

こんにちは、ブレインパッド機械学習エンジニアの廣岡です。
先日、名古屋で開催していたACML(Asian Conference on Machine Leanring)に参加したので、その様子をお届けします。
はじめに
ACMLとは
機械学習のトップカンファレンスといえばNeurIPS(旧NIPS)やCVPR、ICMLなどが有名かと思いますが、ACMLは特に、アジアにおける研究者向けに開催されており、今回で11回目の開催となります。
研究に関してもレベルの高いものが多く感じました。
また、内容についても、ニューラルネットワークに関する理論解析から、弱教師あり学習やドメイン適応など実用上の問題まで、幅広い内容が取り扱われていたように感じました。
関心
個人的には、最近はコンピュータビジョンや自然言語処理などといった応用よりも、転移学習やニューラルネットワークの理論解析などやや基礎寄りな分野に興味があります。
また、ブレインパッドで仕事に取り組む上では様々な案件があるので、それらに共通するような問題にフォーカスして発表を聴こうと思いました。
1日目:チュートリアル・ワークショップ
1日目はワークショップとチュートリアルが開催されており、私は
- Tutorial2(午前): Toward Noisy Supervision: Problems, Theories, and Algorithms
- Workshop3(午後): Weakly-supervised Learning Workshop
に参加・聴講しました。
Toward Noisy Supervision: Problems, Theories, and Algorithms
教師あり学習は、教師ラベルの品質に大きく影響されます。
例えば、MNISTやCIFAR-10のような広く公開・利用されているようなデータセットは、ほとんど間違いなくラベルつけがされており、機械学習アルゴリズムによって精度よく推定が可能でしょう。
一方で実データは、アノテーションがうまくなされていない(=ノイズが加わっている)ことが想定されます。これをnoisy supervisionとして、研究されている内容を話すというワークショップでした。
こうした場合のモデルの性能を解析するためには、付与されているラベルが間違っている確率をモデル化することが必要となります。
実際に学習を行う上で、サンプルの蒸留というアイデアが取り入れられているようです。確実に分類できているサンプルのラベルは正しいものとして、学習を進めていきます。
この問題は深層学習を用いる場合にも重要です。
ここで興味深かったのは、深層学習モデルは分類が簡単なサンプルから学習するという話でした。しかし、そのまま学習を進めた場合、ノイジーサンプルにフィットしてしまい本当の性能は劣化してしまいます。
最近の研究として、Co-teachingという手法が解説されていました。
この手法は二つのニューラルネットを用意し、それぞれ損失の小さいサンプルを選び、教えあいながら学習していくというものでした。
この時学習中に予測が異なったものはラベル付けが信用できないサンプルとして扱います。結果として、ラベルノイズによる影響を抑えながら学習ができるという内容でした。
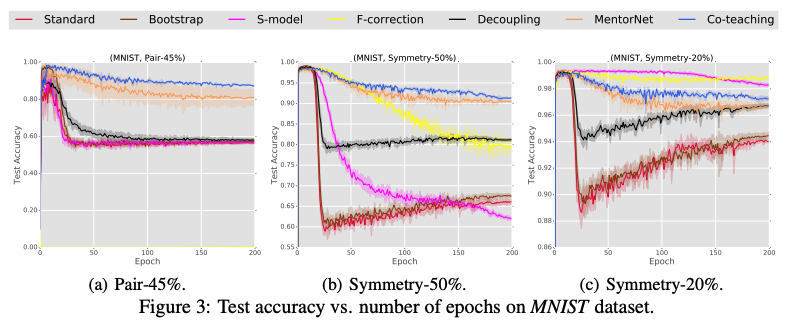
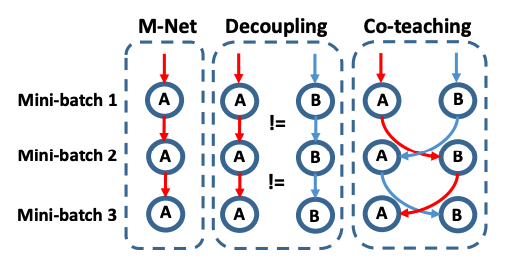
[1804.06872] Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels
会場からは、ラベルノイズの存在を想定した場合にモデルの性能をどう評価するのかという質問があり、実用上は定性的な評価も交える必要がありそうとの回答でした。
分析業務に取り組む上でも学習結果の妥当性を定性的に確認するシーンは多く、その重要性を再認識しました。
Weakly-supervised Learning Workshop
午前に聴講したnoisy-supervisionは付与されたラベルにノイズが発生している場合でしたが、weakly-supervised learning(弱教師あり学習)は少量の教師付きデータと多量の教師なしデータがある場合を想定しています。
教師付きデータの少なさは、多くの場合教師付与コストが高いことに由来すると言えるでしょう。本セッションでは医療画像や自動運転のためのデータなどが例として挙げられていました。こちらはワークショップなので、発表された内容からいくつか興味深かったものを紹介しようと思います。
Projected BNNs: Avoiding weight-space pathologies by learning latent representations of neural network weights
こちらの研究は、医療応用や自動運転の標識認識など、意思決定の重要度が高いシーンを想定していました。
これに対して、ベイズニューラルネットワークによって不確かさを折り込んだ予測をしたい、というモチベーションです。
一般的にニューラルネットワークを用いたベイズ推論は、膨大なパラメータの事後分布を扱う必要があり、現状素直に実用するのは難しいと言えます。
こちらの研究は、パラメータの空間を低次元に射影し、その低次元の空間内で推論を行うことによってベイズ推論を行うという内容でした。
Making Active Learning More Realistic
Active learning(能動学習)は、学習とデータへのラベル付けを交互に行うという枠組みです。
一度学習を行なった上でラベル付与が必要なサンプルをクエリとして選び、クエリへのラベルを獲得した上で再び学習を行います。
ここで目標となるのは、出来るだけクエリ数を減らしながら最終的なモデルの性能を向上させることです。
クエリの選び方としては、モデルの予測が不確実(発表ではconfusiongと言われていました)なサンプルを選ぶ、最悪誤差を最小化するサンプルを選ぶ、など色々な方法が提案されています。
発表ではバンディット問題としてこれらのクエリ選出方法を選ぶOSSを開発したと話しており、実際にGitHubで公開されているようです。
2日目:論文発表・特別講演
論文ピックアップ
2日目の午前中は、Deep Learningセッションを聴講しました。論文としては深層学習モデルの学習中の振る舞いに関する以下の二つが気になりました。
Gradient Descent Optimizes Over-parameterized Deep ReLU Networks
サンプルサイズよりも多いパラメータ数の深層学習モデルがなぜ汎化するのかは、現在盛んに研究されているテーマの一つです。
本研究ではゆるい仮定の下で、勾配降下法および確率的勾配降下法が訓練誤差0を達成できること、またそのために必要な各層のユニット数とパラメータ更新回数のオーダーを導出しています。
[1811.08888] Stochastic Gradient Descent Optimizes Over-parameterized Deep ReLU Networks
ResNet and Batch-normalization Improve Data Separability
こちらの研究は近年の多くの深層学習モデルで採用されるskip-connectionとbatch-normalizationが、なぜ分類問題に有効なのかを解析した論文です。
アイデアとして、分類誤差をクラス間距離とクラス内距離の距離比によって捉え直しています。直感的にも、クラス間距離が遠くクラス内距離が近ければ、うまく分類ができると考えられるでしょう。
これに対して、入力信号が伝達する際に単純な多層パーセプトロンではクラス間の角度と距離比が小さくなってしまうことを示しています。
一方でskip-connectionとbatch-normalizationを用いた場合、信号伝播時のクラス間角度と距離比の減衰を抑えることができ、結果として分類がうまく行くという内容でした。
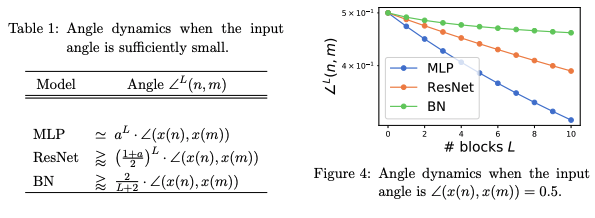
ResNet and Batch-normalization Improve Data Separability
特別講演
午後は別会場の名古屋能楽堂へ移動しました。

こちらでは招待講演として、グラフニューラルネットワーク(GNN)と深層学習モデルの圧縮に関する解説がありました。
詳細な説明は省きますが、GNNではSNSやインターネットのトラフィックなど、ノード間の関係を考慮した特徴抽出が期待できると言われていました。
また深層学習モデルの圧縮では、スパース化や量子化、低ランク近似などのアプローチがあると説明した上で、主に量子化に関する解説がありました。
ネットワークの量子化では重みが非連続になるため、これに対応した学習方法が必要であることや、LSTMなどは勾配が発散しやすいため工夫が必要であるなどといった説明がされていました。
招待講演の他に、best student paperとbest paperの二つの発表がありました。
それぞれ強化学習と変分推論の性能保証に関する内容で、非常に興味深かったです。
Best student paper: Model-Based Reinforcement Learning Exploiting State-Action Equivalence
こちらの研究は、状態と行動がどちらも離散である場合を対象としていました。
一般に状態・行動の組み合わせが増えると、ある状態である行動を取った時にどの状態に変化するかという遷移確率を網羅的に考えるのが困難になります。
これに対して、本研究では状態・行動のペアにクラスを仮定し、これを用いることで厳密なregret boundを導出していました。
実験ではこのクラスが既知・未知の両方の場合を検証しており、どちらも改善が見られたとのことでした。
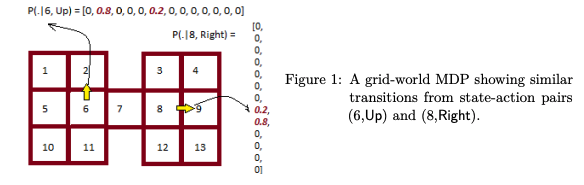
Model-Based Reinforcement Learning Exploiting State-Action Equivalence
Best paper: A Generalization Bound for Online Variational Inference
こちらの研究は、ベイズ推論におけるオンライン学習の解析を行なっています。
ベイズ推論は、データ点が一つ追加されることによるパラメータの事後分布の変化を議論しやすいというメリットがあります。
一方で、パラメータ数が多い場合には厳密なベイズ推論が難しい場合も多く、そうした場合には変分法など近似計算を用いて議論をする必要があります。
こちらでは、ベイズ推論において変分近似を用いてオンライン学習を行なった場合の、汎化性能に関する解析を行なっています。
結果として、オンラインベイズ推論において近似計算を用いた場合にも理論的な保証が与えられることを示しています。
[1904.03920] A Generalization Bound for Online Variational Inference
余談ですが、2日目には能楽堂近くの名古屋城ホテルで懇親会がありました。
道中は雨が降っていたのですが、学会運営の方々が傘を用意してくれており配慮が行き届いていると感じました。
懇親会を私は作業があったので、早めに退散してしまったのですが、こういったところで企業や大学・研究機関のつながりができると、日本の機械学習における産学連携も強まっていくだろうと思いました。
3日目:招待講演・論文発表
3日目は招待講演と、2日目と同様に研究発表のセッションがありました。
ここでは招待講演の概要と研究発表で気になった論文を紹介します。

Resource Efficient ML in 2KB of RAM
こちらの講演は、特にモバイルデバイスなど限られた計算リソースしか利用できない場合に機械学習モデルを運用するための方法について話されました。
エッジデバイス上で推論することで、応答速度やプライバシーの保護、消費電力の削減などといった恩恵が得られます。
講演ではTensorFlowの軽量版であるTFLiteや、MicrosoftのEdgeMLが紹介されていました。
具体的なモデルとしてはFastGRNNが紹介されていました。
これは普通のLSTMとほぼ同じ精度でありながら、例えばarduinoなどのデバイスでも動作するほど軽量・高速であるとのことでした。
実際に壇上ではデバイスを取り付けた杖を用いたジェスチャー認識も行われ、こうした生活がそう遠くないことを予感しました。
Visual Recognition from Limited Supervised Data
こちらでは、画像認識コンペティションであるILSVRC2012でトロント大学のチームが深層学習モデルによって目覚ましい成果を挙げたことを振り返った上で、限られた教師ありデータからどのように効果的に学習を行えるかについての講演がありました。
まず、少ない教師ありデータから効率的に学習を行う方法として、クラス間学習の話がありました。
クラス間学習では二つのクラスの画像をある割合で混ぜ合わせ、混合比を出力するように学習を進めます。
直感的にはクラスを内挿するサンプルを作ることで、モデルがより識別に有用な特徴抽出を行えるようになるとのことでした。
他にも、教師ありデータが限定されるシーンへの対応としてドメイン適応が紹介されていました。
ドメイン適応とは、教師が豊富なドメイン(人工データなど、ソースドメインと呼ぶ)で学習したモデルを、教師が少ない(または全くない)データ(自然画像など、ターゲットドメイン)に適応させる枠組みのことです。
深層学習モデルでドメイン適応を行う場合、多くの手法は敵対的学習によってソース・ターゲットドメイン間の特徴量分布を近づけるように学習を行います。
これによってドメインの違いに頑健な特徴抽出を学習し、ターゲットドメインにおける性能向上が期待できます。
一方で、特徴量分布の一致が必ずしもクラスごとの分布を一致させているわけではありません。
この問題に対して、講演では二つの分類モデルを用意し、クラスの分離境界を用いることでクラス単位でのドメイン適応を行う論文が紹介されました。
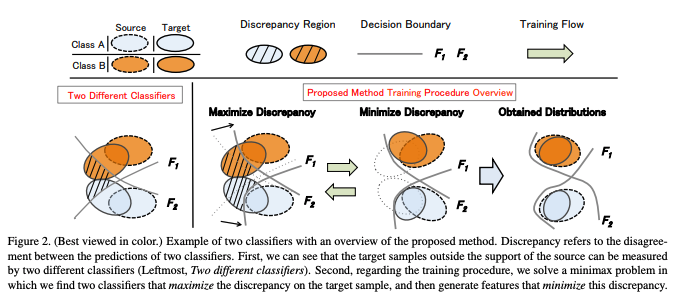
[1712.02560] Maximum Classifier Discrepancy for Unsupervised Domain Adaptation
他にも、深層生成モデルであるGANを少量データに適応させる方法についても紹介がありました。
この手法では生成器におけるバッチ統計量とシフト、バイアスパラメータのみに注目することで、深層生成モデルにおいても比較的少量のデータに対するチューニングが可能であることを示しています。

[1904.01774] Image Generation From Small Datasets via Batch Statistics Adaptation
実際は、もちろんデータ収集基盤を整備し豊富な教師ありデータを収集できるのが最善ですが、それが十分でない場合にアルゴリズム側からもアプローチがあることを認識しました。
論文ピックアップ
3日目の午後にも論文発表セッションがありました。こちらからも二つ気になった論文をご紹介します。
Canonical Soft Time Warping
二つの系列の対応をとること(アライメント)は、画像処理やバイオインフォマティクスなど様々な分野で必要とされており、canonical time warping(CTW)はその方法の一つです。
しかし、CTWの最適化は初期値によっては局所解に陥ってしまうことが知られています。
こちらの取り組みではアライメントを確率変数としてモデル化することを提案しています。
最適化はEMアルゴリズムに近い方法によって行われ、実験的に精度が向上したと報告しています。
Real-Time Tree Search with Pessimistic Scenarios
こちらはNeurIPS2018のマルチエージェント環境のゲームでの性能を競うコンペティションで優勝したモデルの論文です。
ゲームは一定時間後に爆発する爆弾を置きながら、相手より長く生き残るというものです。
他のエージェントと競うという性質上、行動の決定はリアルタイムである必要があり、また爆弾は一定時間後に爆発するためある程度先を見越した行動を選ぶ必要があります。
こちらのゲームは環境をシミュレーションできるため、木探索によって行動を選ぶことができます。
しかしステップが進むごとに想定されるシーンの組み合わせは爆発的に増えてしまうので、リアルタイムで稼働するためには想定するシーンを制限しなければいけません。
本研究では提案手法として、一定ステップ先までは通常の木探索を行い、その後は仮想的なpessimistic(悲観的)シナリオを構築しています。
これによってリアルタイムでの動作を実現しながら、多くの場合で勝利、または引き分けに持ち込むことができたとのことでした。

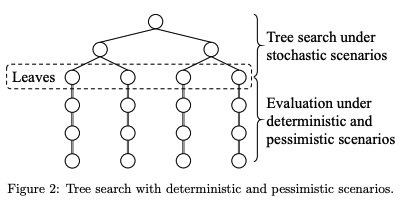
[1902.10870] Real-time tree search with pessimistic scenarios
終わりに
アジア地域にフォーカスした国際学会でしたが、口頭・ポスターのどちらも活発にディスカッションされており、私自身直接質問する機会もあり非常にためになりました。
ブレインパッドで働く上で、必ずしもこうした学会で発表されるような最先端の技術を使うわけではありません。
ですが、こうした内容にキャッチアップすることによって、自信を持って企業の課題に適した解法を提供できると感じています。
ブレインパッドではデータサイエンティストや機械学習エンジニアを積極的に募集しています。データ分析や機械学習で社会を変えたい方、新卒採用・キャリア採用ともにご応募をお待ちしています!