
こんにちは。
テクノロジー&ソフトウェア開発本部A.I.開発部の三浦です。
3月15日 (火)に早稲田大学早稲田キャンパスで行われた平成27年度データ解析コンペティションの成果報告会にて、ブレインパッド有志で参加したチーム「白金鉱業」 (名前は当社オフィスの所在地に由来)が優秀賞 (2位に相当)を受賞しました!
本ブログでは、今回のコンペティションの取り組みについてご紹介します。

●成果報告会で優秀賞受賞後に撮影した1枚
データ解析コンペティションとは
データ解析コンペティションとは、経営科学系研究部会連合協議会が主催する「データ分析の新規性」「ビジネスへの有効性」を競う、データ分析のコンペティションです。平成6年から始まり、今年で22年目を迎えました。
当社のチーム「白金鉱業」は、平成24年度より本コンペティションに参加しており、
- 平成24年度: 成果報告会優秀賞
- 平成25年度: OR学会技能賞
- 平成26年度: OR学会技能賞
と、数々の賞を受賞してきました。
本コンペティションでは、毎年異なるデータが提供され、チーム自ら分析テーマを設定し分析を行います。今年度は以下の2種類のデータが提供されました。
- データ1部門: 受付案内システムログ + POSデータ (板橋区様提供)
- データ2部門: 複数スーパーマーケットチェーンID付POSデータ (株式会社アイディーズ様提供)
両部門で118チーム, のべ700名が参加し、2015年9月から2016年3月までの半年間開催されました。 (両部門へのエントリーも可)
板橋区の受付案内システムデータについて
今回我々はエントリーする部門を選択する際に、「普段業務で触れる機会の少ないデータを分析する方が楽しいだろう」と思い、板橋区の受付案内システムのデータを選択しました。
受付案内システムとは、来庁された人に手続きに応じた番号札を発券し、その番号札をディスプレイに表示して、来庁者を窓口まで案内するシステムです。
板橋区の受付案内システムの特色として、窓口同士が連携されている点が挙げられます。この窓口連携により、複数窓口で手続きをする人に対して窓口と訪問順が記載された窓口案内書を発行し、待ち時間の短縮を実現しています。
その他にも板橋区では、窓口の混雑度が2ヶ月先までわかる混雑予想カレンダーや、現在の窓口の混雑状況が把握できるリアルタイム混雑状況など、様々なサービスを提供しています。

図.板橋区の混雑予想カレンダー(板橋区役所ホームページより)
混雑する日が×、混雑しない日が◎で表示されています
板橋区では窓口改善の理念として、
- 待ち時間の短い窓口
- 迷わずわかりやすい窓口
- 安心で快適な窓口
という3点を挙げており、参加チームはこの理念を念頭に分析を開始しました。
分析テーマの設定
本コンペティションでは、分析テーマの設定は各チームに委ねられています。
データが窓口業務に関するものであること、また我々の予選部会が日本オペレーションズ・リサーチ学会(以下、OR学会)であったことから、他チームの分析は待ち行列を用いた内容であることが想定されました。
実際に中間発表の段階では、他チームの発表はデータの基礎集計を行いつつ、
- 待ち時間の予測
- 来庁人数の予測
- 窓口配置の最適化
などを行おうとするチームが多かったように記憶しています。
我々も他のチームと同様に、利用者の利便性を考えて待ち時間の予測をすべきだと、当初は考えていました。
一般的に、待ち時間は来庁人数と窓口の職員数などに依存します。しかし、今回受領したデータは、来庁者のログはあるものの職員数のログは残されていないため、稼働窓口数の推定が必要でした。
実際の業務ではお客様へのヒアリングを重ねることで、分析に必要なお客様の業務フローを把握することができますが、本コンペティションでは、業務フローは質問表によるやり取りで把握しなければならないため、正確な業務フローの把握(待ち行列が何段になるか)や窓口数の把握が難しいことから、待ち行列を用いた待ち時間の予測は断念しました。
また、「OR学会で、待ち行列を用いた分析の勝負をしても面白くない」という意見もチーム内にあり、我々は分析テーマとして来庁人数の予測を設定し、混雑予想カレンダーの精緻化を行いました。
混雑予想カレンダーは、各窓口における混雑状況を、担当者の方が前年度の実績をもとに予想したもので、予め2ヶ月先まで提出されています。この混雑予想カレンダーを機械学習を用いた手法で、日にちベースから時間帯ベースまでに拡張して予測できないかと考えました。
分析における工夫
分析結果については詳細をお伝えできないのですが、分析で工夫したことは以下の3点です。
- 業務上活用できる予測モデル
- 予測精度の向上
- わかりやすい可視化
まず1.についてですが、予測を行う際には、その予測モデルが業務に活用できることが必要です。今回は、受領したデータの前半8ヶ月分を用いてモデルを学習し、後半1ヶ月分で予測およびモデルの評価を行いました。
雨の日は来庁人数が減るなど、天候が来庁人数に影響を与えることは把握していましたが、過去の時点で1ヶ月先までの天候予測をしているデータは存在しないため、天候データを予測モデルに考慮することはできませんでした。同様に業務で使うことを考えると、当日などのデータを使うこともできません。
このように、実際に業務で活用することまでを考慮し、モデルを構築したチームはあまりいなかったように思います。
次に2.の予測精度の向上に関してですが、モデル構築の際には様々なモデルと特徴量の組み合わせについて考慮しました。
モデルとしては、線形回帰・SVR・ランダムフォレスト・Elastic Netを試しました。特徴量としては曜日・時間帯を始めとし、閉庁日翌日フラグ・長期休暇フラグ・大安フラグなど、来庁人数に影響を及ぼすと考えられる特徴量を多数作成しました。
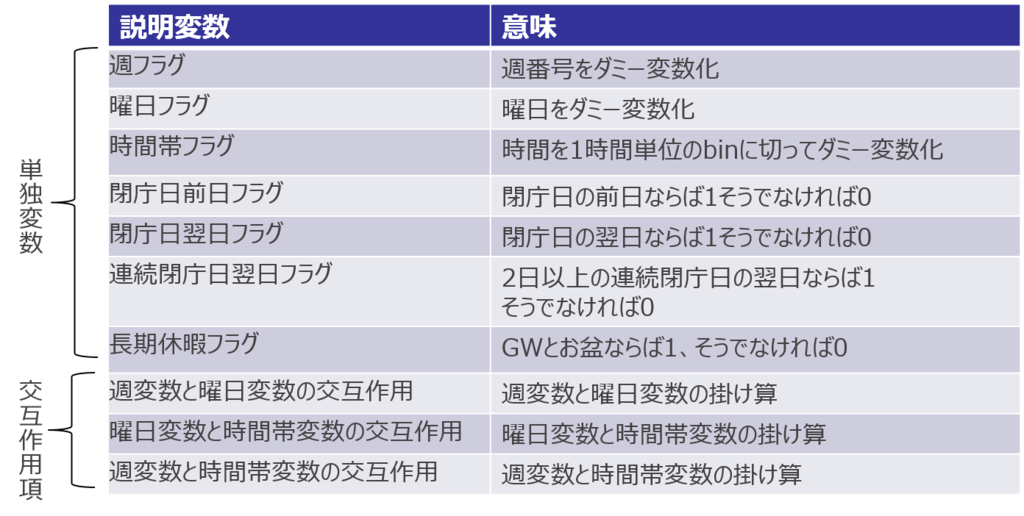
図. 最終的に用いた説明変数
結果として、曜日と時間帯の交互作用を特徴量として取り入れた、Elastic Netが最も良い結果となりました。Elastic Netとは、L1ノルムの正則化を行うLasso回帰と、L2ノルムの正則化を行うRidge回帰を線形結合したモデルで、次式で表されます。

板橋区では火曜日は遅い時間まで開庁しており、この時間帯の来庁者も多いのですが、一方で17時台の来庁者は減ります。しかし他の曜日では、こうした特徴は観測されません。
間接的に曜日と時間帯の交互作用を考慮するランダムフォレストなどよりも、明示的に特徴を取り入れたElastic Netの結果の方が良かったということは、興味深い結果と言えます。
最後に3.の可視化についてですが、お客様に構築した予測モデルの説明をする際に、RMSEやMAEなどの評価指標だけで説明することは、あまり説得力のあるものではありません。
今回我々は、Pythonの可視化ライブラリであるSeabornのFacetGridを応用し、予測した来庁人数の時系列をカレンダー形式で表示しました。
図. SeabornのFacetGridの例 (SeabornのGalleryより)
実際には1日単位で週、曜日を揃えプロットしました
単純な時系列表示ではなくカレンダー形式で時系列を表示することで、構築した予測モデルが曜日や時間帯の特徴を、パターンとしてきちんと再現できていることがわかりました。一方で5連休の翌日や、台風の日には予測が外れていることを示し、RMSEだけでは把握できない時系列の特徴を説明することができたと思います。
また予測した来庁人数を、現在の混雑予想カレンダーに反映させるイメージを提供しました。

図. 混雑予想カレンダーの精緻化イメージ
クリックするとポップアップで開くことを想定
これらの可視化の工夫により、予測結果を聴衆の皆さんに、わかりやすく伝えることができたのではないかと思っています。
本コンペティションへの取り組み方
分析は、ブレインパッドの新卒1、2年目を中心とする有志メンバーにて取り組みました。
業務が終了してから分析を行い、毎週1回程度集まって結果を共有するというスタイルをとりました。
分析にあたっては担当をデータの前処理、予測モデルの検討、特徴量の作成、結果の可視化などに振り分けることで、1人に作業が集中してしまわず、メンバーで分散して作業できた点は良かったです。 また新卒1年目社員と2年目社員の、交流を深める場にもなりました。
感想
受賞後に審査員にお話を伺ったところ、「丁寧な分析で、特にデータ提供者である板橋区の皆さまから評価が高かった」とのことでした。普段から、お客様の課題を考え、お客様目線で分析を行う、我々の強みが発揮できた結果ではないかと思います。
また、区役所のデータという、普段の業務で扱うことがあまりないデータの分析は、楽しくとても有意義でした。今後も新しい分野・データの分析に挑戦し、新たな価値を出し続けていきたいと思います。
最後にはなりますが、データを提供してくださった板橋区の関係者の皆さま、貴重な分析の機会を与えてくださったデータ解析コンペティション事務局の皆さまへお礼を申し上げたいと思います。
本当にありがとうございました。
「来年はぜひ自分も『白金鉱業』のメンバーとしてデータ解析コンペティションに参加してみたい!」と思った皆さまの、採用エントリーをお待ちしております。ぜひご応募ください!
www.brainpad.co.jp