
本記事は、当社オウンドメディア「Doors」に移転しました。
約5秒後に自動的にリダイレクトします。
皆さん、こんにちは。マーケティングプラットフォーム本部で広告系製品の開発を担当している田頭です。
前回の理論編ブログでは、大量のログから高速にユニークユーザー(以下、UU)数を推定するための背景やアルゴリズム、およびその実装部分について、「理論編」として解説させていただきました。
今回は「実践編」として、実際に当社内で行ったapprox_distinct関数のパフォーマンス検証について、以下の内容を皆さんにご紹介したいと思います。
- 検証環境
- 検証データ
- 検証項目
- 検証結果
- 小規模検証結果
- 中規模検証結果
- 大規模検証結果
- 検証結果考察
- まとめ
1. 検証環境
今回の検証は、以下の環境で実施しました。
- クラスタ環境
- Amazon Elastic MapReduce (EMR) を利用(EMR 4.6.0)
- master
- r3.xlarge 1台
- core
- r3.xlarge 3台
- master
- sandboxを利用して以下をインストール
- Presto 0.143
- Hive 1.0.0
- Prestoの設定は上記環境で起動した場合のデフォルト値を利用
- xmx
- 25735444038
- query.max-memory
- 30GB
- query.max-memory-per-node
- 12867722019B
- xmx
- Amazon Elastic MapReduce (EMR) を利用(EMR 4.6.0)
- データソース
- Hiveテーブル
- Amazon Simple Storage Service (S3) に実データ格納
- hive metastoreはremote mode(MySQL)
- Hiveテーブル
2. 検証データ
検証に利用したデータは、以下の通りです。
- データフォーマット
- ORC
- 50万行ごとに分割
- カラム数は24
- パーティション
- 日付(年月日)
- ORC
- データサイズ
- 1行あたりログサイズ
- 約120~約280B
- 1日あたりログサイズ
- UU数が小規模(1日あたり数百)な場合
- 約177KB
- UU数が中規模(1日あたり数万)な場合
- 約222MB
- UU数が大規模(1日あたり十数万~百数十万)な場合
- 約200MB~約2.6GB
- UU数が小規模(1日あたり数百)な場合
- 1行あたりログサイズ
3. 検証項目
以下の内容で、厳密に集計(COUNT(DISTINCT x))した場合と、推定(approx_distinct(x))した場合の結果を取得しました。
- UU数が小規模な場合
- 1日分~180日分まで1日分ずつログを増加させる
- 例)
- 1回目:4月1日分のログで集計
- 2回目:4月1日分~4月2日分のログで集計
- ・・・
- 1日分~180日分まで1日分ずつログを増加させる
- UU数が中規模な場合
- 1日分~180日分まで1日分ずつログを増加させる
- UU数が大規模な場合
- 1日分~375日分まで1日分ずつログを増加させる
4. 検証結果
このブログに掲載している検証結果の図は、全て横軸を真のUU数(厳密に集計したUU数)としています。
4-1. 小規模検証結果
4-1-1. UU数の真値と推定値

凡例の意味は以下の通りです。
- strict_uu
- COUNT(DISTINCT x)の結果
- 真の値と等しい
- approx_uu
- approx_distinct(x)の結果
両者が重なっているほど、誤差が小さいことを意味しています。
UU数が小さい場合(グラフ左側)でも、ほぼ重なっています。
4-1-2. 計算時間

凡例の意味は、以下の通りです。
- strict_time
- COUNT(DISTINCT x)の計算時間
- approx_time
- approx_distinct(x)の計算時間
UU数が小規模な場合には、計算時間において両者にあまり差は見られません。
4-1-3. 絶対誤差

集計したUU数を縦軸にした図(4-1-1)では、ほぼ重なっていたため、「推定UU - 真のUU」で計算した絶対誤差を縦軸にプロットしました。
4-1-4. 相対誤差

今度は、「絶対誤差 / 真のUU * 100」で計算した相対誤差を、縦軸にプロットしました。
相対誤差は最大でも4%以内に収まっています。
絶対値平均で1.6%ほどであり、3%以内に90%以上が収まっています。
4-2. 中規模検証結果
4-2-1. UU数の真値と推定値

小規模検証結果と同様です。
4-2-2. 計算時間

いくつか外れ値のようなものが含まれますが、手動で再実行したところ、外れ値前後の条件と同程度の速度でした。
基本的にUU数が増加するほど差が大きくなっており、外れ値を除いて最大で1/3まで短縮されています。
平均でも1/2まで短縮されています。
4-2-3. 絶対誤差
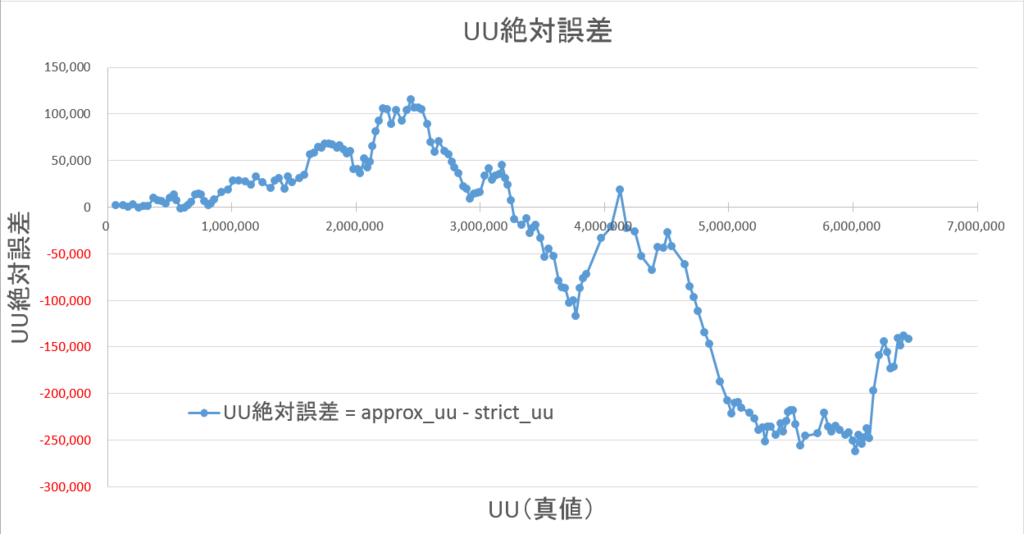
小規模検証結果と同様です。
4-2-4. 相対誤差
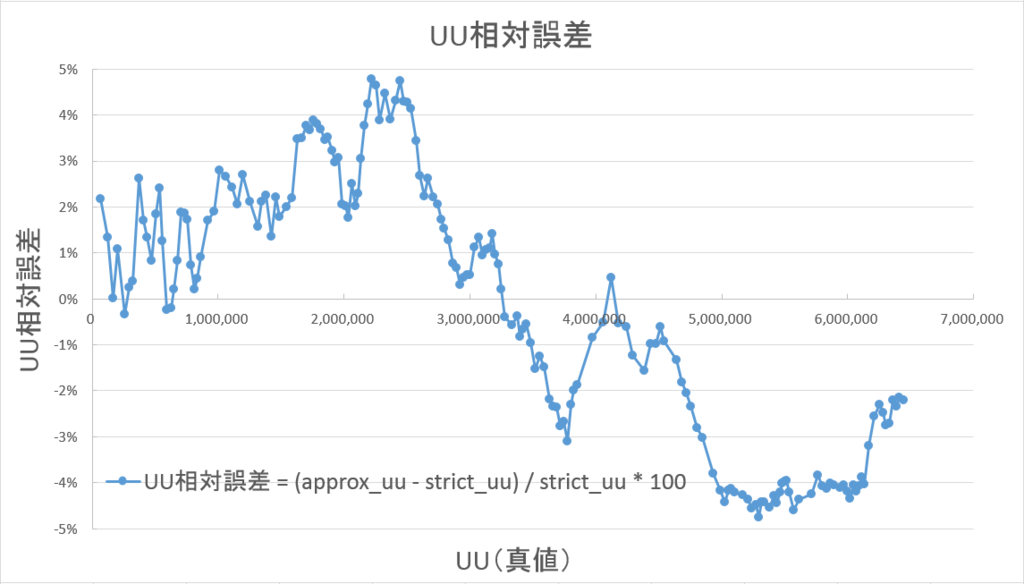
誤差は最大でも5%以内に収まっています。
絶対値平均で2.4%ほどであり、4%以内に75%以上が収まっています。
4-3. 大規模検証結果
4-3-1. UU数の真値と推定値

小規模検証結果と同様です。
4-3-2. 計算時間

中規模検証結果の図(4-3-1)と同様にいくつか外れ値のようなものが含まれますが、手動で再実行した場合は前後の条件での集計と同程度の速度でした。
こちらもUU数が増加するほど差が大きくなっており、外れ値を除いて最大で1/4まで短縮されています。
平均でも1/3まで短縮されており、中規模の場合よりも更に短縮効果が大きくなっています。
4-3-3. 絶対誤差
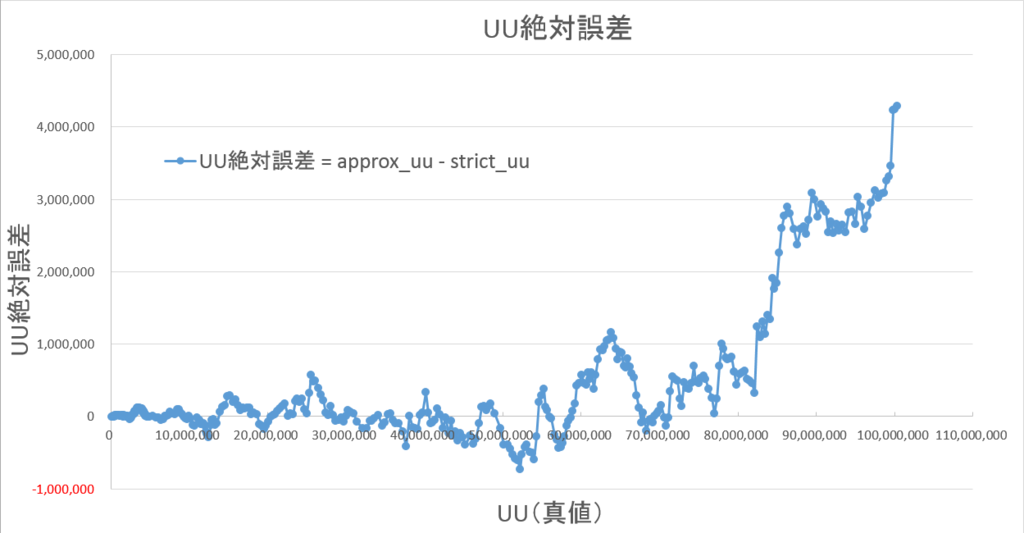
小規模検証結果と同様です。
4-3-4. 相対誤差
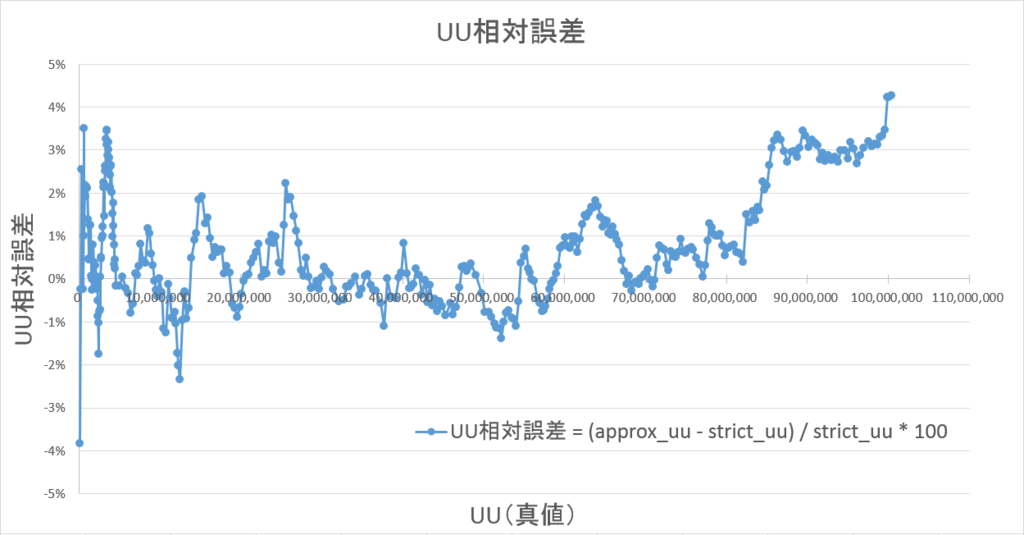
誤差は最大でも5%以内に収まっています。
絶対値平均で1%ほどであり、4%以内に99%以上が収まっています。
4-4. 検証結果考察
- 誤差はかなり小さい
- 全検証において最大でも
5%以内の相対誤差
- 全検証の絶対値平均では相対誤差1.5%程度
- 93%以上は相対誤差
- UU数が小さい場合でも誤差は小さい
- 単純なHyperLogLogだけではなくその推定値に補正をかけている?
- 全検証において最大でも
- 絶対誤差がある値を境に小さくなっていくことがある
- その前後でアルゴリズムを切り替えている?
- 基本的にはUU数が増加すると絶対誤差は増加する
- UU数の真値も増加するので相対誤差が増加するわけではない
- 大規模データに対してはかなり高速
- そもそも厳密な集計が高速な場合(数秒程度)にはあまり効果がない
- 基本的にデータが大きくなるほど計算時間の削減率は大きい
- 計算時間が1/4にまで短縮される場合もあった
5. まとめ
- 全ての検証で相対誤差
- アルゴリズム的に心配していたUU数が小さい場合も十分な精度
- かなりの高速化が期待できる
- データが大規模であるほど効果を発揮
- 個々のユーザーの情報は潰れる
- COUNT(DISTINCT x)の推定のため、ユーザーの一覧は出せない
- その集合に含まれるユーザーを特定することはできない
- COUNT(DISTINCT x)の推定のため、ユーザーの一覧は出せない
- メモリの使用量も削減
- (注)今回は高速化が主目的のため、削減量などのデータは未取得
- 毎回ランダムにサンプリングして推定するタイプではない
- 入力データが同じなら同じ結果が返ってくる
- ヘビーユーザーのような大量にログに出てくる人物に影響されない
スライド
今回のブログの内容とほぼ一致していますが、興味のある方はスライド資料もぜひご覧ください。
まとめ
今回は「実践編」として、大量ログからUU数を高速に推定するために、Prestoのapprox_distinct関数のパフォーマンス検証について、簡単にご紹介しました。
懸念していたUU数が小規模な場合についても、かなりの精度で推定できており、実用的で使いやすそうですね!
さらに、目標としていた「高速化」という点についても、データが小規模な場合は変化がありませんでしたが、データが大規模であるほど効果が大きいという結果を得ることができました。とはいえ、更に高速化できれば更に使いやすさは向上するため、引き続き高速化には取り組んでいきたいと思います。
また、Prestoはリリースのスピードが速く、この検証中にも新バージョンが公開されていました。
今後も、継続的に情報収集していくとともに、それらを当社製品のさらなる利便性向上・機能改善につなげていきたいと考えています。
こうした先進的な取り組みをぜひ自分でもやってみたいという方を、ブレインパッドでは募集しています。自分で色々なことを調べて試してみたい、触ってみたいという方におすすめです!
興味・関心のある方は、ぜひご応募ください!
www.brainpad.co.jp
データマネジメントツール「DeltaCube」に関するお問い合わせも、お待ちしております!
www.brainpad.co.jp