
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
今回よりAzureのさまざまな機能を紹介する新連載がスタート!初回はAzureチームに所属する新卒2年目社員が、「Azure SQL Data Warehouse」の後継サービスにあたる、エンタープライズ データ ウェアハウスとビッグデータ分析がひとつになった分析サービス「Azure Synapse Analytics」についてご紹介します!

こんにちは。エンジニアリング推進部の服部です。
新卒入社してから約1年ほど経つなかで、商業施設運営企業様向けのデータ分析基盤構築などに携わってきました。その際、Azure Synapse Analyticsの専用SQLプール(以降Synapse)上で、数億~数10億レコードの巨大テーブル同士を結合してデータマートを構築する機会があり、クエリ実行に数時間かかるという問題に直面しました。そして、Synapseでは、テーブルの分散スタイル(ラウンドロビン分散・ハッシュ分散・レプリケート分散)のチューニングが必須であることを学びました。
そこで今回はクロスファンクショナルチーム(Azure)の活動の一環として、「Synapseにおける分散スタイルとクエリパフォーマンスの関係」について紹介します!クロスファンクショナルチームについてはこちらをご覧ください。
Synapseに投入されるデータは、物理的に隔たれた60個のディストリビューションに分散して配置されています。ディストリビューション間のデータ移動の増加は、クエリパフォーマンスの低下を引き起こすため、効率的なデータ配置を行う必要があります。
データ配置の方式は、ラウンドロビン分散(デフォルト設定)・ハッシュ分散・レプリケート分散の3種類です。ハッシュ分散は、テーブル定義時に指定したキーの値が同じレコードを、同じディストリビューションに格納するという特長を持ちます。
そのため、データマート作成などの2つの巨大テーブルを結合する処理では、両テーブルの分散スタイルを同一キーのハッシュ分散にすることで、ディストリビューション間のデータ移動が少なくなり、パフォーマンス向上が見込めます。これが本当かを確認することが本記事の目的です。
参考:Azure Synapse Analytics で専用 SQL プールを使用して分散テーブルを設計するためのガイダンス
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute
参考:Synapse SQLプールのデータの分散配置
https://qiita.com/masahiro-yamaguchi/items/4db312c5d37a7f48bfcd
※ 本ブログ執筆にあたり「Microsoft® Most Valuable Professional for Data Platform」を受賞されている「Masahiro Yamaguchi」さんのQiita記事も参考にさせていただきました。ありがとうございました。
検証用に以下のような最小環境を準備しました。クエリ実行のため、VM内にはSQL Server Management Studio(SSMS)をインストールし、Synapse(性能は100DWUとする)と接続させておきます。ストレージアカウントは、テストデータをSynapseに載せるための一時保管場所として使っています。

以下のような仕様の2テーブルをテストテーブルとして準備しました。値に意味はなくランダム値です。結合キーであるorder_idカラムの値は、13桁の英数字混合とし、値のパターンを2テーブル間で同じにしておきます。

MS公式ドキュメントでは、ハッシュ分散を採用する基準の一つとして、ディスク上のテーブルサイズが2GBを超えていることが挙げられています。そこで、テーブルサイズが2GB以上の場合とそうでない場合とで、ハッシュ分散の効果がどの程度現れるかを調べてみました。
2億件のデータを格納したorderテーブル(約15GB)とorder_detailテーブル(8GB弱)とをorder_idでINNER JOINし、両テーブルの全カラム情報を持つorder_allテーブル(分散スタイルは元テーブルと同一)をCTAS句で作成するまでにかかった時間を、参考値として以下表に示します。値は5回平均値となります。ハッシュ分散が明らかに高速であることが分かります。

件数が少ない場合でも、ハッシュ分散の方が高速になるようです。基本的に、分散スタイルはハッシュ分散としておくのが良さそうです。

表.クエリ実行時間の比較(10万レコードの場合)
ちなみに、動的管理ビュー(DMV)を利用することで、クエリの進捗を処理ステップごとに細かく確認することができます。
SELECT * FROM sys.dm_pdw_exec_sessions;
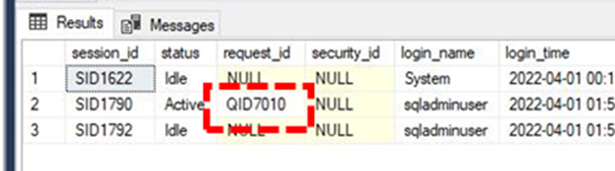
で実行クエリのrequest_id(QID####)を特定したうえで、
SELECT * FROM sys.dm_pdw_request_steps
WHERE request_id = 'QID####'
ORDER BY step_index;
を発行することで、各ステップの実行時間(total_elapsed_time)等を以下表のようにチェックできます。ラウンドロビン分散の場合、結合テーブルデータを生成する処理(step_index=13)と、結合テーブルに挿入する処理(step_index=16)とが異なるステップに分けられています。注目すべき点は、RoundRobinMoveOperationの実行(step_index=13)に時間がかかっていることです。ディストリビューション間のデータ移動(DMS)が、処理の遅い主要因であるとわかります。

表. ラウンドロビン分散使用時のクエリプラン
ハッシュ分散の場合、ディストリビューション間のデータ移動を起こさずに処理が一括実行されていることが確認できます。

参考:DMV を使用して Azure Synapse Analytics の専用 SQL プールのワークロードを監視する
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-manage-monitor
テーブル同士を結合する処理では、テーブルサイズによらずハッシュ分散がラウンドロビン分散よりも高速であることが確認できました。一方で次のような場合は、ハッシュ分散の恩恵を受けにくいことに注意が必要です。
- ハッシュキーのカーディナリティが低い(ディストリビューションごとのデータ量に偏りが生じ、データ量の多いディストリービューションの処理が遅くなりうる)
- 結合するテーブル間でハッシュキーが異なる
結論としては、
巨大テーブルを扱う場合、まずハッシュ分散が使えないかを検討し、難しい場合にラウンドロビン分散を使うのが良いかと思います。テーブルサイズが小さい(2GB未満が目安)場合でも、データ操作を頻繁に行うテーブルであれば同様です。
今回は調査対象外としましたが、テーブルサイズが小さくかつ、データ操作が頻繁に生じないテーブルの場合は、レプリケート分散が適しているかもしれません。レプリケート分散は、個々のディストリビューションに全データを含み、そもそもディストリビューション間のデータ移動を起こさないためです。
なお、パフォーマンス向上のための他の手段として、パーティションを使用することも挙げられます。Synapseでパーティションを使用する場合、データが既に60個のディストリビューションに分散されていることを考慮しつつ、パーティションを切る必要があるようです。今後は、テーブルサイズと最適なパーティション数の関係についても検証してみたいと考えています。
参考:専用 SQL プールでのテーブルのパーティション分割
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-partition?context=/azure/synapse-analytics/context/context#partition-sizing
ブレインパッドでは新卒採用・中途採用共にまだまだ仲間を募集しています。
ご興味のある方は、是非採用サイトをご覧ください!
www.brainpad.co.jp