

Professional Data Engineer に合格するともらえるバックパック
こんにちは、アナリティクスサービス本部の家入です。
弊社のアナリティクスサービス本部では、ビッグデータを活用したデータ分析や機械学習システムをクライアント企業に提供しており、業務の中でクラウドサービスをデータストア、あるいは分析や開発の基盤として利用することがあります。
こうした仕事上の必要性、またブレインパッドとしても Google Cloud Next に出展したり、社内に Google Cloud の有資格者が在籍したりすること、クラウド周りの知識を固めたいという個人的希望から、私も Professional Data Engineer の試験に挑戦してみることにしました。
今回は、この Professional Data Engineer に合格するまでの勉強法や、取得してみての感想についてお話ししたいと思います。
事前リサーチをしてみての印象
まずはじめに、 Professional Data Engineer の試験について書いた記事に目を通しました。どちらかといえば、データサイエンティストや機械学習エンジニア寄りの人ではなく、SIerやインフラ周りの人が多く受験している印象で、機械学習まわりの勉強が大変という声を聞きました。
また、社内で資格を持っている方に話を聞くと、IPAのスペシャリストレベルの情報処理技術者試験よりは簡単という話や、要件に合った適切なストレージを選択できること、セキュリティに関して調べておくといい、と伺いました(実際、データ基盤の組み合わせや、データアクセスについては問題が多く出ました)。
こういったことから、機械学習についてよりも、データ分析基盤の特性を理解することが重要そうに感じました。
オンライン講座「Coursera」を利用した勉強法
社内外の人が受けていることもあり、Courseraの Data Enginner on Google Cloud Platform のオンライン講義を受けることにしました。
先輩社員の方が受けた際は、4万円くらいかかっていたそうですが、私が受けた際は月額5,412円で、のんびり2ヶ月受けたので延べで1万円ちょっとでした。最初1週間は無料で受講できるので、本気で頑張れば、1週間でいけるかもしれませんね(弊社には実質4日で取得した猛者がいます...)。
なお、ブレインパッドには「SKILL UP-AID(スキルアップエイド)」といって、外部講義の受講や資格取得を支援する制度がありますので、個人費用はかかっていません。素敵です。

Courseraでは、ストレージや分析基盤について歴史的経緯なども交えつつ広く取り扱い、ハンズオンのトレーニングも行います。 Google Cloud にはデータ周りだけでも、Cloud Storage, Datastore, Dataproc, Dataflow, Datalab, Data Studio, Cloud SQL, Bigtable, BigQuery, Spanner, Pub/Sub, ML Engineといった幅広いサービスがあり、これらの違いや特性を把握する必要があります。いくつか特徴を書き出すと、
- Cloud Storage: 使う頻度に応じたオブジェクトストレージを選択可能。BigQueryやDataproc用のストレージとしても利用可能。
- Datastore: フルマネージドNoSQLストレージ。クエリやトランザクションにも対応。
- Dataproc: マネージドのSpark & Hadoop。要クラスター設定。
- Bigtable: 非構造化データに対応したキーバリューストア。高スループットだがクエリには非対応。
- BigQuery: フルマネージドデータウェアハウス。Cloud StorageやBigtable、スプレッドシートのデータとも連携。
といったようになっています。こちらではポイントだけ抽出しましたが、勉強の際は自分がわかりやすいように分析基盤をまとめると良いかと思います。
また、公式のドキュメントやネット上の情報もありますので、Courseraなしでも勉強は可能です。公式のドキュメントからの引用ですが、次の図がストレージの選び方として、分かりやすいと思います。
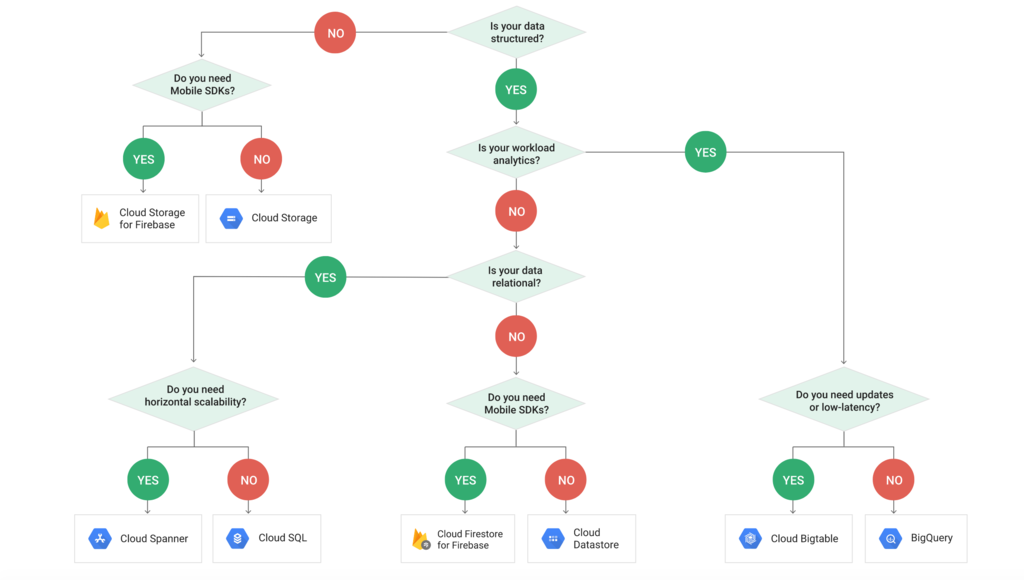
(出典: ストレージ オプションの選択 | Google Cloud)
また、データサイエンティストの方であれば、Courseraの機械学習のパートで、Vision APIなどのユースケースに関するもの以外は飛ばしても構わないかと思います。
模擬試験を受けてみて
次に、模擬試験を受けてみました。回答のペースをつかむのに少し戸惑いましたが、試験の内容については難しいものもあれば、簡単なものもあるという印象で、手応えとして6割くらい正解している感じでした。
この時の印象としては、サービスの特性や組み合わせ、アクセス権限周りなど、結構細かいところを聞いてくるなと感じました。
ありがたいことに模擬試験では終了後に、それぞれの問題に関して、公式ドキュメントを参照してくれます。それを踏まえて、公式ドキュメントを1日1つほど読むようにしました。
アクセス権では例えばこちら
Overview | Cloud Identity and Access Management Documentation | Google Cloud
Creating and Using Datasets | BigQuery | Google Cloud
Bigtableのスキーマ設計についてはこちら
Schema Design for Time Series Data | Cloud Bigtable Documentation | Google Cloud
また、本試験ではクラウド導入のケーススタディとして、FlowlogisticとMJTelcoという架空の2つの会社に関する問題が一部出されます。そのため、これらの仕様を読んで、どのサービスを利用できるかを技術要件にあわせてメモしておきました。
まず、Flowlogisticは物流会社であり、配送状況のリアルタイム分析とHadoop/Sparkサーバーの移行が主なテーマとなっています。
一方、MJTelcoはネットワークインフラのプロバイダーで、自社独自のデータに対するセキュリティ、分析基盤のスケーラビリティ、柔軟な機械学習システムの運用などが大きなテーマとなっています。みなさんは、これらについてどうアプローチするべきだと考えるでしょうか?
Google Data Engineer Certification Case Study - Flowlogistic | Google Cloud Certifications | Google Cloud
Google Data Engineer Certification Case Study - MJTelco | Google Cloud Certifications | Google Cloud
いよいよ本試験
本試験はやはり模擬試験より若干難しめでした。ただ、勉強したことを踏まえて、 Google Cloud を使うならこのアーキテクチャ・サービスが良さそう、データセットの権限管理はこうするのが良さそう、と考えていけば落ち着いて解くことができると思います。
予想通りストレージと分析基盤の組み合わせに関する問題が多かった一方で、データの移行に関する問題や、Stackdriverを使ったモニタリングとレポーティングなど、事前の勉強ではあまりカバーしていない領域も出題されましたが、なんとか回答することができました。
Introduction to BigQuery Data Transfer Service | BigQuery | Google Cloud
Stackdriver - Hybrid Monitoring | Stackdriver | Google Cloud
試験時間は2時間ありましたが、回答自体は1時間くらいで終わり、残りの時間で見直しをしました。
最後に回答を提出した時に、「暫定 合格」の文字を見た瞬間はとても嬉しかったです。
ふりかえり
今回、 Professional Data Engineer の勉強をすることで、ストレージや分析基盤の特徴と連携パターンを理解することができました。例えばBigtable、BigQuery、Dataproc、Spannerなどはどれも分析基盤ですが、設計仕様や処理能力で少しずつ違いがあり、ビジネス要件に合わせてこれらの是非を検討することができるようになりました。
また、ここではあまり触れていませんが、アドホックな分析だけでなく、リアルタイムなデータ処理をするうえでは、Pub/SubというメッセージサービスやDataflowというプロセッシングサービスについても考慮する必要があります。
Professional Data Engineer を通して得られた知識を、今後の業務に生かして行きたいと考えています。本記事がみなさまの参考になると幸いです。

最後に当社では、ビジネスにつなげる機械学習など、最先端の取り組みを積極的に実施しています。実際のビジネスで、最先端の技術を活用してみたいという方は、ぜひエントリーください!
www.brainpad.co.jp