗した値の平均値です。二乗することで偏差のプラス・マイナスを吸収すると同時に、大きな誤差の影響をより大きく、小さな誤差をより小さく反映します。一方で二乗されていことで実測値・予測値とスケールが異なっており、直感的に値の大きさが何を表しているのか分かりにくい部分があるため、MSEはあまり使われません。その代替としてMSEの平方根をとったRMSEが用いられます。
RMSEは先程のMSEの平方根をとることで指標と予測値・実測値とのスケールを合わせたものです。予測の精度指標として最もポピュラーな値の一つとなります。実務でも頻繁に使います。
RMSEの計算例
次のような予実のレーティングが存在したケースでのRMSEを計算してみます。予実の値はMAEと同じです。
予測の評価指標で一言
予測の評価指標は、ひとまずMAEとRMSEを知っていれば問題ないと思います。実際のレコメンドを考えた場合、ユーザに表示されるのはモデルの予測値が高い上位数アイテム(これをTopNと呼ぶ)なので、各ユーザのTopNの商品のみを対象にMAE、RMSEを算出し、評価することがあります。これらはMAE@N、RMSE@Nなどと呼ばれます。その場合おすすめ度の低いアイテムの精度は指標にあまり大きく影響しないことになります。
3-2.分類の評価指標
次にECサイトのように、得られるユーザの利用履歴が購入・カート投入の有無といった2値で表される場合の評価指標を紹介します。評価の大まかなコンセプトはユーザが好む(購買する)と予測したアイテムと、実際にユーザが好んだ(購買した)アイテムを比較することです。レコメンドでは予測した全アイテムに対する精度を評価するのではなく、TopNに対する評価が使われます。
Precision(適合率)
Precisionは、レコメンドリストにあるアイテムのうちユーザが嗜好したアイテム(適合アイテム)の割合です。ここでの「レコメンドリストにあるアイテム数」は、TopNのに該当します。つまりTopNアイテムのうち、何割がユーザにクリック・購入されたかということです。レコメンドの評価ではTopNに対するPrecisionということで、明示的にPrecision@Nと呼ばれることがあります。
:考慮する上位ランキングの数
:ユーザが嗜好したアイテム集合
:
のレコメンドリスト
もしくは、一般的な機械学習の分類問題と同じように次のような混同行列を用いて表すこともできます。

:ユーザが好きなものをTopNでレコメンドできた数
:ユーザが好きでないものを間違ってレコメンドした数
Precisionの計算例
次の例でPrecisionを計算してみましょう。

おすすめするアイテム数が4(TopNのN=4)で、そのうちユーザが好きなアイテム(適合アイテム)が3つあるのでPrecisionは次のようになります。
Recall(再現率)
Recallは、ユーザが実際に嗜好したアイテムのうち、レコメンドリストでカバーできたかの割合です。
Precisionと並んで最もよく利用される指標の一つとなります。
混同行列で表現すると次のようになります。

:ユーザが好きなものを間違ってレコメンドしなかった数
Recallの計算例
次の例でRecallを計算してみましょう。

ユーザが好むアイテム数が全体に5つあり、そのうち予測できたアイテム(適合アイテム)が3つあるのでRecallは次のようになります。
F値
PrecisionとRecallの両方を勘案して、一つの指標として他モデルと比較したい場合に、F値(F1-measure)を使うことがあります。F値はいわゆるPrecisionとRecallの平均値です。ただし算術平均ではなく調和平均を使って算出する必要があります。なお統計の分野ではF値と呼ばれる指標が複数ありますので、区別するためにあえてF1と呼ぶ方もいらっしゃいます。
F値の計算例
次の例でF値を計算してみましょう。

先程求めたようにPrecisionが3/5で、Recallが3/4なのでF値は次のようになります。
PrecisionとRecallの関係
PrecisionとRecallは最終的にレコメンドする際の閾値(上位何位までのアイテムをレコメンドするかなど)によって変動する値です。閾値を下げてレコメンドするアイテム数を増加させるとRecallは増加しますが、Precisionは低下していきますので、この2つはトレードオフの関係にあります。
閾値による変動も考慮して、より広くレコメンド精度を評価したい場合は、後ほど紹介するPR曲線やROC曲線を確認し、そのAUCを指標として用います。これらの指標はランキングの正しさを評価する指標の一部に分類されます。

分類の評価指標で一言
Precision、Recall、F値はレコメンドに限らず、機械学習においても最もポピュラーな値の一つなので頭に入れておく必要があります。特にPrecisionとRecallはレコメンドのオフライン評価では必ず目にするので計算の仕方や関係性も含め覚えておくとベターです。
3-3.ランキングの評価指標
レコメンドで最終的にユーザに提示されるのはおすすめ度の高い上位数アイテム(TopN)なので、ユーザの嗜好が高い順にアイテムを正しく並べ変えるタスクと捉えることができます。ここではランキングの正しさを評価するためのいくつかのプロット・指標を紹介します。
PR曲線(Precision-Recall Curve)とAUC
Recallを横軸に、Precisionを縦軸にとり、Top1、Top2,...というように閾値であるTopNの
を変動させると、RecallとPrecisionが複数点プロットできます。この点同士を直線で結んだものがPR曲線です。RecallとPrecisionともに大きい状態が理想的なレコメンドなので、精度が良いほど右上のほうに曲線は膨らんでいきます。さらに曲線と縦軸・横軸で囲まれる部分の面積がPR曲線の AUC(Area Under Curve) です。AUCは、0から1までの値をとり、1が最も精度の良いレコメンドとなります。PR曲線は次に紹介するROC曲線からとって変わって、ここ数年よく見かけるプロットの一つです。
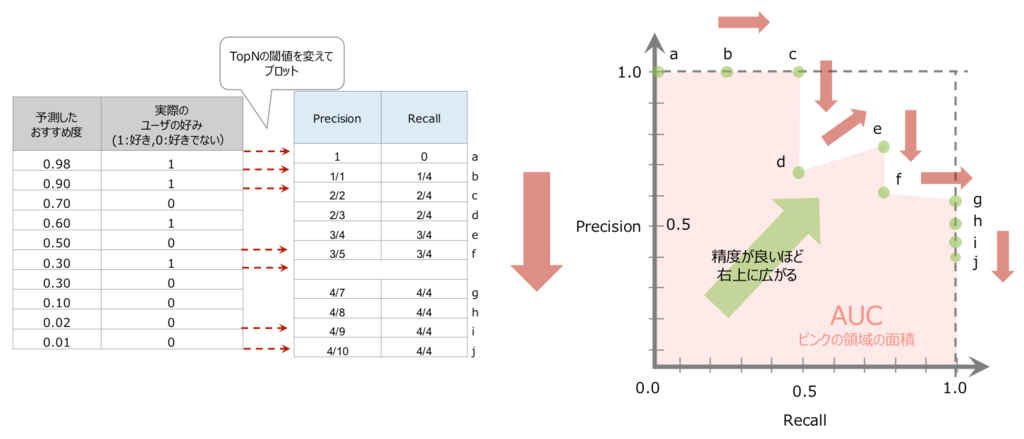
※上図の例では、プロットした点がすくないためカクカクしていますが、実データではプロット点が多いため滑らかな曲線となります。
ROC曲線(Reciver Operator Charastic Curve)とAUC
ROC曲線もPR曲線と同様に精度評価によく使われるプロットです。ROC曲線は縦軸と横軸に次の値を取ったグラフで、両者の関係性を表しています。

PR曲線と同様に、閾値を変えてTPRとFPRをプロットし、プロットした点同士を線で結ぶと曲線が描かれます。一般に「レコメンドするアイテム数(
)を増やすほど、ユーザが嗜好するアイテムをカバーしやすくなるが(縦軸が増加)、その分ユーザが好きでない商品も表示されやすくなる(横軸の増加)」という関係がなりたつので縦軸TPRが増加するにつれて、横軸FPRも増加します。なるべく縦軸を大きな値に保ちながら横軸は小さくしたいので、精度の良いモデルは左上に山が広がっています。ランダムにレコメンドした場合のROC曲線は原点
から
を結ぶ直線になりますので、ランダムからどれだけ左上に広がっているかを確認します。この山の大きさを数値で表したものがROC曲線のAUC(Area Under Curve)で、曲線と縦軸・横軸で囲まれた部分の面積を用いて山の大きさを評価しています。AUCは0から1までの値をとり,完全な分類が可能なときは1、ランダムな分類では0.5になります。

※上図の例では、プロットした点がすくないためカクカクしていますが、実データではプロット点が多いため滑らかな曲線となります。
PR曲線とROC曲線の違い
さてPR曲線とROC曲線は何が違うのでしょう。両曲線とも一方の軸にRecallを採用していますので、違いは他方の軸にPrecisionとFPRのどちらを使うかです。PrecisionとFPRの大きな違いは分母に予測値を使っているか実測値を使っているかです*1。Precisionの分母は嗜好すると予測した数で、この値はNの値(すなわち閾値)のとりかたで変動します。一方、FPRは嗜好しなかった数の実測値を分母に用いるので、Nの値にかかわらず常に一定です。Precisionでは、ランキング上位では分母の値が小さく、下位では分母が大きくなるため、ランキングの上位の誤差の影響が相対的に大きく反映されることになります。特に正例の数に対して負例の数が多いケースでは(アイテムに対して、購入者がほとんどいない場合など)、負例全体を分母に使っているFPRでは精度の差異が出にくくなるため、PR曲線を使うことが多いと思います。ただしPR曲線はランキング上位の精度に敏感なため、その分不安定という側面もあります。レコメンドのようなクリック・購買されないアイテム(負例)の比率が大きく、ランキング上位を重視するものはROC曲線よりPR曲線が向いていると言われており、最近はこのPR曲線がよく用いられます。なお、PR曲線のAUCは、後ほど紹介するMAPを表します。


MRR(Mean Reciprocal Rank)
MRRはレコメンドリストを上位から見て、最初の適合アイテムの順位をそのまま計算に利用したシンプルな指標で、以下の手順で算出されます。
- 全対象ユーザに対してレコメンドリストを作成する
- ユーザが嗜好する適合アイテムが上位何番目で現れたか調べる
- この順位の逆数をとる(リストに正解が含まれない場合は0となる)
- 全ユーザで平均をとる
MRRは0から1の値をとり、すべてのユーザに対してレコメンドリストの第1番目のアイテムが適合アイテムならば1になります。正解が一つもリストに含まれない場合は0になります。特徴として、ランキング上位での順位の差異は指標に大きく影響しますが、ランキング下位での順位の差異はあまり影響しません。例えば1位に最初の適合アイテムがあった場合と2位にあった場合の指標の差は大きいですが、100位と101位での差は小さくなります。
は各対象ユーザ。
は全対象ユーザ
はユーザ
MRRの計算例
次の例では、ユーザaに最初の適合アイテムが出現する順位は2位、ユーザbは4位、ユーザcは1位。この順位の逆数を足し合わせて、人数の3で割れば平均値であるがでます。

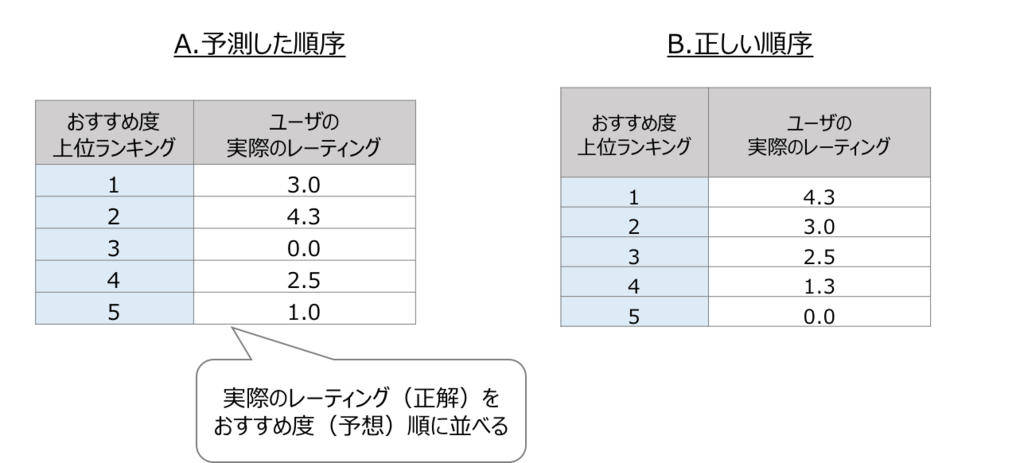
MAP(Mean Average Precision)
MAPの説明の前に、AP(Average Precision)の説明をします。先程Precisionは閾値によって変化すると書きましたが、APは適合アイテムが出現した時点をそれぞれ閾値として、閾値ごとのPrecisionを算出し、Precisionの平均をとったものです。なおAPはPR曲線のAUCと同じ値になります。先述したようなPR曲線の特徴より、上位のランキングの誤差の影響がより大きく影響された指標となります。
APの計算例
次の例は、ユーザaのAPの計算例です。まず適合アイテムが出現するTop2、Top5、Top6でのPrecisionを求め、適合アイテムの数3で割って平均をとります。MAPはこの値をさらに対象ユーザで平均したものとなります。

nDCG(normalized Discounted Cumulative Gain)
nDCGもランキングの評価指標の一つですが、スコア(おすすめ度、確率)をそのまま指標算出に用います。このnDCGはDCGという指標を正規化したものなのですが、DCGは一言でいうとアイテムをおすすめ順に並べた際の実際のスコアの合計値です。ただし、ランキング下位に行くほどスコアがディスカウントされていきます。したがって下位のランキングに位置付けられたスコアが小さくなるようになっていて、このことが実際にユーザが嗜好したアイテムを下位に並べてしまったときのペナルティになります。下式の分母がディスカウント部分です。ここでは順位の対数を用いてますが、底の異なる対数やその他のディスカウント方法も使われるようです。DCGは値が大きいほうが良いランキングになります。nDCGは、DCGを考えられる最大のDCGで正規化した値で、0から1の間の値をとります。
nDCGの計算例
次の例は、nDCGの計算例です。
ランキングの評価指標で一言
ランキングの評価指標としては、まずROC曲線とPR曲線がポピュラーなので両者とも内容を理解しつつ、レコメンドの評価ではPR曲線をよく利用することを覚えておくと良いと思います。その他、MAPとnDCGが有名かなという印象です。今回紹介していないランキング評価の指標として、スピアマン順位相関(Spearman's rho)、ランクスコア(Rank Score)、リフトインデックス(Lift Index)などありますが、どれも今回紹介した指標と近い内容の評価で難しくはありませんので、興味のある方は調べてみてください。
3-4.カバレッジ(Coverage)
ここまでいくつかの評価指標を見てきましたが、レコメンドを評価する際に精度だけを見ていれば良いのかという問題があります。よく挙げられる例として、人気ランキング上位の商品ばかりがレコメンドされたり、牛乳と卵がよく買われるスーパーマーケットで牛乳と卵をおすすめされるケースがあります。これら人気の高い商品や、一般によく購入する傾向にある商品をレコメンドしていれば、精度指標はある程度高くなることは間違いないですが、購入されることが自明な商品ばかりをレコメンドしていてもあまりレコメンドの有り難みはなさそうです。レコメンドされるアイテムには幅の広さや目新しさのようなものが求められることがあります。ここではレコメンドの幅広さを測る指標としてカバレッジを紹介します。
カタログカバレッジ(Catalogue Coverage)
カタログカバレッジは、利用可能な全アイテムのうち、1回のレコメンドでどのくらい多くのアイテムをレコメンドできたか示します。レコメンドのアイテム方向への広がりやカバー率を表し、この値が大きいほど幅広いアイテムをレコメンドできたことになります。
は、1回のレコメンドでユーザにおすすめされたアイテム集合
は、利用可能な全アイテム集合
いくら幅広くてもユーザが嗜好しないアイテムをおすすめしても仕方ないということで、適合アイテムのみに対象を絞った 適合カタログカバレッジ(Weighted Catalogue Coverage) を用いることもあるようです。
は、適合アイテム集合
ユーザカバレッジ(Prediction Coverage)
ユーザカバレッジは、ユーザに対するカバー率です。全対象ユーザのうち、1回のレコメンドでどのくらい多くのユーザに対してレコメンドできたか示します。レコメンドのユーザ方向への広がりを表し、この値が大きいほど幅広いユーザに対してレコメンドできたことになります。適合ユーザのみに絞ることがあるのはカタログカバレッジと同様です。
は、1回のレコメンドでユーザにおすすめされたユーザ集合
は、利用可能な全ユーザ集合
カバレッジで一言
カバレッジは、レコメンドの幅広さの一つとして利用されます。またアルゴリズムがどの程度のアイテムおよびユーザに対してレコメンドを生成できるかという、アルゴリズムのコールドスタートへの対応も評価できます。一般にレコメンドの利用履歴はスパースなものが多いため、協調フィルタリングなどコールドスタートへの対応が難しいアルゴリズムでは、レコメンドリストを作成できないユーザやアイテムが多く存在する可能性がありますので広がりにも注意して評価する必要があります。
3-5.その他の指標
レコメンドの目的の一つが「ユーザを長期間魅了し続けること(LTVを上げる)」だった場合、利用履歴にあるユーザの嗜好と近いからと言って、あまり同じような商品ばかりをレコメンドしていてもユーザは飽きてしまうかもしれません。ここでアイテムに対する意外性や出会いのようなものが必要、という考えが出てきます。ここまで紹介したスタンダードな評価指標以外に最近は、目新しさ(Novelty)やセレンディピティ(Serendipity)、多様性(Diversity)という、意外性や驚きみたいなものを重要視する動きがあります。これらを定量化してレコメンドに活かしていこうという試みも進んでいますので、気になる方は調べてみてください。
4.オンライン評価
クリック率、コンバージョン率
オフライン評価は、実施の手軽さや条件のシンプルさから多く研究されていますが、一方でオフライン評価で良い精度のアルゴリズムが、必ずしも実サービスでいい精度を出せるかは分かりません。その点、オンライン評価では、サービスでのアルゴリズムの有効性を最もわかりやすく確認できます。オンライン評価の指標は、レコメンドしたアイテムが実際にどの程度クリックされたか、購入されたかなどいわゆるCTR(Click-Through Rate)やCVR(Conversion Rate)という値で主に計測されます。今回はとりあげませんが、オンライン評価についての詳しい内容は別の機会にご紹介できたらと思います。
以上でレコメンドの評価についてのまとめは、終わりです。次回以降は協調フィルタリングの中でも近傍ベースだけでなく、モデルベースのアプローチや深層学習モデルを実装しながら、それらの精度などを比較してみたいと思います。それではごきげんよう。
●「レコメンドつれづれ」の連載記事
5.参考文献
- Dietmar Jannach, Markus Zanker, Alexander Felfernig(著), 田中 克己, 角谷 和俊 (監訳)(2012)『情報推薦システム入門 -理論と実践-』共立出版
- A PRACTICAL GUIDE TO BUILDING RECOMMENDER SYSTEMS Evaluation Metrics – Part1
- Setting Goals and Choosing Metrics for Recommender System Evaluations
- Dimensions and Metrics for Evaluating Recommendation Systems
- recommenderlab: A Framework for Developing and Testing Recommendation Algorithms
*1:これは予測値が所与での条件付き確率か、実測値が所与の条件付き確率かの違いとも言えます。